- At Meta, we’ve been diligently working to include privateness into completely different methods of our software program stack over the previous few years. Right this moment, we’re excited to share some cutting-edge applied sciences which can be a part of our Privacy Aware Infrastructure (PAI) initiative. These improvements mark a significant milestone in our ongoing dedication to honoring consumer privateness.
- PAI presents environment friendly and dependable first-class privateness constructs embedded in Meta infrastructure to handle complicated privateness points. For instance, we constructed Coverage Zones that apply throughout our infrastructure to handle restrictions on knowledge, comparable to utilizing it just for allowed functions, offering robust ensures for limiting the needs of its processing.
- As we expanded PAI throughout Meta, growing its maturity, we gained valuable insights. Our understanding of the expertise advanced, revealing the necessity for a bigger funding than initially deliberate to create a cohesive ecosystem of libraries, device suites, integrations, and extra. These investments have been essential in implementing complicated function limitation eventualities whereas making certain scalability, reliability, and a streamlined developer expertise.
Function limitation, a core knowledge safety precept, is about making certain knowledge is just processed for explicitly acknowledged functions. An important facet of function limitation is managing knowledge because it flows throughout methods and companies. Generally, function limitation can depend on “level checking” controls on the level of information processing. This method entails utilizing easy if statements in code (“code belongings”) or entry management mechanisms for datasets (“knowledge belongings”) in knowledge methods. Nevertheless, this method could be fragile because it requires frequent and exhaustive code audits to make sure the continual validity of those controls, particularly because the codebase evolves. Moreover, entry management mechanisms handle permissions for various datasets to replicate varied functions utilizing mechanisms like entry management lists (ACLs), which requires the bodily separation of information into distinct belongings to make sure every maintains a single function. When Meta began to handle extra and larger-scope function limitation necessities that crossed dozens of our methods, these level checking controls didn’t scale.
At Meta, tens of millions of information belongings are essential for powering our product ecosystem, optimizing machine learning models for personalized experiences, and making certain our merchandise are prime quality and meet consumer expectations. Figuring out which code branches and knowledge belongings require safety is difficult as a result of complicated propagation necessities and permissions fashions that want fixed revision. For instance, when an information shopper reads from one knowledge asset (“supply”) and shops the output in one other (“sink”), level checking controls would require complicated orchestration to make sure propagation from sources to sinks, which might turn into operationally unviable.
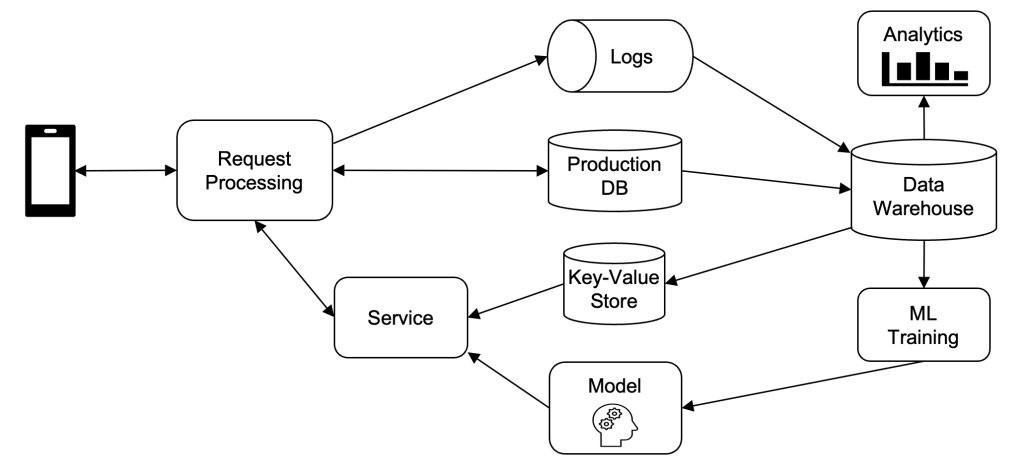
To handle this drawback, level checking controls could be enhanced by leveraging knowledge circulation alerts. Knowledge flows could be tracked from the identical origin, the place related knowledge is collected, utilizing varied strategies comparable to static code analysis, logging, and post-query processing. This creates a graph, often known as “knowledge lineage,” that tracks the relationships between supply and sink knowledge belongings. By using knowledge lineage, permissions could be utilized to related knowledge belongings based mostly on these source-to-sink relationships. The mixture of level checking and knowledge lineage, whereas viable at a small scale, results in important operational overhead as level checking nonetheless requires auditing many particular person belongings.
