At Slack, we’ve lengthy been conservative technologists. In different phrases, after we spend money on leveraging a brand new class of infrastructure, we do it rigorously. We’ve executed this since we debuted machine learning-powered features in 2016, and we’ve developed a strong course of and expert staff within the house.
Regardless of that, over the previous 12 months we’ve been blown away by the rise in functionality of commercially obtainable massive language fashions (LLMs) — and extra importantly, the distinction they might make for our customers’ greatest ache factors. An excessive amount of to learn? Too arduous to search out stuff? Not anymore — 90% of users who adopted AI reported a better degree of productiveness than those that didn’t.
However as with all new expertise, our means to launch a product with AI is based on discovering an implementation that meets Slack’s rigorous requirements for buyer knowledge stewardship. So we got down to construct not simply superior AI options, however superior and trusted AI.
The generative mannequin trade is kind of younger; it’s nonetheless largely research-focused, and never enterprise-customer targeted. There have been few current enterprise-grade safety and privateness patterns for us to leverage when constructing out the brand new Slack AI structure.
As a substitute, to tell how we constructed out Slack AI, we began from first rules. We started with our necessities: upholding our current security and compliance offerings, in addition to our privacy principles like “Buyer Knowledge is sacrosanct.” Then, by means of the precise lens of generative AI, our staff created a brand new set of Slack AI rules to information us.
- Buyer knowledge by no means leaves Slack.
- We don’t practice massive language fashions (LLMs) on buyer knowledge.
- Slack AI solely operates on the info that the consumer can already see.
- Slack AI upholds all of Slack’s enterprise-grade safety and compliance necessities.
These rules made designing our structure clearer, though generally more difficult. We’ll stroll by means of how every of those knowledgeable what Slack AI seems like at this time.
Buyer knowledge by no means leaves Slack
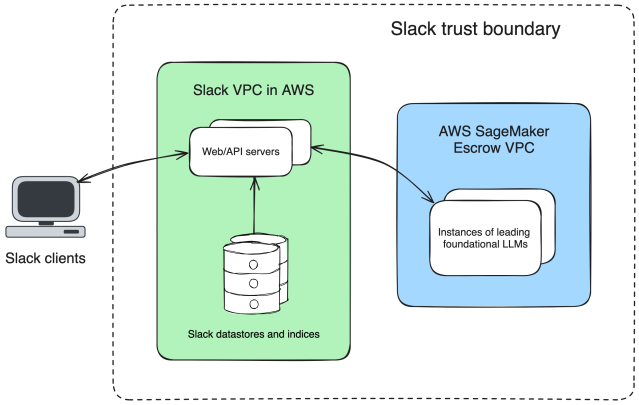
The primary, and maybe most vital, determination we confronted was how to make sure that we might use a top-tier foundational mannequin whereas by no means permitting buyer knowledge to depart Slack-controlled VPCs. Within the generative mannequin trade, most clients of foundational fashions had been calling the hosted providers instantly, and various choices had been scarce.
We knew this method wouldn’t work for us. Slack, and our clients, have excessive expectations round data ownership. Specifically, Slack is FedRAMP Moderate authorized, which confers particular compliance necessities, together with not sending buyer knowledge exterior of our belief boundary. We needed to make sure our knowledge didn’t depart our AWS Digital Personal Cloud (VPC) in order that we might assure that third events wouldn’t have the power to retain it or practice on it.
So we started to search for artistic options the place we might host a foundational mannequin on our personal infrastructure. Nevertheless, most foundational fashions are closed-source: Their fashions are their secret sauce, they usually don’t like handy them to clients to deploy on their very own {hardware}.
Thankfully, AWS has an providing the place it may be the trusted dealer between foundational mannequin supplier and buyer: AWS SageMaker. By utilizing SageMaker, we’re in a position to host and deploy closed-source massive language fashions (LLMs) in an escrow VPC, permitting us to manage the lifecycle of our clients’ knowledge and make sure the mannequin supplier has no entry to Slack’s clients’ knowledge. For extra on how Slack is utilizing SageMaker, check out this post on the AWS blog.
And there we had it: We had entry to a prime tier foundational mannequin, hosted in our personal AWS VPC, giving us assurances on our buyer knowledge.
