- Information lineage is an instrumental a part of Meta’s Privateness Conscious Infrastructure (PAI) initiative, a set of applied sciences that effectively defend person privateness. It’s a important and highly effective device for scalable discovery of related knowledge and knowledge flows, which helps privateness controls throughout Meta’s methods. This permits us to confirm that our customers’ on a regular basis interactions are protected throughout our household of apps, equivalent to their non secular views within the Fb Relationship app, the instance we’ll stroll by way of on this put up.
- To be able to construct high-quality knowledge lineage, we developed totally different methods to gather knowledge circulate alerts throughout totally different expertise stacks: static code evaluation for various languages, runtime instrumentation, and enter and output knowledge matching, and so on. We then constructed an intuitive UX into our tooling that allows builders to successfully devour all of this lineage knowledge in a scientific method, saving important engineering time for constructing privateness controls.
- As we expanded PAI throughout Meta, we gained valuable insights in regards to the knowledge lineage house. Our understanding of the privateness house developed, revealing the necessity for early concentrate on knowledge lineage, tooling, a cohesive ecosystem of libraries, and extra. These initiatives have assisted in accelerating the event of knowledge lineage and implementing objective limitation controls extra shortly and effectively.
At Meta, we consider that privateness allows product innovation. This perception has led us to creating Privacy Aware Infrastructure (PAI), which affords environment friendly and dependable first-class privateness constructs embedded in Meta infrastructure to deal with totally different privateness necessities, equivalent to purpose limitation, which restricts the needs for which knowledge will be processed and used.
On this weblog, we are going to delve into an early stage in PAI implementation: knowledge lineage. Information lineage refers back to the strategy of tracing the journey of knowledge because it strikes by way of numerous methods, illustrating how knowledge transitions from one knowledge asset, equivalent to a database desk (the supply asset), to a different (the sink asset). We’ll additionally stroll by way of how we monitor the lineage of customers’ “faith” data in our Fb Relationship app.
Hundreds of thousands of knowledge property are important for supporting our product ecosystem, making certain the performance our customers anticipate, sustaining excessive product high quality, and safeguarding person security and integrity. Information lineage allows us to effectively navigate these property and defend person knowledge. It enhances the traceability of knowledge flows inside methods, in the end empowering builders to swiftly implement privateness controls and create revolutionary merchandise.
Notice that knowledge lineage depends on having already accomplished necessary and complicated preliminary steps to stock, schematize, and annotate knowledge property right into a unified asset catalog. This took Meta a number of years to finish throughout our thousands and thousands of disparate knowledge property, and we’ll cowl every of those extra deeply in future weblog posts:
- Inventorying includes amassing numerous code and knowledge property (e.g., internet endpoints, knowledge tables, AI fashions) used throughout Meta.
- Schematization expresses knowledge property in structural element (e.g., indicating {that a} knowledge asset has a subject referred to as “faith”).
- Annotation labels knowledge to explain its content material (e.g., specifying that the identification column incorporates faith knowledge).
Understanding knowledge lineage at Meta
To determine strong privateness controls, a necessary a part of our PAI initiative is to grasp how knowledge flows throughout totally different methods. Information lineage is a part of this discovery step within the PAI workflow, as proven within the following diagram:
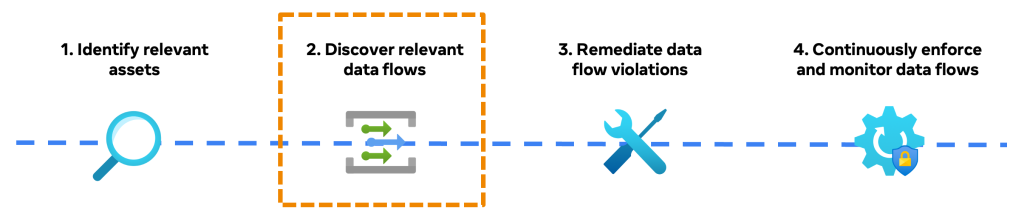
Information lineage is a key precursor to implementing Coverage Zones, our data circulate management expertise, as a result of it solutions the query, “The place does my knowledge come from and the place does it go?” – serving to inform the best locations to use privateness controls. Along with Coverage Zones, knowledge lineage offers the next key advantages to hundreds of builders at Meta:
- Scalable knowledge circulate discovery: Information lineage solutions the query above by offering an end-to-end, scalable graph of related knowledge flows. We will leverage the lineage graphs to visualise and clarify the circulate of related knowledge from the purpose the place it’s collected to all of the locations the place it’s processed.
- Environment friendly rollout of privateness controls: By leveraging knowledge lineage to trace knowledge flows, we are able to simply pinpoint the optimum integration factors for privateness controls like Coverage Zones throughout the codebase, streamlining the rollout course of. Thus we’ve developed a robust circulate discovery device as a part of our PAI device suite, Coverage Zone Supervisor (PZM), based mostly on knowledge lineage. PZM allows builders to quickly determine a number of downstream property from a set of sources concurrently, thereby accelerating the rollout strategy of privateness controls.
- Steady compliance verification: As soon as the privateness requirement has been totally applied, knowledge lineage performs a significant function in monitoring and validating knowledge flows repeatedly, along with the enforcement mechanisms equivalent to Coverage Zones.
