- We’re sharing particulars about Glean, Meta’s open supply system for accumulating, deriving, and dealing with info about supply code.
- On this weblog submit we’ll discuss why a system like Glean is necessary, clarify the rationale for Glean’s design, and run by way of a number of the methods we’re utilizing Glean to supercharge our developer tooling at Meta.
In August 2021 we open-sourced our code indexing system Glean. Glean collects details about supply code and gives it to developer instruments by way of an environment friendly and versatile question language. We use Glean extensively inside Meta to energy a variety of developer instruments together with code shopping, code search, and documentation era.
Code Indexing
Many instruments that builders use depend on info extracted from the code they’re engaged on. For instance:
- Code navigation (“Go to definition”) in an IDE or a code browser;
- Code search;
- Mechanically-generated documentation;
- Code evaluation instruments, comparable to lifeless code detection or linting.
The job of accumulating info from code is usually referred to as code indexing. A code indexing system’s job is to effectively reply the questions your instruments must ask, comparable to, “The place is the definition of MyClass?” or “Which features are outlined in myfile.cpp?”
An IDE will usually do indexing as wanted, while you load a brand new file or mission for instance. However the bigger your codebase, the extra necessary it turns into to do code indexing forward of time. For big tasks it turns into impractical to have the IDE course of all of the code of your mission at startup and, relying on what language you’re utilizing, that time could come earlier or later: C++ particularly is problematic as a result of lengthy compile instances.
Furthermore, with a bigger codebase and plenty of builders engaged on it, it is sensible to have a shared centralized indexing system in order that we don’t repeat the work of indexing on each developer’s machine. And because the knowledge produced by indexing can develop into giant, we wish to make it accessible over the community by way of a question interface reasonably than having to obtain it.
This results in an structure like this:
In observe the true structure is very distributed:
- Indexing might be closely parallelized and we could have many indexing jobs operating concurrently;
- The question service will likely be extensively distributed to assist load from many consumers which are additionally distributed;
- The databases will likely be replicated throughout the question service machines and in addition backed up centrally.
We’ve discovered that having a centralized indexing infrastructure permits a variety of highly effective developer instruments. We’ll discuss a number of the methods we’ve deployed Glean shortly, however first we’ll dive into the rationale for Glean’s design.
How is Glean totally different?
Code indexing methods have been round for some time. For instance, there’s a well-established format referred to as LSIF utilized by IDEs that caches details about code navigation.
After we designed Glean we wished a system that wasn’t tied both to explicit programming languages or to any explicit use case. Whereas we had some use instances in thoughts that we wished to assist—primarily code navigation in fact—we didn’t wish to design the system round one use case, within the hope {that a} extra normal system would assist rising necessities additional into the longer term.
Subsequently:
- Glean doesn’t resolve for you what knowledge you’ll be able to retailer. Certainly, most languages that Glean indexes have their very own knowledge schema and Glean can retailer arbitrary non-programming-language knowledge too. The information is in the end saved utilizing RocksDB, offering good scalability and environment friendly retrieval.
- Glean’s question language could be very normal. It’s a declarative logic-based question language that we name Angle (“Angle” is an anagram of “Glean”, and means “to fish”). Angle helps deriving info routinely, both on-the-fly at question time or forward of time; this can be a highly effective mechanism that permits Glean to summary over language-specific knowledge and supply a language-neutral view of the info.
Storing arbitrary language-specific knowledge might be very highly effective. For instance, in C++ we use the detailed knowledge to detect lifeless code comparable to unused #embrace or utilizing statements. The latter particularly is reasonably tough to do appropriately and requires the info to incorporate some C++-specific particulars, comparable to which utilizing assertion is used to resolve every image reference.
However, shoppers usually don’t need the total language-specific knowledge. They wish to work at the next degree of abstraction. Think about asking questions like, “Give me the names and places of all of the declarations on this file”, which ought to work for any language, and which you may use to implement a code define characteristic in a code browser. Glean can present this language-neutral view of the info by defining an abstraction layer within the schema itself – the mechanism is much like SQL views in case you’re accustomed to these. Which means we don’t need to compromise between having detailed language-specific knowledge or a lowest-common-denominator language-neutral view; we are able to have each.
