- Tail utilization is a major system subject and a significant component in overload-related failures and low compute utilization.
- The tail utilization optimizations at Meta have had a profound affect on mannequin serving capability footprint and reliability.
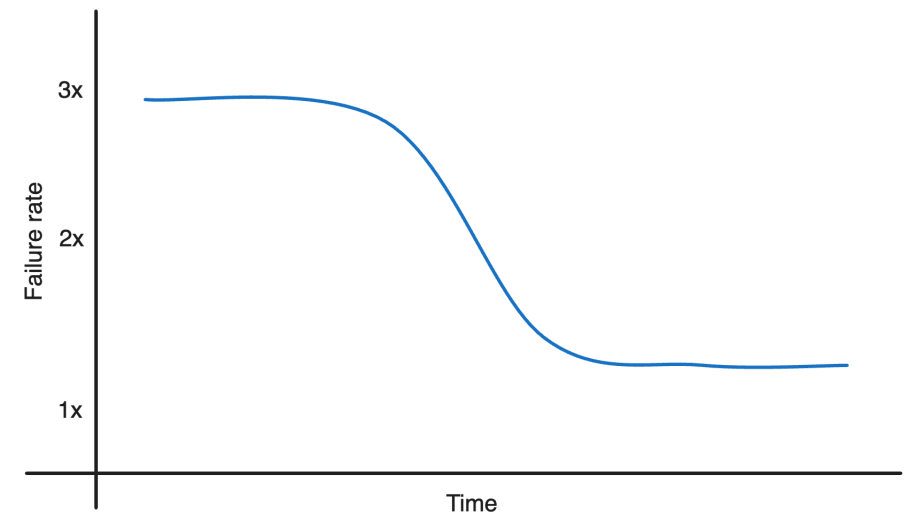
- Failure charges, that are largely timeout errors, have been lowered by two-thirds; the compute footprint delivered 35% extra work for a similar quantity of sources; and p99 latency was lower in half.
The inference platforms that serve the delicate machine studying fashions utilized by Meta’s advertisements supply system require vital infrastructure capability throughout CPUs, GPUs, storage, networking, and databases. Bettering tail utilization – the utilization degree of the highest 5% of the servers when ranked by utilization– inside our infrastructure is crucial to function our fleet effectively and sustainably.
With the rising complexity and computational depth of those fashions, in addition to the strict latency and throughput necessities to ship advertisements, we’ve carried out system optimizations and greatest practices to deal with tail utilization. The options we’ve carried out for our advertisements inference service have positively impacted compute utilization in our advertisements fleet in a number of methods, together with rising work output by 35 p.c with out further sources, lowering timeout error charges by two-thirds, and lowering tail latency at p99 by half.
How Meta’s advertisements mannequin inference service works
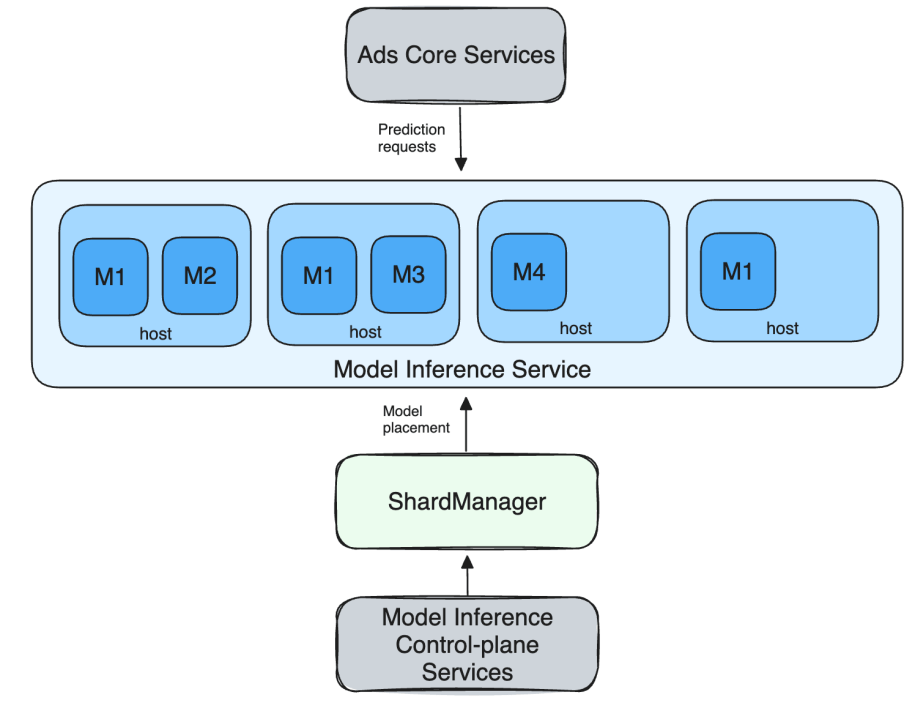
When putting an advert, consumer requests are routed to the inference service to get predictions. A single request from a consumer sometimes ends in a number of mannequin inferences being requested, relying on experiment setup, web page sort, and advert attributes. That is proven under in determine 1 as a request from the advertisements core companies to the mannequin inference service. The precise request movement is extra complicated however for the aim of this put up, the under schematic mannequin ought to serve properly.
The inference service leverages Meta infrastructure capabilities resembling ServiceRouter for service discovery, load balancing, and different reliability options. The service is ready up as a sharded service the place every mannequin is a shard and a number of fashions are hosted in a single host of a job that spans a number of hosts.