Historically, knowledge lineage has been collected through code inspection utilizing manually authored knowledge circulate diagrams and spreadsheets. Nonetheless, this strategy doesn’t scale in massive and dynamic environments, equivalent to Meta, with billions of traces of repeatedly evolving code. To deal with this problem, we’ve developed a sturdy and scalable lineage answer that makes use of static code evaluation alerts in addition to runtime alerts.
Walkthrough: Implementing knowledge lineage for faith knowledge
We’ll share how we’ve automated lineage monitoring to determine faith knowledge flows by way of our core methods, finally creating an end-to-end, exact view of downstream faith property being protected, through the next two key levels:
- Amassing knowledge circulate alerts: a course of to seize knowledge circulate alerts from many processing actions throughout totally different methods, not just for faith, however for all different sorts of knowledge, to create an end-to-end lineage graph.
- Figuring out related knowledge flows: a course of to determine the particular subset of knowledge flows (“subgraph”) throughout the lineage graph that pertains to faith.
These levels propagate by way of numerous methods together with function-based methods that load, course of, and propagate knowledge by way of stacks of perform calls in several programming languages (e.g., Hack, C++, Python, and so on.) equivalent to internet methods and backend providers, and batch-processing methods that course of knowledge rows in batch (primarily through SQL) equivalent to knowledge warehouse and AI methods.
For simplicity, we are going to display these for the net, the info warehouse, and AI, per the diagram beneath.
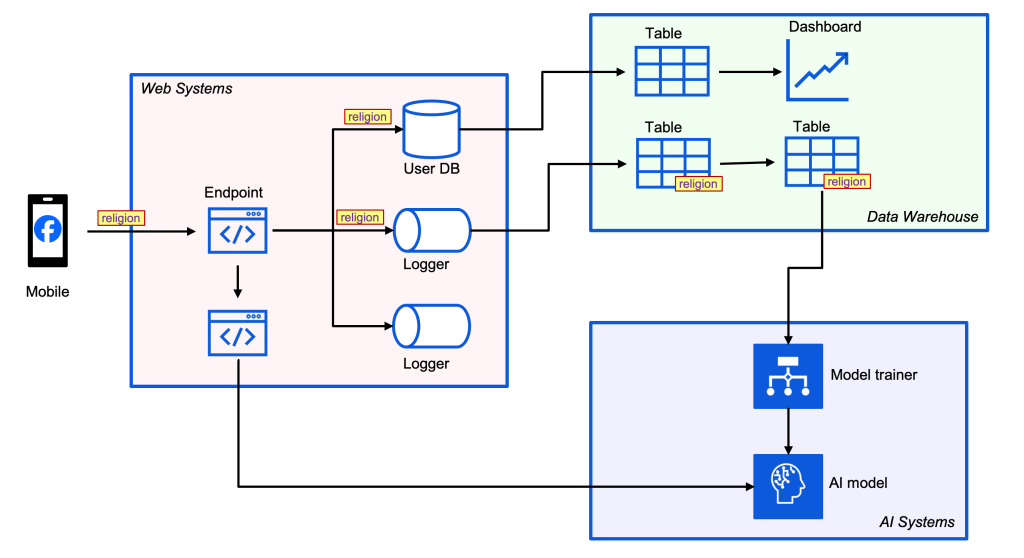
Amassing knowledge circulate alerts for the net system