This generality has allowed Glean to increase to quite a few use instances past what we initially envisaged. We’ll cowl a few of these later on this submit.
A style of Angle
Glean has a unified language, Angle, for specifying each schemas and queries. As talked about above, every language that we index has its personal schema. To present you a taste of this, right here’s a fraction of the schema for C++ operate declarations:
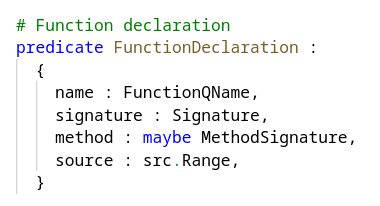
Defining a schema for Glean is rather like writing a set of sort definitions. The braces encompass a file definition, with a set of fields and their sorts.
- A FunctionDeclaration is a predicate (roughly equal to a desk in SQL).
- The situations of a predicate are referred to as info (roughly equal to rows in SQL).
- A predicate is a factor that you could question, and a question returns info.
To question effectively you specify a prefix of the fields. So, for instance, we are able to retrieve a selected FunctionDeclaration effectively if we all know its identify.
Let’s write a question to search out the operate folly::parseJson:

With out going into all the small print, at a excessive degree this question specifies that we wish to discover FunctionDeclaration info which have a selected identify and namespace. Glean can return outcomes for this question in a few millisecond.
Angle helps extra complicated queries too. For instance, to search out all lessons that inherit from a category referred to as exception and have a way referred to as what that overrides a way in a base class:

This question returns the primary leads to a number of milliseconds, and since there could be lots of outcomes we are able to fetch the outcomes incrementally from the question server.
Incremental indexing
An necessary innovation in Glean is the power to index incrementally. Because the codebase grows, and the speed of change of the codebase will increase (a monorepo suffers from each of those issues) we discover that we are able to’t present up-to-date details about the most recent code as a result of indexing the whole repository can take a very long time. The index is perpetually old-fashioned, maybe by many hours.
The answer to this scaling downside is to course of simply the adjustments. By way of pc science big-O notation, we wish the price of indexing to be O(adjustments) reasonably than O(repository).
However truly attaining this isn’t as simple as it would sound.
We don’t wish to destructively modify the unique knowledge, as a result of we want to have the ability to present knowledge at a number of revisions of the repository, and to do this with out storing a number of full-sized copies of the info. So we want to retailer the adjustments in such a means that we are able to view the entire index at each revisions concurrently.
Even when we work out a technique to characterize the adjustments, in observe it isn’t attainable to attain O(adjustments) for a lot of programming languages. For instance, in C++ if a header file is modified, we have now to reprocess each supply file that relies on it (instantly or not directly). We name this the fanout. So in observe the most effective we are able to do is O(fanout).
Glean solves the primary downside with an ingenious methodology of stacking immutable databases on high of one another. A stack of databases behaves identical to a single database from the shopper’s perspective, however every layer within the stack can non-destructively add info to, or conceal info from, the layers under.
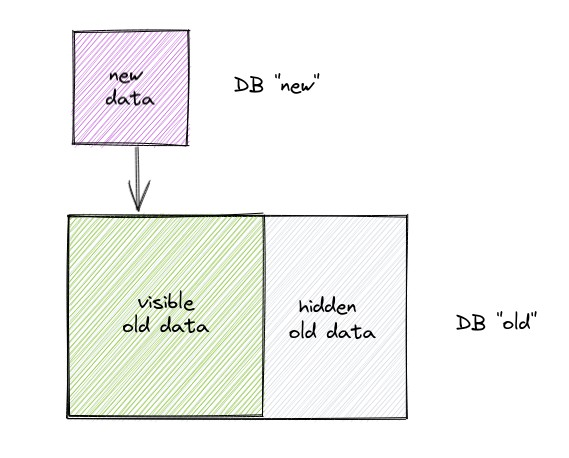
The complete particulars are past the scope of this submit, for extra on how incrementality works see: Incremental indexing with Glean.
Discovering the fanout of a set of adjustments is totally different for every language. Curiously the fanout can usually be obtained utilizing Glean queries: for instance for C++, the fanout is calculated by discovering all of the information that #embrace one of many modified information, after which repeating that question till there aren’t any extra information to search out.