Constructing on these insights, in our newest iteration, we discovered that the information flow control (IFC) model presents a more durable and sustainable approach by controlling not solely knowledge entry but additionally how knowledge is processed and transferred in real-time, fairly than counting on level checking or out-of-band audits. Thus, we developed Coverage Zones as our IFC-based expertise and built-in it throughout main Meta methods to boost our function limitation capabilities at scale. This effort was later expanded into the Privacy Aware Infrastructure (PAI) initiative, a transformative funding that integrates first-class privateness assist into Meta’s infrastructure methods.
We imagine PAI is the best funding to guard individuals’s privateness at scale and might successfully implement function limitation necessities.
Why put money into Coverage Zones?
Via our expertise deploying function limitation options over time, we recognized a number of key themes:
| Wants | Downside | Resolution |
| Programmatic Management: We wanted to rely extra on programmatic controls as a substitute of level checking human audits to manage knowledge flows, and accomplish that in real-time | Conventional level checking controls, mixed with knowledge lineage checks, can detect knowledge transfers inside a selected timeframe however not in real-time. Addressing these dangers requires implementing resource-intensive human audits at entry factors. | In distinction, PAI is designed to verify knowledge flows in real-time throughout code execution, blocking problematic knowledge flows from occurring, facilitated by UX tooling, thus making it extra scalable. |
| Granular Move Management: We wanted to maximise the reuse of current knowledge and enterprise logic on complicated infra | Entry management is straightforward to roll out when knowledge is separated bodily, however poses important prices, complexity, and limitations when coping with Meta’s complicated infrastructure, the place knowledge for various functions is usually processed by shared code. | PAI solves this by offering exact resolution making on the granular stage of particular person requests, perform calls, or knowledge components, reaching logical knowledge separation at a comparatively low compute price even on complicated infrastructures the place it’s wanted. |
| Adaptable and Extensible Management: We wanted to deal with ever-evolving necessities, even a number of for a similar knowledge belongings | We face a quickly altering world for privateness. Knowledge use restrictions can fluctuate over time relying on evolving privateness and product necessities. A single knowledge asset or completely different components of it could be topic to a number of privateness necessities. Whereas “level checking” can handle this to some extent, it struggles to manage downstream knowledge flows, even mixed with knowledge lineage. | PAI is designed to verify a number of necessities concerned in knowledge flows and is very versatile to adapt to altering necessities. |
How Coverage Zones works
Let’s dive into what Coverage Zones is and the way we are able to leverage it to fulfill function limitation necessities. Coverage Zones gives a complete mechanism for encapsulating, evaluating, and propagating privateness constraints for knowledge each “in transit” and “at relaxation,” together with transitions between completely different methods. It conducts runtime analysis of constraints, context propagation, and is deeply built-in with quite a few knowledge and code frameworks (e.g., HHVM, Presto, and Spark), representing a step change in how we method info circulation management.
To make the reason extra relatable and produce some levity to a critical matter, we’ll use a easy instance: Let’s say a brand new requirement comes up, the place banana knowledge can solely be used for the needs of constructing smoothies and fruit baskets, however not for making banana bread. For simplicity, this instance and the illustration beneath solely show the primary row of the above desk.