When establishing a profile on the Fb Relationship app, folks can populate their non secular views. This data is then utilized to determine related matches with different individuals who have specified matched values of their courting preferences. On Relationship, non secular views are topic to objective limitation necessities, for instance, they will not be used to personalize experiences on other Facebook Products.
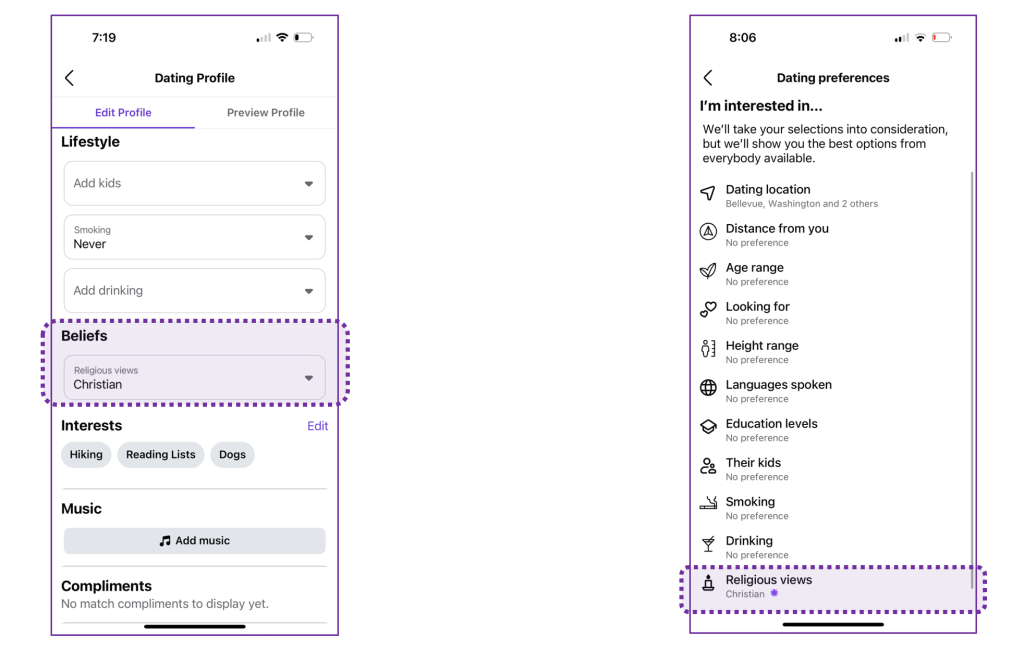
We begin with somebody getting into their faith data on their courting media profile utilizing their cell machine, which is then transmitted to an online endpoint. The online endpoint subsequently logs the info right into a logging desk and shops it in a database, as depicted within the following code snippet:
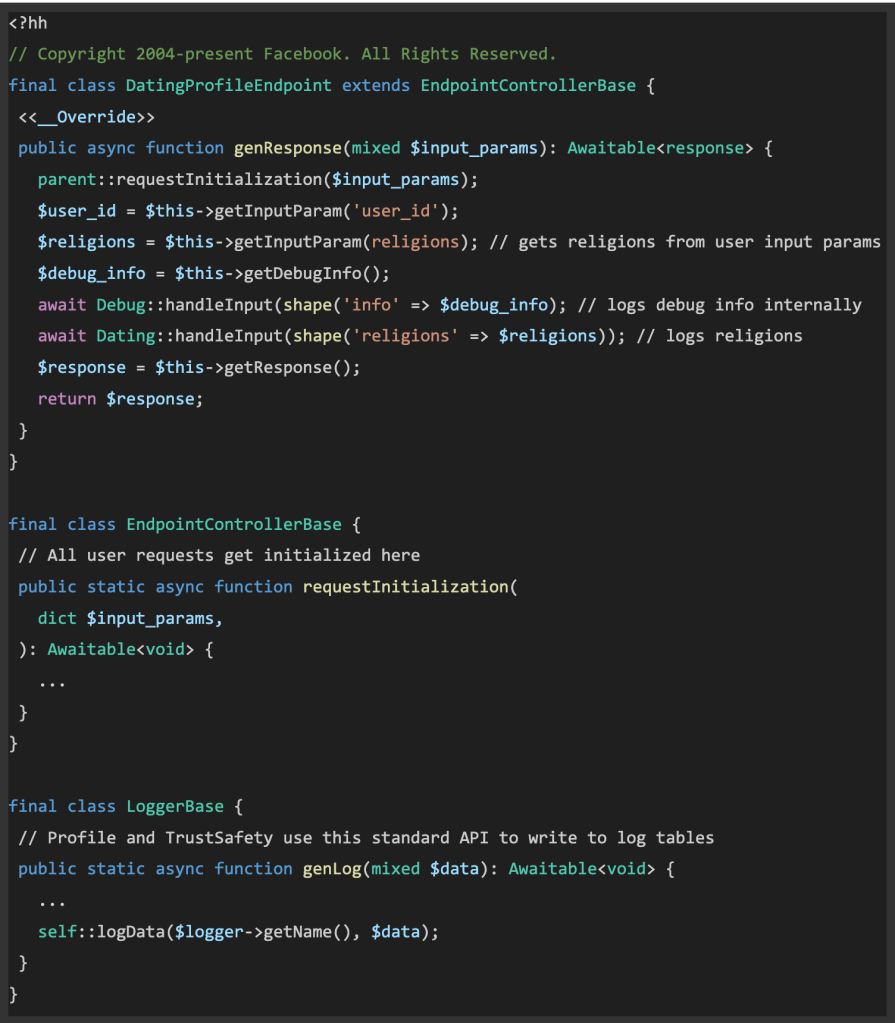
Now let’s see how we accumulate lineage alerts. To do that, we have to make use of each static and runtime evaluation instruments to successfully uncover knowledge flows, significantly specializing in the place faith is logged and saved. By combining static and runtime evaluation, we improve our capability to precisely monitor and handle knowledge flows.
Static analysis tools simulate code execution to map out knowledge flows inside our methods. Additionally they emit high quality alerts to point the arrogance of whether or not a knowledge circulate sign is a real optimistic. Nonetheless, these instruments are restricted by their lack of entry to runtime knowledge, which may result in false positives from unexecuted code.
To handle this limitation, we make the most of Privateness Probes, a key part of our PAI lineage applied sciences. Privateness Probes automate knowledge circulate discovery by amassing runtime alerts. These alerts are gathered in actual time in the course of the execution of requests, permitting us to hint the circulate of knowledge into loggers, databases, and different providers.