That is supported by Meta’s sharding service, Shard Manager, a common infrastructure resolution that facilitates environment friendly improvement and operation of dependable sharded purposes. Meta’s promoting staff leverages Shard Supervisor’sload balancing and shard scaling capabilities to successfully deal with shards throughout heterogeneous {hardware}.
Challenges of load balancing
There are two approaches to load balancing:
- Routing load balancing – load balancing throughout replicas of a single mannequin. We use ServiceRouter to allow routing based mostly load balancing.
- Placement load balancing – balancing load on hosts by transferring replicas of a mannequin throughout hosts.
Elementary ideas like reproduction estimation, snapshot transition and multi-service deployments are key features of mannequin productionisation that make load balancing on this setting a fancy downside.
Duplicate estimation
When a brand new model of the mannequin enters the system, the variety of replicas wanted for the brand new mannequin model is estimated based mostly on historic information of the reproduction utilization of the mannequin.
Snapshot transition
Adverts fashions are repeatedly up to date to enhance their efficiency. The advertisements inference system then transitions visitors from the older mannequin to the brand new model. Up to date and refreshed fashions get a brand new snapshot ID. Snapshot transition is the mechanism by which the refreshed mannequin replaces the present mannequin serving manufacturing visitors.
Multi-service deployment
Fashions are deployed to a number of service tiers to make the most of {hardware} heterogeneity and elastic capacity.
Why is tail utilization an issue?
Tail utilization is an issue as a result of because the variety of requests will increase, servers that contribute to excessive tail utilization turn into overloaded and fail, in the end affecting our service degree agreements (SLAs). Consequently, the additional headroom or buffer wanted to deal with elevated visitors is immediately decided by the tail utilization.
That is difficult as a result of it results in overallocation of capability for the service. If demand will increase, capability headroom is critical in constrained servers to take care of service ranges when accommodating new demand. Since capability is uniformly added to all servers in a cluster, producing headroom in constrained servers entails including considerably extra capability than required for headroom.