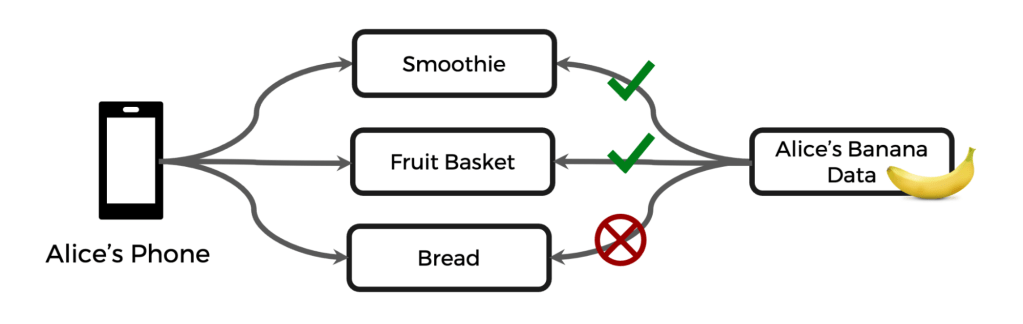
How would builders leverage Coverage Zones to implement such a requirement?
First, to demarcate related knowledge belongings, they assign a metadata label (“knowledge annotation,” e.g., BANANA_DATA) to knowledge belongings at completely different granularities. This annotation is related to the aim limitation requirement as a set of information circulation guidelines that allow methods to know the allowed functions for the info.
When annotated knowledge is processed, Coverage Zones kicks in and checks whether or not the info processing is allowed and knowledge can circulation downstream. Coverage Zones has been constructed into completely different Meta methods, together with:
- Perform-based methods that load, course of, and propagate knowledge via stacks of perform calls in several programming languages. Examples embody net frontend, middle-tier, and backend companies.
- Batch-processing methods that course of knowledge rows in batch (primarily by way of SQL). Examples embody real-time and knowledge warehouse methods that energy Meta’s AI and analytics workloads.
Let’s dive deeper into how Coverage Zones works for the function-based methods, whereas the identical logic applies to the batch-processing methods as nicely.
In function-based methods, knowledge is handed via parameters, variables, or return values in a stack of perform calls.
Let’s stroll via an instance:
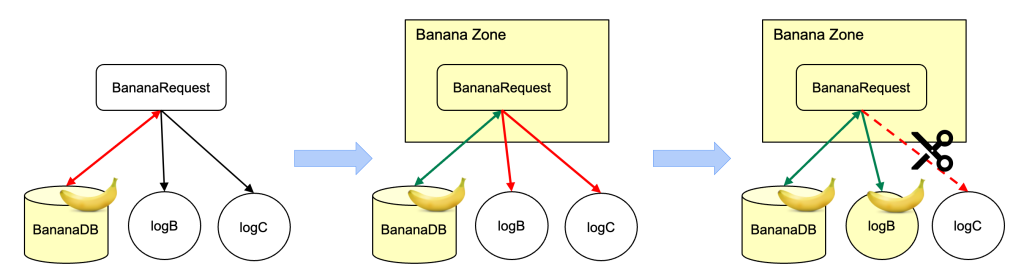
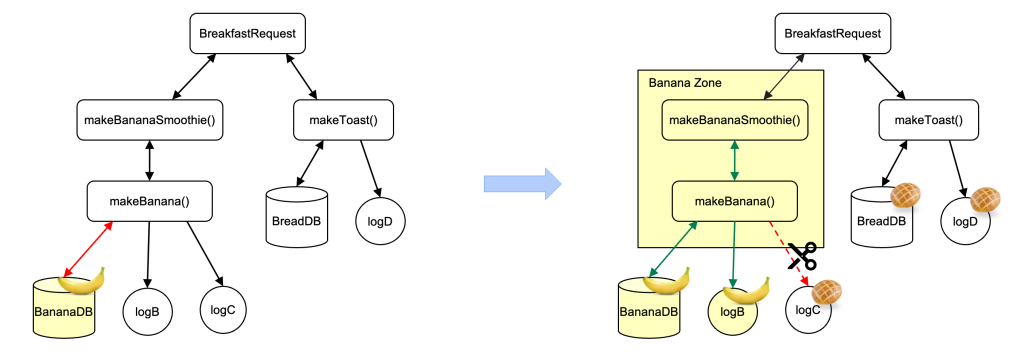
- An online request, “BananaRequest,” hundreds annotated knowledge from BananaDB, inflicting an information circulation violation as a result of the intent of the caller is unknown.