Now we have instrumented Meta’s core knowledge frameworks and libraries at each the info origin factors (sources) and their eventual outputs (sinks), equivalent to logging framework, which permits for complete knowledge circulate monitoring. This strategy is exemplified within the following code snippet:
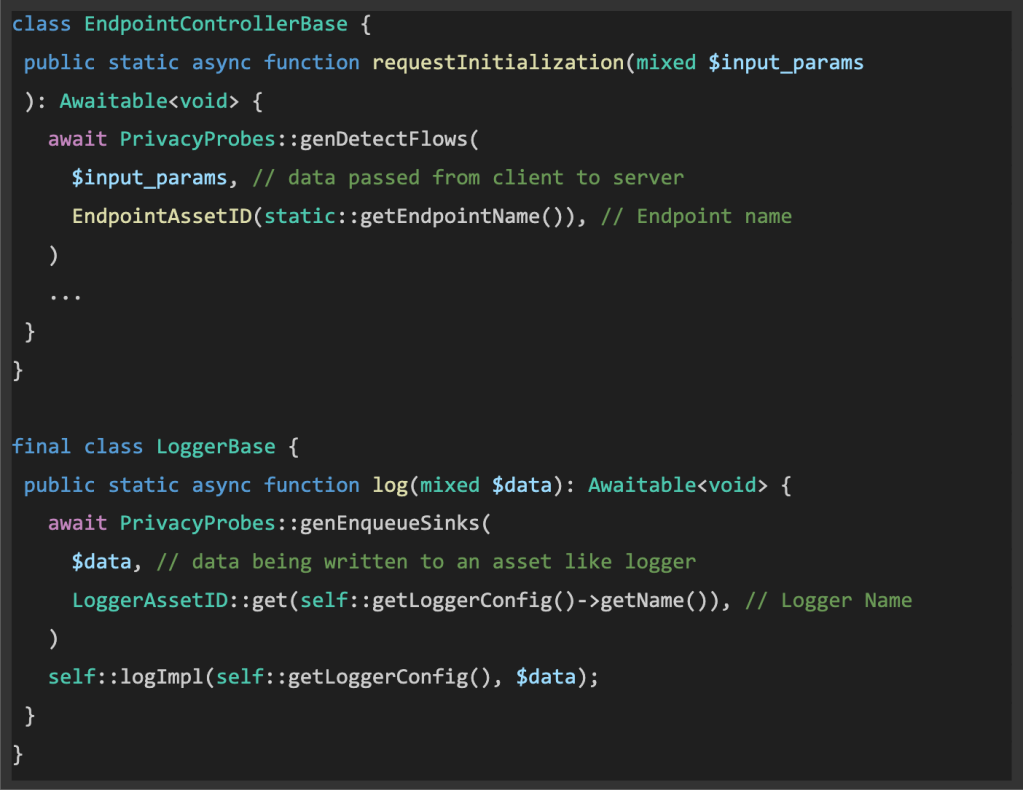
Throughout runtime execution, Privateness Probes does the next:
- Capturing payloads: It captures supply and sink payloads in reminiscence on a sampled foundation, together with supplementary metadata equivalent to occasion timestamps, asset identifiers, and stack traces as proof for the info circulate.
- Evaluating payloads: It then compares the supply and sink payloads inside a request to determine knowledge matches, which helps in understanding how knowledge flows by way of the system.
- Categorizing outcomes: It categorizes outcomes into two units. The match-set consists of pairs of supply and sink property the place knowledge matches precisely or one is contained by one other, subsequently offering excessive confidence proof of knowledge circulate between the property. The full-set consists of all supply and sink pairs inside a request regardless of whether or not the sink is tainted by the supply. Full-set is a superset of match-set with some noise however nonetheless necessary to ship to human reviewers since it might include reworked knowledge flows.
The above process is depicted within the diagram beneath:
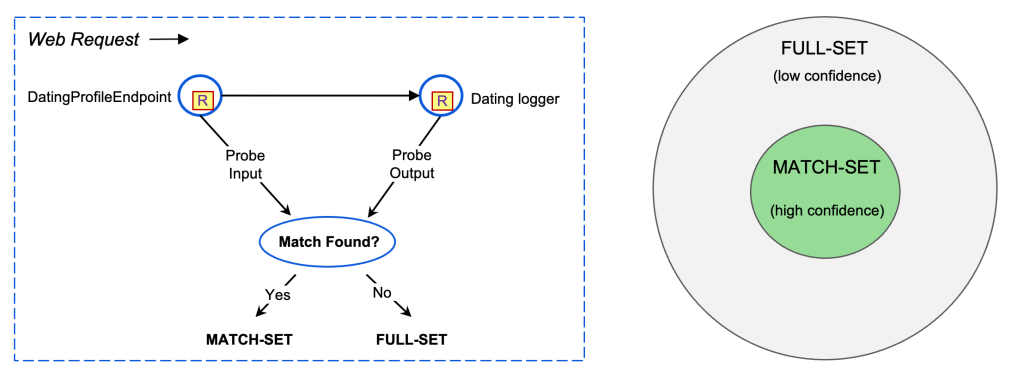
Let’s have a look at the next examples the place numerous religions are obtained in an endpoint and numerous values (copied or reworked) being logged in three totally different loggers:
| Enter Worth (supply) | Output Worth (sink) | Information Operation | Match Outcome | Movement Confidence |
| “Atheist” | “Atheist” | Information Copy | EXACT_MATCH | HIGH |
| “Buddhist” | {metadata: {faith: Buddhist}} | Substring | CONTAINS | HIGH |
| {religions: [“Catholic”, “Christian”]} |
{rely : 2} | Reworked | NO_MATCH | LOW |
Within the examples above, the primary two rows present a exact match of religions within the supply and the sink values, thus belonging to the excessive confidence match-set. The third row depicts a reworked knowledge circulate the place the enter string worth is reworked to a rely of values earlier than being logged, belonging to full-set.