We don’t practice massive language fashions (LLMs) on buyer knowledge
The following determination was additionally key: We selected to make use of off-the-shelf fashions as an alternative of coaching or fine-tuning fashions. We’ve had privacy principles in place since we started using extra conventional machine studying (ML) fashions in Slack, like those that rank search outcomes. Amongst these rules are that knowledge is not going to leak throughout workspaces, and that we provide clients a alternative round these practices; we felt that, with the present, younger state of this trade and expertise, we couldn’t make sturdy sufficient ensures on these practices if we skilled a generative AI mannequin utilizing Slack’s clients’ knowledge.
So we made the selection to make use of off-the-shelf fashions in a stateless method by using Retrieval Augmented Era (RAG). With RAG, you embody the entire context wanted to carry out a activity inside every request, so the mannequin doesn’t retain any of that knowledge. For instance, when summarizing a channel, we’ll ship the LLM a immediate containing the messages to be summarized, together with directions for a way to take action. The statelessness of RAG is a big privateness profit, nevertheless it’s a product profit as properly. All of Slack AI’s outcomes are grounded in your organization’s data base — not the general public Web – which makes the outcomes extra related and correct. You get the advantage of incorporating your proprietary and particular person knowledge set with out the chance of a mannequin retaining that knowledge.
Utilizing RAG can slim down the set of fashions you should utilize; they should have “context home windows” massive sufficient so that you can cross in all the info you need to use in your activity. Moreover, the extra context you ship an LLM, the slower your request will likely be, because the mannequin must course of extra knowledge. As you possibly can think about, the duty of summarizing all messages in a channel can contain fairly a bit of knowledge.
This posed a problem for us: Discover a top-tier mannequin with a big context window with pretty low latency. We evaluated quite a lot of fashions and located one which suited our first use circumstances, summarization and search, properly. There was room for enchancment, although, and we started an extended journey of each immediate tuning and chaining extra conventional ML fashions with the generative fashions to enhance the outcomes.
RAG is getting simpler and quicker with every iteration of fashions: Context home windows are rising, as is the fashions’ means to synthesize knowledge throughout a big context window. We’re assured that this method can get us each the standard we’re aiming for whereas serving to guarantee our clients’ knowledge is protected.
Slack AI solely operates on the info that the consumer can already see
It’s one in all our core tenets that Slack AI can solely see the identical knowledge that the requesting consumer can see. Slack AI’s search characteristic, for instance, won’t ever floor any outcomes to the consumer that commonplace search wouldn’t. Summaries won’t ever summarize content material that the consumer couldn’t in any other case see whereas studying channels.
We guarantee this through the use of the requesting consumer’s Entry Management Checklist (ACLs) when fetching the info to summarize or search and by leveraging our current libraries that fetch the info to show in channel or on the search outcomes web page.
This wasn’t arduous to do, technically talking, nevertheless it wanted to be an express alternative; one of the simplest ways to ensure this was to construct on prime of, and reuse, Slack’s core characteristic units whereas including some AI magic on the finish.
It’s price noting, too, that solely the consumer who invokes Slack AI can see the AI-generated output. This builds confidence that Slack is your trusted AI associate: Solely the info that you may see goes in, after which solely you possibly can see the output.
Slack AI upholds all of Slack’s enterprise-grade safety and compliance necessities
There’s no Slack AI with out Slack, so we ensured that we built-in all of our enterprise grade compliance and safety choices. We observe the precept of least knowledge: We retailer solely the info wanted to finish the duty, and just for the length vital.
Generally the least knowledge is: None. The place doable, Slack AI’s outputs are ephemeral: Dialog summaries and search solutions all generate point-in-time responses that aren’t saved on disk.
The place that’s not doable, we reused as a lot of Slack’s current compliance infrastructure as doable, and constructed new help the place we needed to. Lots of our compliance choices come inbuilt with our current infrastructure, resembling Encryption Key Administration and Worldwide Knowledge Residency. For others, we inbuilt particular help to make it possible for derived content material, like summaries, are conscious of the messages that went into them; for instance, if a message is tombstoned due to Knowledge Loss Safety (DLP), any summaries derived from that message are invalidated. This makes DLP and different administrative controls highly effective with Slack AI: The place these controls had been already lively on Slack’s message content material, they’re additionally lively Slack AI outputs.
Whew — that was an extended journey! And I didn’t even get to take you thru how we construct prompts, consider fashions, or deal with spiky demand; we’ll save that for subsequent time. However I’m glad we began right here, with safety and privateness: We would like our clients to understand how critically we take defending their knowledge, and the way we’re safeguarding it every step of the best way.
All in favour of serving to us construct Slack’s AI capabilities? We’re hiring! Apply now











{kind=link}