- To remediate the info circulation violation, we annotate BananaRequest with the BANANA_DATA label, making a zone (“Banana Zone”) for the request.
- Behind the scenes at runtime, Coverage Zones programmatically checks all knowledge flows towards the circulation guidelines based mostly on the context, flagging new knowledge circulation violations from BananaRequest to logB and logC.
- We annotate logB as banana and take away the logging of banana knowledge into logC to chop off the disallowed knowledge circulation.
- With all knowledge circulation violations remediated, the zone could be moved from logging mode to enforcement. If a developer provides a write to a sink exterior of the zone, it is going to be blocked routinely.
In a extra complicated state of affairs, a perform, “makeBananaSmoothie()” from an internet request, “BreakfastRequest” calls one other perform, “makeBanana().” Moreover the earlier knowledge circulation violations, we have to remediate one other knowledge circulation violation: makeBanana() returns banana knowledge to makeBananaSmoothie(). This implies we are able to create a “Banana Zone” from the perform makeBananaSmoothie() that features all features that it calls straight or not directly.
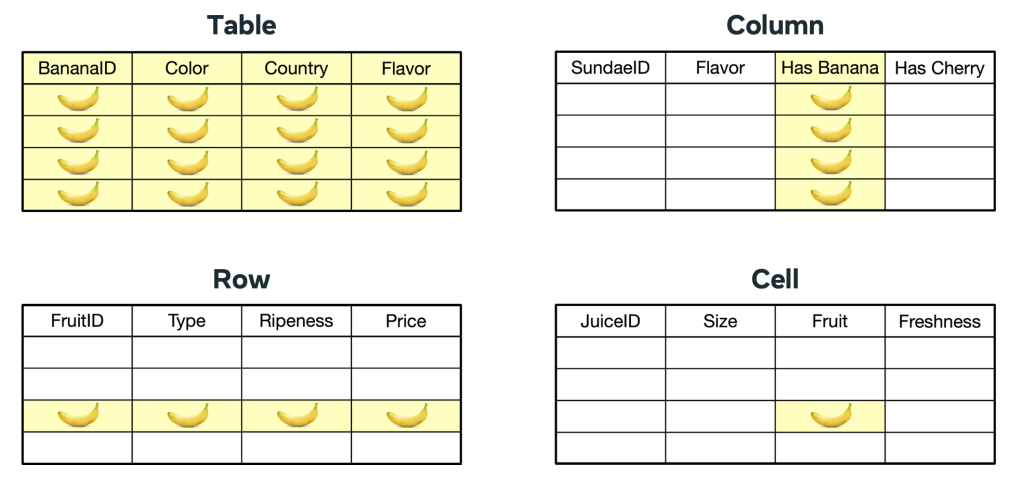
In batch-processing methods, knowledge is processed in batches for rows from tables which can be annotated as containing related knowledge. When a job runs a question (normally SQL-based) to course of the info, a zone is created and Coverage Zones flags any knowledge circulation violations. Remediation choices are supplied, just like these for function-based methods. As soon as all violations have been remediated, the zone could be moved from logging mode to enforcement mode to stop future knowledge circulation violations. Knowledge annotation could be carried out at varied ranges of granularity, together with desk, column, row, or doubtlessly even cell.
When knowledge flows throughout completely different methods (e.g., from frontend, to knowledge warehouse, then to AI), Coverage Zones ensures that related knowledge is annotated accurately and thus continues to be protected based on the necessities. For some methods that don’t have Coverage Zones built-in but, the purpose checking management remains to be used to guard the info.