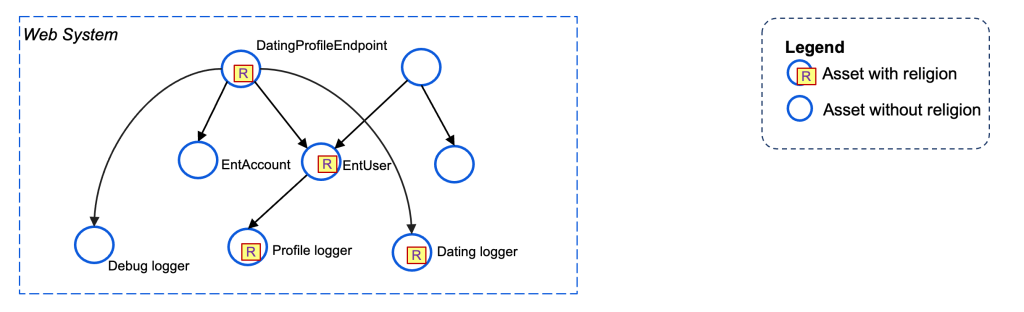
These alerts collectively are used to assemble a lineage graph to grasp the circulate of knowledge by way of our internet system as proven within the following diagram:
Amassing knowledge circulate alerts for the info warehouse system
With the person’s faith logged in our internet system, it will possibly propagate to the info warehouse for offline processing. To collect knowledge circulate alerts, we make use of a mix of each runtime instrumentation and static code evaluation otherwise from the net system. The concerned SQL queries are logged for knowledge processing actions by the Presto and Spark compute engines (amongst others). Static evaluation is then carried out for the logged SQL queries and job configs as a way to extract knowledge circulate alerts.
Let’s look at a easy SQL question instance that processes knowledge for the info warehouse as the next:
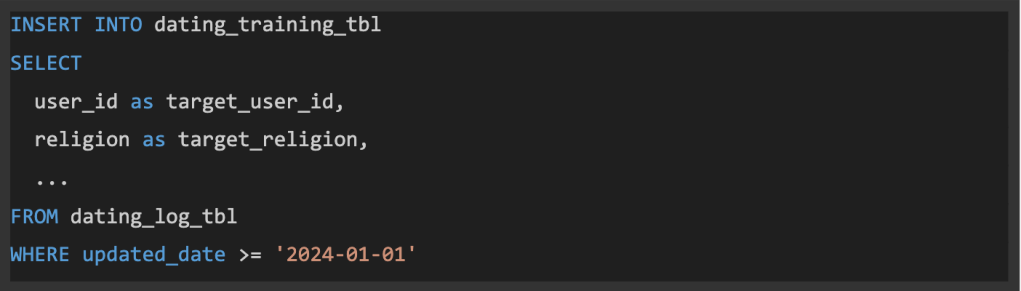
We’ve developed a SQL analyzer to extract knowledge circulate alerts between the enter desk, “safety_log_tbl” and the output desk, “safety_training_tbl” as proven within the following diagram. In observe, we additionally accumulate extra granular-level lineage equivalent to at column-level (e.g., “user_id” -> “target_user_id”, “faith” -> “target_religion”).
Tlisted below are situations the place knowledge will not be totally processed by SQL queries, leading to logs that include knowledge circulate alerts for both reads or writes, however not each. To make sure we’ve full lineage knowledge, we leverage contextual data (equivalent to execution environments; job or hint IDs) collected at runtime to attach these reads and writes collectively.
The next diagram illustrates how the lineage graph has expanded:
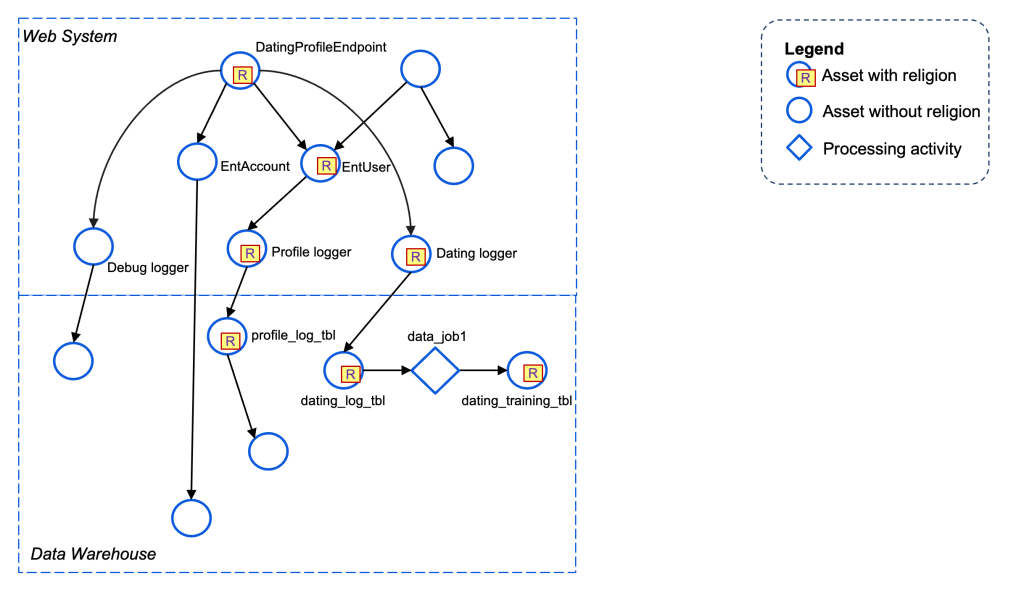
Amassing knowledge circulate alerts for the AI system
For our AI methods, we accumulate lineage alerts by monitoring relationships between numerous property, equivalent to enter datasets, options, fashions, workflows, and inferences. A standard strategy is to extract knowledge flows from job configurations used for various AI actions equivalent to mannequin coaching.
