AI performs a elementary position in creating invaluable connections between individuals and advertisers inside Meta’s household of apps. Meta’s advert advice engine, powered by deep learning recommendation models (DLRMs), has been instrumental in delivering customized advertisements to individuals. Key to this success was incorporating hundreds of human-engineered indicators or options within the DLRM-based advice system.
Regardless of coaching on huge quantities of information, there are limitations to present DLRM-based advertisements suggestions with handbook characteristic engineering because of the incapability of DLRMs to leverage sequential info from individuals’s expertise information. To raised seize the experiential conduct, the advertisements advice fashions have undergone foundational transformations alongside two dimensions:
- Occasion-based studying: studying representations straight from an individual’s engagement and conversion occasions somewhat than conventional human-engineered options.
- Studying from sequences: creating new sequence studying architectures to exchange conventional DLRM neural community architectures.
By incorporating these developments from the fields of pure language understanding and pc imaginative and prescient, Meta’s next-generation advertisements advice engine addresses the restrictions of conventional DLRMs, leading to extra related advertisements for individuals, greater worth for advertisers, and higher infrastructure effectivity.
These improvements have enabled our advertisements system to develop a deeper understanding of individuals’s conduct earlier than and after changing on an advert, enabling us to deduce the subsequent set of related advertisements. Since launch, the brand new advertisements advice system has improved advertisements prediction accuracy – resulting in greater worth for advertisers and 2-4% extra conversions on choose segments.
The bounds of DLRMs for advertisements suggestions
Meta’s DLRMs for customized advertisements depend on a wide selection of indicators to know individuals’s buy intent and preferences. DLRMs have revolutionized studying from sparse features, which seize an individual’s interactions on entities like Fb pages, which have huge cardinalities usually within the billions. The success of DLRMs is based on their potential to be taught generalizable, excessive dimensional representations, i.e., embeddings from sparse options.
To leverage tens of hundreds of such options, numerous methods are employed to mix options, rework intermediate representations, and compose the ultimate outputs. Additional, sparse options are constructed by aggregating attributes throughout an individual’s actions over numerous time home windows with totally different information sources and aggregation schemes.
Some examples of legacy sparse options thus engineered could be:
- Advertisements that an individual clicked within the final N days → [Ad-id1, Ad-id2, Ad-id3, …, Ad-idN]
- Fb pages an individual visited prior to now M days with a rating of what number of visits on every web page → [(Page-id1, 45), (Page-id2, 30), (Page-id3, 8), …]
Human-engineered sparse options, as described above, have been a cornerstone for customized suggestions with DLRMs for a number of years. However this strategy has limitations:
- Lack of sequential info: Sequence info, i.e., the order of an individual’s occasions, can present invaluable insights for higher advertisements suggestions related to an individual’s conduct. Sparse characteristic aggregations lose the sequential info in an individual’s journeys.
- Lack of granular info: Fantastic-grained info like collocation of attributes in the identical occasion is misplaced as options are aggregated throughout occasions.
- Reliance on human instinct: Human instinct is unlikely to acknowledge non-intuitive, advanced interactions and patterns from huge portions of information.
- Redundant characteristic area: A number of variants of options get created with totally different aggregation schemes. Although offering incremental worth, overlapping aggregations improve compute and storage prices and make characteristic administration cumbersome.
Individuals’s pursuits evolve over time with repeatedly evolving and dynamic intents. Such complexities are exhausting to mannequin with handcrafted options. Modeling these inter-dynamics helps obtain a deeper understanding of an individual’s conduct over time for higher advert suggestions.
A paradigm shift with studying from sequences for advice techniques
Meta’s new system for advertisements suggestions makes use of sequence studying at its core. This necessitated an entire redesign of the advertisements suggestions system throughout information storage, characteristic enter codecs, and mannequin structure. The redesign required constructing a brand new people-centric infrastructure, coaching and serving optimization for state-of-the-art sequence studying architectures, and mannequin/system codesign for environment friendly scaling.
Occasion-based options
Occasion-based options (EBFs) are the constructing blocks for the brand new sequence studying fashions. EBFs – an improve to conventional options – standardizes heterogeneous inputs to sequence studying fashions alongside three dimensions:
- Occasion streams: the info stream for an EBF, e.g. the sequence of latest advertisements individuals engaged with or the sequence of pages individuals preferred.