How we utilized PAI to current methods at scale
The above offers you a glimpse into how the expertise is used to roll out a easy use case. Nevertheless, adopting Coverage Zones is a non-trivial job for complicated necessities throughout tens or lots of of methods. The requirement proprietor normally collaborates with different engineers who’re code and knowledge asset house owners throughout Meta to implement completely different elements of that requirement. In some circumstances, this will contain lots of or hundreds of engineers to finish the implementation and audits. To handle this problem, PAI presents Coverage Zone Supervisor (PZM), a set of UX instruments that helps requirement house owners to effectively implement privateness necessities utilizing PAI.
Let’s check out how PZM makes it simple for individuals to fulfill their function limitation wants in current methods, utilizing the above banana requirement for example. At a excessive stage, the requirement proprietor carries out the next workflow, facilitated by PZM:
- Establish related belongings: That is to establish which supply belongings should be function restricted for the given requirement.
- Uncover related knowledge flows: That is to find the downstream knowledge flows from the supply belongings with a purpose to combine Coverage Zones at scale.
- Remediate knowledge circulation violations: That is to permit individuals to decide on which choice to take to remediate knowledge circulation violations.
- Repeatedly implement and monitor knowledge flows: That is to activate Coverage Zones enforcement and monitor it to stop new knowledge circulation violations.

To listen to extra about this course of, try our presentation at the PEPR conference in June 2024.
Step 1 – Establish related belongings
For a given requirement, we verify the related product entry factors (e.g., cell apps, net requests, and databases) to pinpoint knowledge belongings which can be collected. These belongings could take the type of request parameters, database entries, or occasion log entries. We use knowledge buildings to signify (“schematize”) these knowledge belongings and fields, capturing related knowledge at varied granularities. Within the working instance, a desk within the banana database may include completely banana knowledge, a single banana column, or a mixture of banana and different fruit knowledge.
Along with handbook code inspection, we closely depend on varied strategies comparable to our scalable ML-based classifier to routinely establish knowledge belongings.
Step 2 – Uncover related knowledge flows
From a given annotated supply, the requirement proprietor can establish its downstream knowledge flows and sinks (see diagram beneath). The proprietor can then resolve the way to deal with these knowledge flows. Nevertheless, this course of could be time consuming when there are numerous knowledge flows which can be one or a number of hops away from the identical origin. This typically happens when implementing a brand new requirement over current knowledge flows.
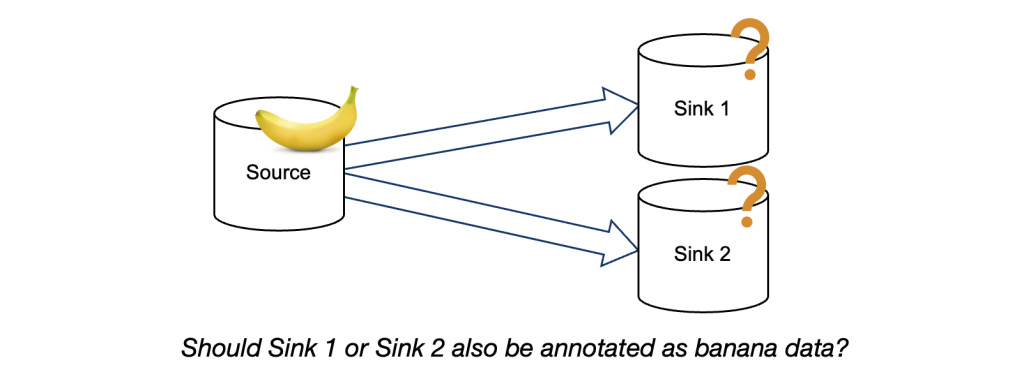
Though knowledge lineage presents important operational overhead for level checking mechanisms, it could effectively establish the place to combine Coverage Zones into the codebase. Due to this fact, we’ve got built-in knowledge lineage into PZM, permitting requirement house owners to find a number of downstream belongings from a given supply concurrently. As soon as the requirement has been totally carried out, we are able to rely solely on Coverage Zones to implement the necessities.