As an example, as a way to enhance the relevance of courting matches, we use an AI mannequin to advocate potential matches based mostly on shared non secular views from customers. Let’s check out the next coaching config instance for this mannequin that makes use of faith knowledge:
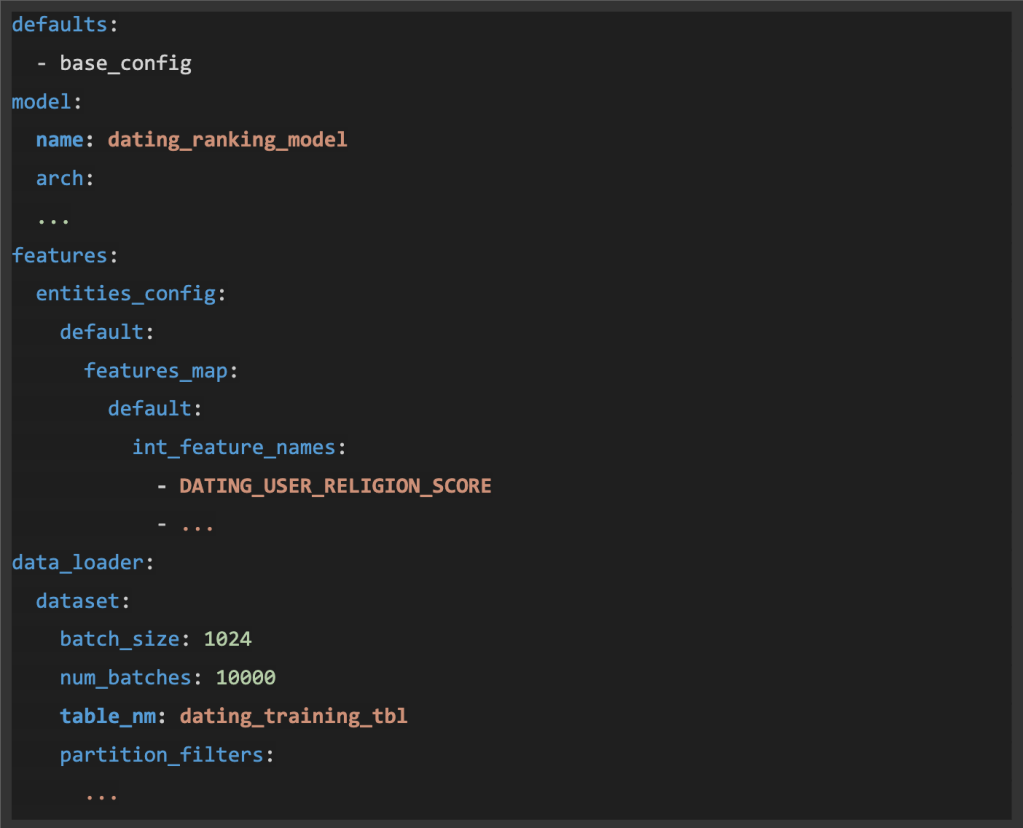
By parsing this config obtained from the mannequin coaching service, we are able to monitor the info circulate from the enter dataset (with asset ID asset://hive.desk/dating_training_tbl) and have (with asset ID asset://ai.function/DATING_USER_RELIGION_SCORE) to the mannequin (with asset ID asset://ai.mannequin/dating_ranking_model).