How we use Glean at Meta
Code navigation
Code navigation at scale, on giant monorepos containing thousands and thousands of traces in numerous programming languages, is a difficult downside. However what makes it totally different from the code navigation assist accessible in trendy IDEs, apart from scale? In our expertise, code indexing a la Glean presents the next benefits over IDEs:
- Immediately accessible: Simply open the code browser net app (our inner device makes use of Monaco) and navigate with out ready for the IDE, construct system, and LSP server to initialize
- Extra extensively accessible: You possibly can combine code navigation in just about any app that reveals code! One significantly helpful integration is in your code assessment device (ours is named Phabricator), however extra on that later.
- Full repo visibility: Glean permits you to, for instance, discover all of the references to a operate, not simply those seen to the IDE. That is significantly helpful for locating lifeless code, or discovering shoppers of an API that you simply wish to change.
- Image seek for all of the languages throughout the entire repository.
- Cross language navigation: A typical scenario that comes up is a distant process name (RPC). When shopping the code you would possibly wish to leap to the service definition or, certainly, to the service implementation itself. One other case is languages with a international operate interface (FFI), the place you want to browse from an FFI name to the corresponding definition within the goal language.
Our structure for code navigation is predicated on Glass, a logo server that abstracts all of the complexities of Glean by implementing the same old code navigation logic in a easy however highly effective API. The code browser wants solely a single Glass API name, documentSymbols(repo,path,revision), to acquire a listing of all of the definitions and references in a supply file, together with supply and goal spans. The checklist of definitions is used to render a top level view of the file, and the checklist of references to render underlines that may be hovered over or clicked to navigate. Lastly, different code browser options like Discover References or Name Hierarchy are additionally pushed by API calls to Glass.
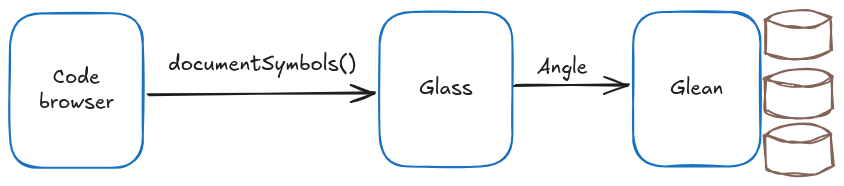
The code for Glass can also be open-source, you will discover it in glean/glass on GitHub.
Rushing up the IDE
Utilizing an IDE comparable to VS Code on a big mission, or a mission with a big set of dependencies, or in a big monorepo tends to result in a degraded expertise because the IDE isn’t in a position to analyze all of the code that you simply would possibly wish to discover. At Meta we’re utilizing Glean to plug this hole for C++ builders: As a result of Glean has already analyzed the entire repository, C++ builders have entry to primary performance comparable to go-to-definition, find-references, and doc remark hovercards for the entire repository instantly on startup. Because the IDE masses the information the developer is engaged on, the C++ language service seamlessly blends the Glean-provided knowledge with that offered by the native clangd backend.
Our goal was C++ builders initially as a result of that group usually has the worst IDE expertise as a result of lengthy compile instances, however the strategy isn’t particular to C++ and we think about different languages following the identical path sooner or later.
Documentation era
The information we retailer in Glean contains sufficient info to reconstruct the total particulars of an API: lessons, strategies, sort signatures, inheritance, and so forth. Glean additionally collects documentation from the supply code when it makes use of the usual conference for the language, e.g., in C++ the conference is /// remark or /** remark */. With API knowledge and documentation strings in Glean we are able to produce automatically-generated documentation on demand.