Step 3 – Remediate knowledge circulation violations
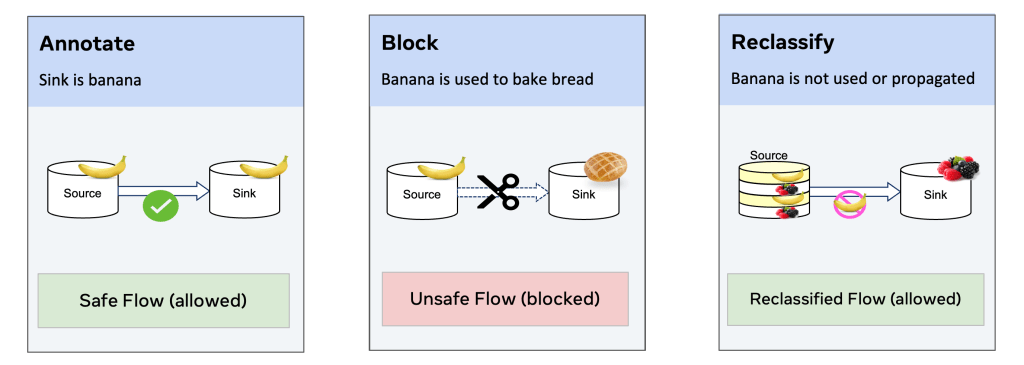
By default, the info circulation from a supply asset to a sink should meet all the necessities of the supply. If not, it’s thought of an information circulation violation and desires remediation, enforced by Coverage Zones programmatically at runtime. There are three important circumstances to remediate knowledge circulation violations (utilizing the working instance to assist concretize the overall circumstances):
- Case 1: Protected circulation – related knowledge is used for allowed function(s): Assign the banana annotation to the sink asset.
- Case 2: Unsafe circulation – related knowledge is used for disallowed function(s): Block knowledge entry and code execution to stop additional processing of banana knowledge.
- Case 3: Reclassified circulation – related knowledge isn’t used or propagated: Annotate the info circulation as reclassified as being permitted. Banana knowledge from the supply isn’t used or propagated to the sink.
Step 4 – Repeatedly implement and monitor knowledge flows
PAI is built-in into our main knowledge methods to verify knowledge flows and catch violations at runtime. Through the preliminary rollout of a brand new requirement, Coverage Zones could be configured to permit remediations of circulation violations in “logging mode.” As soon as Coverage Zones enforcement is enabled, any knowledge circulation with unremediated violations is denied. This additionally prevents new knowledge circulation violations, even when code adjustments or new code is added.
PAI constantly screens the enforcement of necessities to make sure that it operates accurately. PZM gives a set of verifiers to verify the accuracy of asset annotations and management configurations.
Classes realized from adoption at scale throughout Meta
As PAI has been adopted by a mess of function limitation necessities throughout Meta, we’ve realized a number of key classes over the previous few years:
Give attention to fixing one particular end-to-end use case first
Initially, we developed Coverage Zones for batch-processing methods with some fundamental use circumstances. Nevertheless, we realized that our designs for function-based methods have been fairly summary and the adoption for a large-scale use case resulted in important challenges, consequently, requiring appreciable effort to map patterns to buyer wants. Moreover, refining the APIs and constructing lacking operational assist made it work successfully end-to-end throughout a number of methods. Solely after addressing these challenges have been we in a position to make it extra generic and proceed with integrating Coverage Zones throughout intensive platforms.
Streamline integration complexity
Integrating PAI into main Meta methods coherently was a posh, prolonged, and difficult course of. We encountered important difficulties in integrating PAI with Meta’s numerous methods broadly. It took us years to beat these challenges. For instance, initially, product groups expended appreciable effort to schematize knowledge belongings throughout completely different knowledge methods. Then we developed dependable, computationally environment friendly, and broadly relevant PAI libraries in varied programming languages (Hack, C++, Python, and so forth.) that enabled a smoother integration with a broad vary of Meta’s methods.