- Sequence size defines what number of latest occasions are integrated from every stream and is decided by the significance of every stream.
- Occasion Info: captures semantic and contextual details about every occasion within the stream such because the advert class an individual engaged with and the timestamp of the occasion.
Every EBF is a single coherent object that captures all key details about an occasion. EBFs permit us to include wealthy info and scale inputs systematically. EBF sequences change legacy sparse options as the primary inputs to the advice fashions. When mixed with occasion fashions described beneath, EBFs have ushered in a departure from human-engineered characteristic aggregations.
Sequence modeling with EBFs
An occasion mannequin synthesizes occasion embeddings from occasion attributes. It learns embeddings for every attribute and makes use of linear compression to summarize them right into a single occasion attributed-based embedding. Occasions are timestamp encoded to seize their recency and temporal order. The occasion mannequin combines timestamp encoding with the synthesized occasion attribute-based embedding to provide the ultimate event-level illustration – thus translating an EBF sequence into an occasion embedding sequence.
That is akin to how language fashions use embeddings to symbolize phrases. The distinction is that EBFs have a vocabulary that’s many orders of magnitude bigger than a pure language as a result of they arrive from heterogeneous occasion streams and embody thousands and thousands of entities.
The occasion embeddings from the occasion mannequin are then fed into the sequence mannequin on the heart of the next-generation advertisements advice system. The occasion sequence mannequin is an individual degree occasion summarization mannequin that consumes sequential occasion embeddings. It makes use of state-of-the-art consideration mechanisms to synthesize the occasion embeddings to a predefined variety of embeddings which are keyed by the advert to be ranked. With methods like multi-headed consideration pooling, the complexity of the self-attention module is lowered from O(N*N) to O(M*N) . M is a tunable parameter and N is the utmost occasion sequence size.
The next determine illustrates the variations between DLRMs with a human-engineered options paradigm (left) and the sequence modeling paradigm with EBFs (proper) from an individual’s occasion circulation perspective.
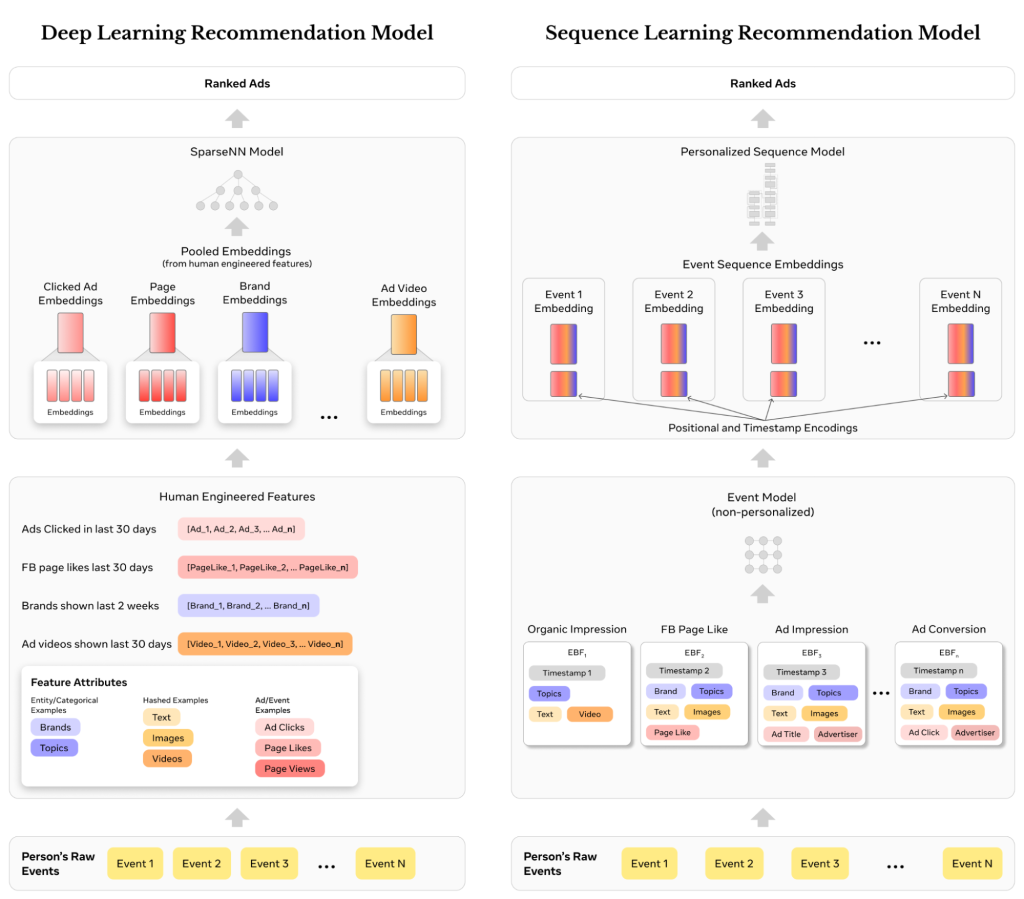
Scaling the brand new sequence studying paradigm
Following the redesign to shift from sparse characteristic studying to event-based sequence studying, the subsequent focus was scaling throughout two domains — scaling the sequence studying structure and scaling occasion sequences to be longer and richer.