Our AI methods are additionally instrumented in order that asset relationships and knowledge circulate alerts are captured at numerous factors at runtime, together with data-loading layers (e.g., DPP) and libraries (e.g., PyTorch), workflow engines (e.g., FBLearner Flow), coaching frameworks, inference methods (as backend providers), and so on. Lineage assortment for backend providers makes use of the strategy for function-based methods described above. By matching the supply and sink property for various knowledge circulate alerts, we’re in a position to seize a holistic lineage graph on the desired granularities:
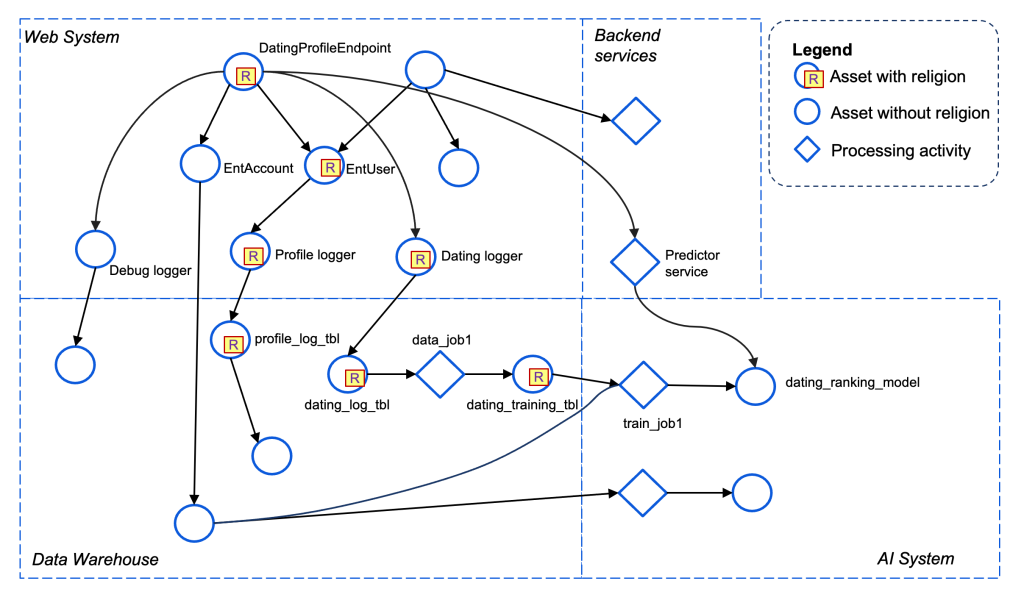
Figuring out related knowledge flows from a lineage graph
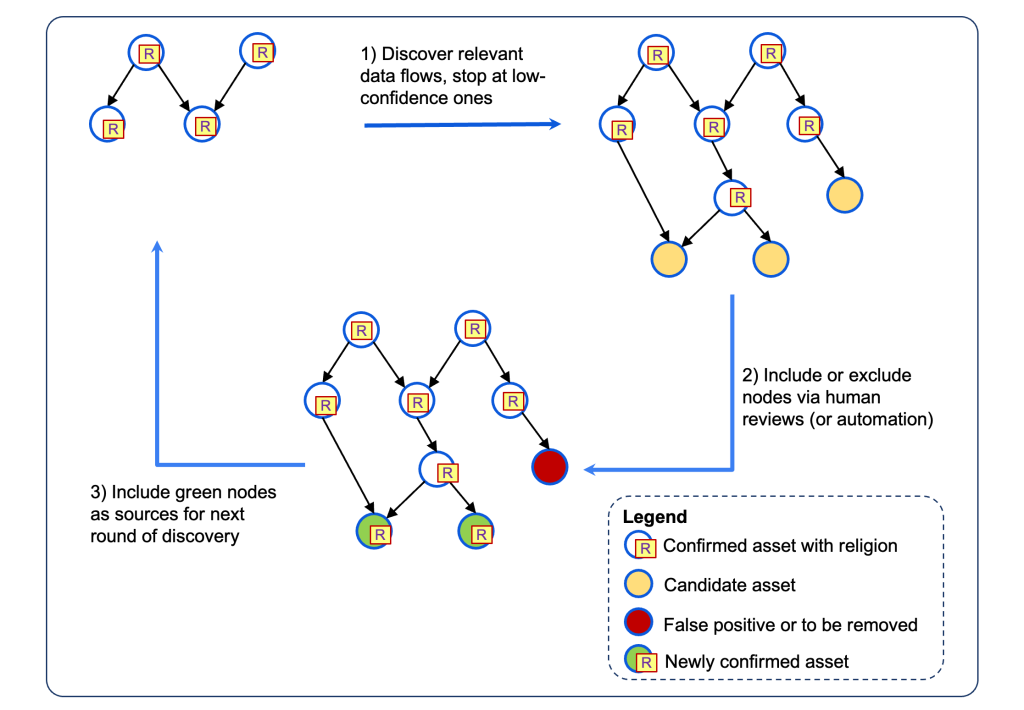
Now that we’ve the lineage graph at our disposal, how can we successfully distill a subset of knowledge flows pertinent to a particular privateness requirement for faith knowledge? To handle this query, we’ve developed an iterative evaluation device that allows builders to pinpoint exact knowledge flows and systematically filter out irrelevant ones. The device kicks off a repetitive discovery course of aided by the lineage graph and privateness controls from Coverage Zones, to slender down essentially the most related flows. This refined knowledge permits builders to make a last dedication in regards to the flows they wish to use, producing an optimum path for traversing the lineage graph. The next are the main steps concerned, captured holistically within the diagram, beneath:
- Uncover knowledge flows: determine knowledge flows from supply property and cease at downstream property with low-confidence flows (yellow nodes).
- Exclude and embody candidates: Builders or automated heuristics exclude candidates (purple nodes) that don’t have faith knowledge or embody remaining ones (inexperienced nodes). By excluding the purple nodes early on, it helps to exclude all of their downstream in a cascaded method, and thus saves developer efforts considerably. As a further safeguard, builders additionally implement privateness controls through Coverage Zones, so all related knowledge flows will be captured.
- Repeat discovery cycle: use the inexperienced nodes as new sources and repeat the cycle till no extra inexperienced nodes are confirmed.