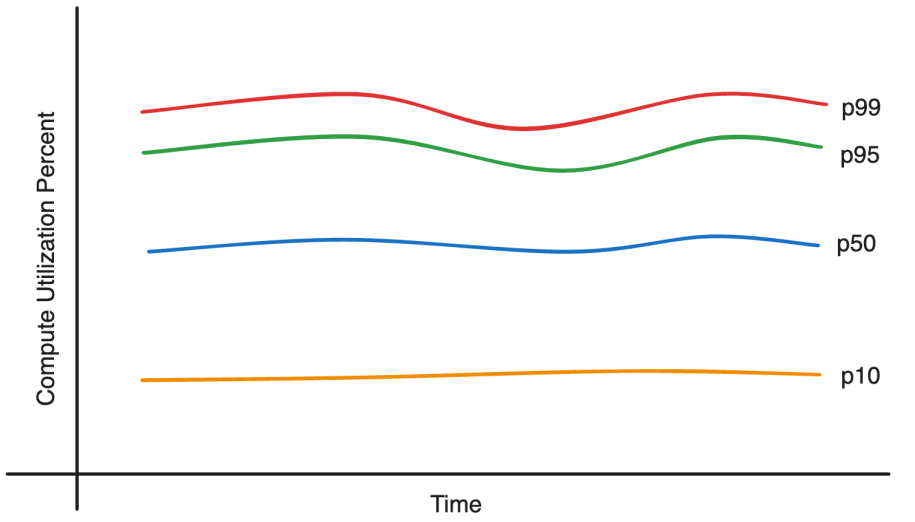
As well as, tail utilization for many constrained servers grows sooner than decrease percentile utilization because of the non linear relationship between visitors improve and utilization. That is the rationale why extra capability is required even whereas the system is below utilized on common.
Making the utilization distribution tighter throughout the fleet unlocks capability inside servers operating at low utilization, i.e. the fleet can assist extra requests and mannequin launches whereas sustaining SLAs.
How we optimized tail utilization
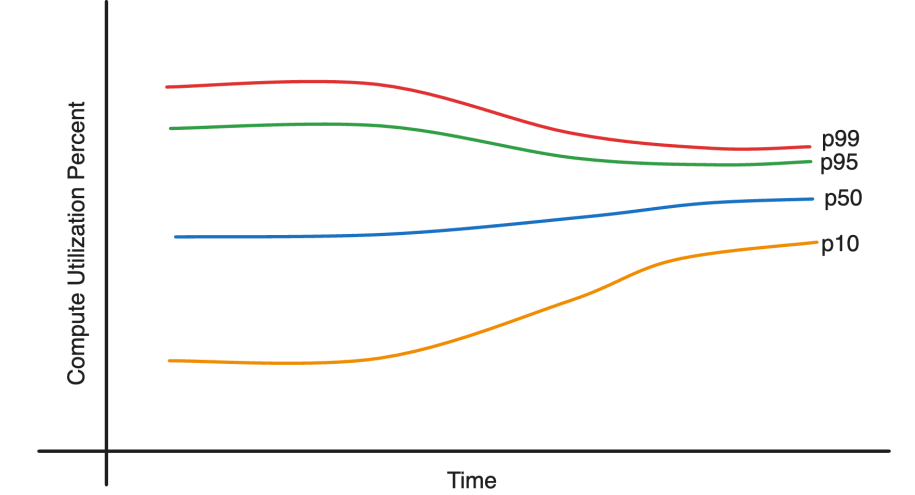
The carried out resolution includes a category of technical optimizations that try to steadiness the aims of enhancing utilization and lowering error price and latency.
The enhancements made the utilization distribution tighter. This created the flexibility to maneuver work from crunched servers to low utilization servers and take in elevated demand. In consequence, the system has been in a position to take in as much as 35% load improve with no further capability.
The reliability additionally improved, lowering the timeout error price by two-thirds and reducing latency by half.
The answer concerned two approaches:
- Tuning load balancing mechanisms
- Making system degree modifications in mannequin productionisation.
The primary method is properly understood within the trade. The second required vital trial, testing, and nuanced execution.
Tuning load balancing mechanisms
The facility of two selections
The service mesh, ServiceRouter, gives detailed instrumentation that permits a greater understanding of the load balancing traits. Particularly related to tail utilization is suboptimal load balancing due to load staleness. To deal with this we leveraged the power of two choices in a randomized load balancing mechanism. This algorithm requires load information from the servers. This telemetry is collected both by polling – question server load earlier than request dispatch; or by load-header – piggyback on response.