Put money into computational and developer effectivity early on
We additionally undertook a number of iterations to simplify PAI and enhance its computational effectivity. Our preliminary annotation APIs have been overly complicated, leading to excessive cognitive overhead for engineers. Moreover, the computational overhead of information circulation checking was prohibitively excessive in Meta’s high-throughput methods. Via a number of rounds of refinement, we simplified coverage lattice illustration and analysis, constructed language-level options to natively propagate Coverage Zones context, and canonicalized coverage annotation buildings, reaching 10x enhancements in computational effectivity.
Simplified and unbiased annotations are a should to scale to a variety of necessities
Initially, we employed a monolithic annotation API to mannequin intricate knowledge circulation guidelines and annotate related code and knowledge. Nevertheless, as knowledge from a number of necessities have been mixed, propagating these annotations from sources to sinks grew to become more and more complicated, leading to knowledge annotation conflicts that have been tough to resolve. To handle this problem, we carried out simplified knowledge annotations to decouple knowledge from necessities and separate knowledge circulation guidelines for various necessities. This considerably streamlined the annotation course of, finally enhancing developer experiences.
Construct instruments; they’re required
We now have made important efforts to make sure using PAI is straightforward and environment friendly, finally enhancing the developer expertise. Initially, we centered on the correctness of the expertise first earlier than investing in tooling. Adopting Coverage Zones required lots of handbook effort, and it was difficult for engineers to know the way to correctly annotate their belongings, which led to further cleanup work later. To handle this problem, we developed the PZM device household, which incorporates built-in automated guidelines and classifiers. These instruments information groups via customary workflows, making certain protected and environment friendly rollout of function limitation necessities and lowering engineering efforts by orders of magnitude.
Sturdy privateness safety for everybody
Meta is dedicated to defending consumer privateness. The PAI initiative is an important step in safeguarding knowledge and preserving privateness effectively and reliably. It gives a strong basis for Meta to sustainably deal with privateness challenges, meet excessive reliability requirements, and handle future privateness points extra effectively than conventional options. Whereas we’ve laid a powerful groundwork, our journey is simply starting. We goal to construct upon this basis by increasing our capabilities and controls to accommodate a wider vary of privateness necessities, enhancing the developer expertise, and exploring new frontiers.
We hope our work sparks innovation and fosters collaboration throughout the trade within the discipline of privateness.
Acknowledgements
The authors wish to acknowledge the contributions of many present and former Meta staff who’ve performed a vital function in productionizing and adopting PAI over time. Particularly, we wish to prolong particular because of (in alphabetical order) Adrian Zgorzalek, Alex Gorelik, Amritha Raghunath, Anuja Jaiswal, Brian Sniffen, Brian Romanko, Brian Spanton, David Detlefs, David Mortenson, David Taieb, Gabriela Jacques da Silva, Ian Carmichael, Iuliu Rus, Jafar Husain, Jerry Pan, Jiang Wu, Joel Krebs, Jun Fang, Komal Mangtani, Marc Celani, Mark Konetchy, Michael Levin, Perry Stoll, Peter Prelich, Pieter Viljoen, Prashant Dhamdhere, Rajesh Nishtala, Rajkishan Gunasekaran, Rishab Mangla, Sergey Doroshenko, Seth Silverman, Sriguru Chakravarthi, Tarek Sheasha, Thomas Georgiou, Uday Ramesh Savagaonkar, Vitalii Tsybulnyk, Vlad Fedorov, Wolfram Schulte, and Yi Huang. We might additionally like to specific our gratitude to all reviewers of this submit, together with (in alphabetical order) Aleksandar Ilic, Benjamin Renard, Emil Vazquez, Emile Litvak, Harrison Fisk, Jason Hendrickson, Jessica Retka, Nimish Shah, Sabrina B Ross, and Sam Blatchford. We wish to particularly thank Emily DiPietro for championing the thought, main the editorial effort, and pulling all required assist collectively to make this weblog submit occur.











{kind=link}