With the gathering and knowledge circulate identification steps full, builders are in a position to efficiently find granular knowledge flows that include faith throughout Meta’s complicated methods, permitting them to maneuver ahead within the PAI workflow to use mandatory privateness controls to safeguard the info. This once-intimidating process has been accomplished effectively.
Our knowledge lineage expertise has supplied builders with an unprecedented capability to shortly perceive and defend faith and comparable delicate knowledge flows. It allows Meta to scalably and effectively implement privateness controls through PAI to guard our customers’ privateness and ship merchandise safely.
Learnings and challenges
As we’ve labored to develop and implement lineage as a core PAI expertise, we’ve gained useful insights and overcome important challenges, yielding some necessary classes:
- Deal with lineage early and reap the rewards: As we developed privateness applied sciences like Coverage Zones, it grew to become clear that gaining a deep understanding of knowledge flows throughout numerous methods is crucial for scaling the implementation of privateness controls. By investing in lineage, we not solely accelerated the adoption of Coverage Zones but additionally uncovered new alternatives for making use of the expertise. Lineage may also be prolonged to different use circumstances equivalent to safety and integrity.
- Construct lineage consumption instruments to achieve engineering effectivity: We initially centered on constructing a lineage answer however didn’t give enough consideration to consumption instruments for builders. In consequence, house owners had to make use of uncooked lineage alerts to find related knowledge flows, which was overwhelmingly complicated. We addressed this subject by creating the iterative tooling to information engineers in discovering related knowledge flows, considerably decreasing engineering efforts by orders of magnitude.
- Combine lineage with methods to scale the protection: Amassing lineage from various Meta methods was a major problem. Initially, we tried to ask each system to gather lineage alerts to ingest into the centralized lineage service, however the progress was sluggish. We overcame this by creating dependable, computationally environment friendly, and extensively relevant PAI libraries with built-in lineage assortment logic in numerous programming languages (Hack, C++, Python, and so on.). This enabled a lot smoother integration with a broad vary of Meta’s methods.
- Measurement improves our outcomes: By incorporating the measurement of protection, we’ve been in a position to evolve our knowledge lineage in order that we keep forward of the ever-changing panorama of knowledge and code at Meta. By enhancing our alerts and adapting to new applied sciences, we are able to preserve a robust concentrate on privateness outcomes and drive ongoing enhancements in lineage protection throughout our tech stacks.
The way forward for knowledge lineage
Information lineage is an important part of Meta’s PAI initiative, offering a complete view of how knowledge flows throughout totally different methods. Whereas we’ve made important progress in establishing a robust basis, our journey is ongoing. We’re dedicated to:
- Increasing protection: repeatedly improve the protection of our knowledge lineage capabilities to make sure a complete understanding of knowledge flows.
- Enhancing consumption expertise: streamline the consumption expertise to make it simpler for builders and stakeholders to entry and make the most of knowledge lineage data.
- Exploring new frontiers: examine new purposes and use circumstances for knowledge lineage, driving innovation and collaboration throughout the business.
By advancing knowledge lineage, we goal to foster a tradition of privateness consciousness and drive progress within the broader fields of research. Collectively, we are able to create a extra clear and accountable knowledge ecosystem.
Acknowledgements
The authors wish to acknowledge the contributions of many present and former Meta workers who’ve performed a vital function in creating knowledge lineage applied sciences over time. Specifically, we wish to lengthen particular due to (in alphabetical order) Amit Jain, Aygun Aydin, Ben Zhang, Brian Romanko, Brian Spanton, Daniel Ramagem, David Molnar, Dzmitry Charnahalau, Gayathri Aiyer, George Stasa, Guoqiang Jerry Chen, Graham Bleaney, Haiyang Han, Howard Cheng, Ian Carmichael, Ibrahim Mohamed, Jerry Pan, Jiang Wu, Jonathan Bergeron, Joanna Jiang, Jun Fang, Kiran Badam, Komal Mangtani, Kyle Huang, Maharshi Jha, Manuel Fahndrich, Marc Celani, Lei Zhang, Mark Vismonte, Perry Stoll, Pritesh Shah, Qi Zhou, Rajesh Nishtala, Rituraj Kirti, Seth Silverman, Shelton Jiang, Sushaant Mujoo, Vlad Fedorov, Yi Huang, Xinbo Gao, and Zhaohui Zhang. We might additionally like to precise our gratitude to all reviewers of this put up, together with (in alphabetical order) Aleksandar Ilic, Avtar Brar, Benjamin Renard, Bogdan Shubravyi, Brianna O’Steen, Chris Wiltz, Daniel Chamberlain, Hannes Roth, Imogen Barnes, Jason Hendrickson, Koosh Orandi, Rituraj Kirti, and Xenia Habekoss. We wish to particularly thank Jonathan Bergeron for overseeing the hassle and offering the entire steerage and useful suggestions, Supriya Anand for main the editorial effort to form the weblog content material, and Katherine Bates for pulling all required assist collectively to make this weblog put up occur.









![How to Start a Personal Training Business [With Plan]](https://oneai.live/wp-content/uploads/2025/01/How-to-Start-A-Personal-Training-Business-With-Plan-120x86.png)

{kind=link}