Polling gives contemporary load, whereas it provides a further hop, however on the opposite facet, load-header ends in studying stale load. Load staleness is a major subject for giant companies with substantial purchasers. Any error right here attributable to staleness would lead to random load balancing. For polling, given the inference request is computationally costly, the overhead was discovered to be negligible. Utilizing polling improved tail utilization noticeably as a result of closely loaded hosts have been actively prevented. This method labored very properly particularly for inference requests better than 10s of milliseconds.
ServiceRouter gives numerous tuning load-balancing capabilities. We examined many of those strategies, together with the variety of selections for server choice (i.e., energy of ok as a substitute of two), backup request configuration, and hardware-specific routing weights.
These modifications provided marginal enhancements. CPU utilization as load-counter was particularly insightful. Whereas it’s intuitive to steadiness based mostly on CPU utilization, it turned out to be not helpful as a result of: CPU utilization is aggregated over some time frame versus the necessity for fast load data on this case; and excellent energetic duties ready on I/O weren’t taken under consideration appropriately.
Placement load balancing
Placement load balancing helped so much. Given the variety in mannequin useful resource demand traits and machine useful resource provide, there may be vital variance in server utilization. There is a chance to make the utilization distribution tighter by tuning the Shard Supervisor load balancing configurations, resembling load bands, thresholds, and balancing frequency. The essential tuning above helped and offered huge positive aspects. It additionally uncovered a deeper downside like spiky tail utilization, which was hidden behind the excessive tail utilization and was fastened as soon as recognized .
System degree modifications
There wasn’t a single vital trigger for the utilization variance and a number of other intriguing points emerged amongst them that provided priceless insights into the system traits.
Reminiscence bandwidth
CPU spikes have been noticed when new replicas, positioned on hosts already internet hosting different fashions, started serving visitors. Ideally, this could not occur as a result of Shard Supervisor ought to solely place a reproduction when the useful resource necessities are met. Upon inspecting the spike sample, the staff found that the stall cycles have been rising considerably. Utilizing dynolog perf instrumentations, we decided that reminiscence latency was rising as properly, which aligned with reminiscence latency benchmarks.
Reminiscence latency begins to extend exponentially at round 65-70% utilization. It seems to be a rise in CPU utilization, however the precise subject was that the CPU was stalling. The answer concerned contemplating reminiscence bandwidth as a useful resource throughout reproduction placement in Shard Supervisor.
ServiceRouter and Shard Supervisor expectation mismatch
There’s a service management airplane part referred to as ReplicaEstimator that performs reproduction depend estimation for a mannequin. When ReplicaEstimator performs this estimation, the expectation is that every reproduction roughly receives the identical quantity of visitors. Shard Supervisor additionally works below this assumption that replicas of the identical mannequin will roughly be equal of their useful resource utilization on a number. Shard Supervisor load balancing additionally assumes this property. There are additionally circumstances the place Shard Supervisor makes use of load data from different replicas if load fetch fails. So ReplicaEstimator and Shard Supervisor share the identical expectation that every reproduction will find yourself doing roughly the identical quantity of labor.
ServiceRouter employs the default load counter, which encompasses each energetic and queued excellent requests on a number. Typically, this works fantastic when there is just one reproduction per host and they’re anticipated to obtain the identical quantity of load. Nonetheless, this assumption is damaged attributable to multi-tenancy, leading to every host probably having totally different fashions and excellent requests on a number can’t be used to match load as it could possibly differ tremendously. For instance, two hosts serving the identical mannequin might have fully totally different load metrics resulting in vital CPU imbalance points.
The imbalance of reproduction load created due to the host degree consolidated load counter violates Shard Supervisor and ReplicaEstimator expectations. A easy and stylish resolution to this downside is a per-model load counter. If every mannequin have been to reveal a load counter based mostly by itself load on the server, ServiceRouter will find yourself balancing load throughout mannequin replicas, and Shard Manger will find yourself extra precisely balancing hosts. Duplicate estimation additionally finally ends up being extra correct. All expectations are aligned.