Right here’s an instance web page for the folly::Singleton sort:
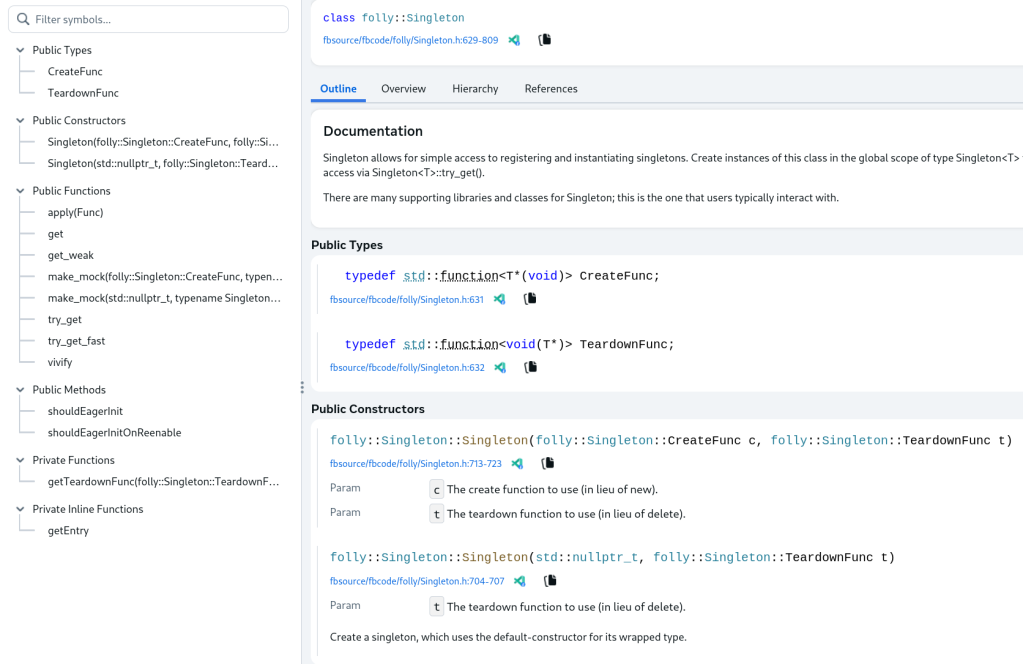
The information for these pages is produced by Glass and rendered by a client-side UI. The documentation is totally hyperlinked so the person can navigate round all of the APIs all through the repository simply. Meta engineers get constant code documentation integrations throughout all of the programming languages supported by Glean.
Image IDs
Glass assigns each image a image ID, a novel string that identifies the image. For instance, the image ID for folly::Singleton could be one thing like, REPOSITORY/cpp/folly/Singleton. The image ID can be utilized to hyperlink on to the documentation web page for the image, so there’s a URL for each image that doesn’t change even when the image’s definition strikes round.
We will use the image ID to request details about a logo from Glass, for instance to search out all of the references to the image all through the repository. All of this works for each language, though the precise format for a logo ID varies per language.
Analyzing code adjustments
Glean indexing runs on diffs (assume, “pull requests”) to extract a mechanical abstract of the changeset that we name a diff sketch. For instance, a diff would possibly introduce a brand new class, take away a way, add a discipline to a kind, introduce a brand new name to a operate, and so forth. The diff sketch lists all of those adjustments in a machine-readable kind.
Diff sketches are used to drive a easy static evaluation that may establish potential points which may require additional assessment. They may also be used to drive non-trivial lint guidelines, wealthy notifications, and semantic search over commits. One instance of the latter is connecting a manufacturing stack hint to current commits that changed the affected operate(s), to assist root-cause efficiency points or new failures.
Indexing diffs additionally powers code navigation in our code assessment instruments, giving code reviewers entry to correct go-to-definition on the code adjustments being reviewed, together with different code insights comparable to type-on-hover and documentation. This can be a highly effective raise to the code assessment course of, making it simpler for reviewers to grasp the adjustments and supply invaluable assessment suggestions. At Meta that is enabled for a variety of different languages, together with C++, Python, PHP, Javascript, Rust, Erlang, Thrift, and even Haskell.
Extra purposes for Glean
Except for the first purposes described above, Glean can also be used to
- Analyse construct dependency graphs.
- Detect and remove dead code.
- Monitor the progress of API migrations.
- Measure numerous metrics that contribute to code complexity.
- Monitor check protection and choose assessments to run.
- Automate data removal.
- Retrieval Augmented Era (RAG) in AI coding assistants
Moreover, there are an ever-growing variety of ad-hoc queries made by numerous folks and methods to resolve quite a lot of issues. Having a system like Glean means you’ll be able to ask questions on your code: we don’t know all of the questions we’d wish to ask, nor do we all know all the info we’d wish to retailer, so Glean intentionally goals to be as normal as attainable on each of those fronts.
Attempt Glean at this time
Go to the Glean site for extra particulars, technical documentation, and knowledge on find out how to get began.











{kind=link}