Scaling sequence studying architectures
A customized transformer structure that comes with advanced characteristic encoding schemes to completely mannequin sequential info was developed to allow quicker exploration and adoption of state-of-the-art methods for advice techniques. The principle problem with this architectural strategy is attaining the efficiency and effectivity necessities for manufacturing. A request to Meta’s advertisements advice system has to rank hundreds of advertisements in a couple of hundred milliseconds.
To scale illustration studying for greater constancy, the present sum pooling strategy was changed with a brand new structure that realized characteristic interactions from unpooled embeddings. Whereas the prior system primarily based on aggregated options was extremely optimized for mounted size embeddings which are pooled by easy strategies like averaging, sequence studying introduces new challenges as a result of totally different individuals have totally different occasion lengths. Longer variable size occasion sequences, represented by jagged embedding tensors and unpooled embeddings, end in bigger compute and communication prices with greater variance.
This problem of rising prices is addressed by adopting {hardware} codesign improvements for supporting jagged tensors, particularly:
- Native PyTorch capabilities to assist Jagged tensors.
- Kernel-level optimization for processing Jagged tensors on GPUs.
- A Jagged Flash Attention module to assist Flash Consideration on Jagged tensors.
Scaling with longer, richer sequences
Meta’s next-generation advice system’s potential to be taught straight from occasion sequences to higher perceive individuals’s preferences is additional enhanced with longer sequences and richer occasion attributes.
Sequence scaling entailed:
- Scaling with longer sequences: Growing sequence lengths offers deeper insights and context about an individual’s pursuits. Methods like multi-precision quantization and value-based sampling methods are used to effectively scale sequence size.
- Scaling with richer semantics: EBFs allow us to seize richer semantic indicators about every occasion e.g. by multimodal content material embeddings. Custom-made vector quantization methods are used to effectively encode the embedding attributes of every occasion. This yields a extra informative illustration of the ultimate occasion embedding.
The impression and way forward for sequence studying
The occasion sequence studying paradigm has been extensively adopted throughout Meta’s advertisements techniques, leading to features in advert relevance and efficiency, extra environment friendly infrastructure, and accelerated analysis velocity. Coupled with our deal with superior transformer architectures, occasion sequence studying has reshaped Meta’s strategy to advertisements advice techniques.
Going ahead, the main focus shall be on additional scaling occasion sequences by 100X, creating extra environment friendly sequence modeling architectures like linear consideration and state area fashions, key-value (KV) cache optimization, and multimodal enrichment of occasion sequences.
Acknowledgements
We wish to thank Neeraj Bhatia, Zhirong Chen, Parshva Doshi, Jonathan Herbach, Yuxi Hu, Abha Jain, Kun Jiang, Santanu Kolay, Boyang Li, Hong Li, Paolo Massimi, Sandeep Pandey, Dinesh Ramasamy, Ketan Singh, Doris Wang, Rengan Xu, Junjie Yang, and the whole occasion sequence studying group concerned within the growth and productionization of the next-generation sequencing learning-based advertisements advice system.











{kind=link}