Help for this was added to the prediction consumer by explicitly setting the load counter per mannequin consumer and exposing applicable per mannequin load metric on the server facet. The mannequin reproduction load distribution as anticipated turned a lot tighter with a per-model load counter and helps with the issues mentioned above.
However this additionally offered some challenges. Enabling per-model load counter modifications the load distribution instantaneously, inflicting spikes till Shard Supervisor catches up and rebalances. The staff constructed a mechanism to make the transition clean by progressively rolling out the load counter change to the consumer. Then there are fashions with low load that find yourself having per-model load counter values of ‘0’, making it primarily random. Within the default load counter configuration, such fashions find yourself utilizing the host degree load as a superb proxy to determine which server to ship the request to.
“Excellent examples CPU” was essentially the most promising load counter amongst many who have been examined. It’s the estimated whole CPU time spent on energetic requests, and higher represents the price of excellent work. The counter is normalized by the variety of cores to account for machine heterogeneity.
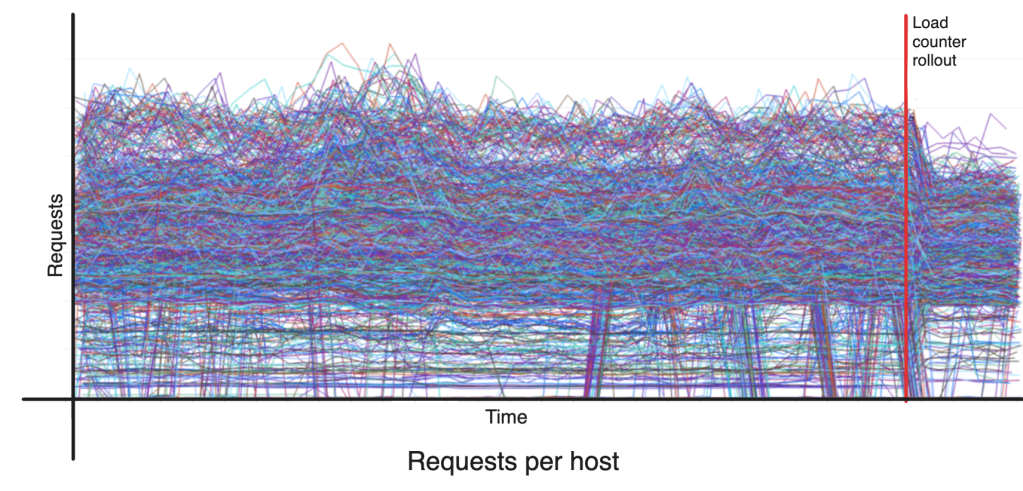
Snapshot transition
Some advertisements fashions are retrained extra continuously than others. Discounting real-time up to date fashions, nearly all of the fashions contain transitioning visitors from a earlier mannequin snapshot to the brand new mannequin snapshot. Snapshot transition is a serious disruption to a balanced system, particularly when the transitioning fashions have a lot of replicas.
Throughout peak visitors, snapshot transition can have a major affect on utilization. Determine 6 under illustrates the difficulty. The snapshot transition of enormous fashions throughout a crunched time causes utilization to be very unbalanced till Shard Supervisor is ready to deliver it again in steadiness. This takes a couple of load balancing runs as a result of the position of the brand new mannequin throughout peak visitors finally ends up violating CPU delicate thresholds. The issue of load counters, as mentioned earlier, additional complicates Shard Supervisor’s means to resolve points.
To mitigate this subject, the staff added the snapshot transition price range functionality. This permits for snapshot transitions to happen solely when useful resource utilization is under a configured threshold. The trade-off right here is between snapshot staleness and failure price. Quick scale down of outdated snapshots helped decrease the overhead of snapshot staleness whereas sustaining decrease failure charges.
Cross-service load balancing
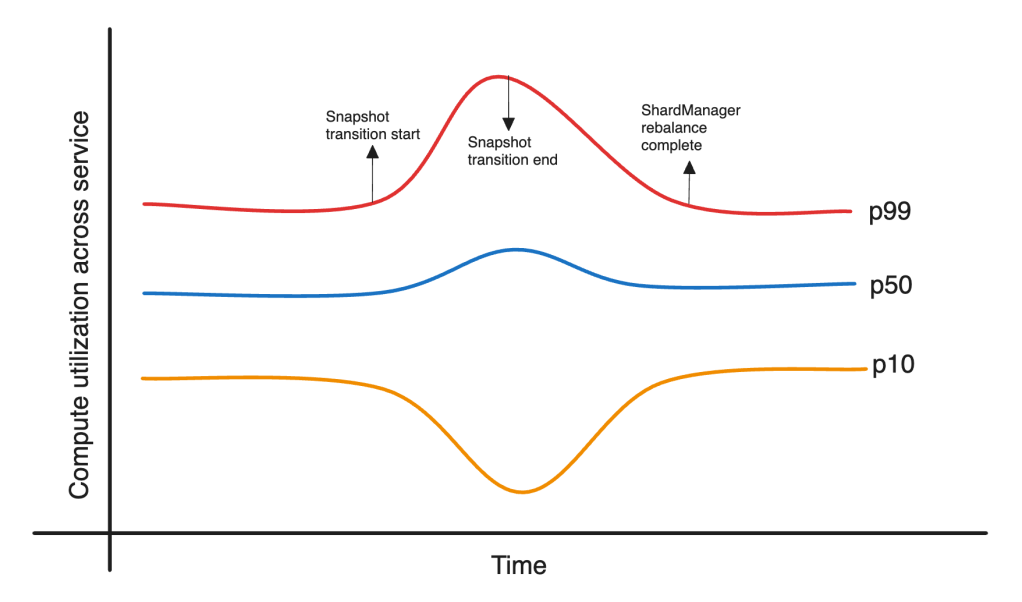
After optimizing load balancing inside a single service, the following step was to increase this to a number of companies. Every regional mannequin inference service is made up of a number of sub-services relying on {hardware} sort and capability swimming pools – guaranteed and elastic pools. We modified the calculation to the compute capability of the hosts as a substitute of the host quantity. This helped with a extra balanced load throughout tiers.
Sure {hardware} sorts are extra loaded than others. Provided that purchasers preserve separate connections to those tiers, ServiceRouter load balancing, which performs balancing inside tiers, didn’t assist. Given the manufacturing setup, it was non-trivial to place all these tiers behind a single dad or mum tier. Subsequently, the staff added a small utilization balancing suggestions controller to regulate visitors routing percentages and obtain steadiness between these tiers. Determine 7 exhibits an instance of this being rolled out.

Duplicate estimation and predictive scaling
Shard Supervisor employs a reactive method to load by scaling up replicas in response to a load improve. This meant elevated error charges throughout the time replicas have been scaled up and have become prepared. That is exacerbated by the truth that replicas with larger utilization are extra vulnerable to utilization spikes given the non-linear relationship between queries per second (QPS) and utilization. So as to add to this, when auto-scaling kicks in, it responds to a a lot bigger CPU requirement and ends in over-replication. We designed a easy predictive reproduction estimation system for the fashions that predicts future useful resource utilization based mostly on present and previous utilization patterns as much as two hours prematurely. This method yielded vital enhancements in failure price throughout peak durations.
Subsequent steps
The following step in our journey is to undertake our learnings round tail utilization to new system architectures and platforms. For instance, we’re actively working to use the utilizations mentioned right here to IPnext, Meta’s next-generation unified platform for managing the complete lifecycle of machine studying mannequin deployments, from publishing to serving. IPnext’s modular design allows us to assist numerous mannequin architectures (e.g., for rating or GenAI purposes) by a single platform spanning a number of information middle areas. Optimizing tail utilization inside IPnext thereby delivering these advantages to a broader vary of increasing machine studying inference use circumstances at Meta.











{kind=link}