We launched Meta AI with the purpose of giving individuals new methods to be extra productive and unlock their creativity with generative AI (GenAI). However GenAI additionally comes with challenges of scale. As we deploy new GenAI applied sciences at Meta, we additionally concentrate on delivering these providers to individuals as shortly and effectively as doable.
Meta AI’s animate function, which lets individuals generate a brief animation of a generated picture, carried distinctive challenges on this regard. To deploy and run at scale, our mannequin to generate picture animations had to have the ability to serve billions of people that use our services and products, achieve this shortly – with quick technology instances and minimal errors, and stay useful resource environment friendly.
Right here’s how we have been in a position to deploy Meta AI’s animate function utilizing a mix of latency optimizations, site visitors administration, and different novel methods.
Optimizing latency for producing picture animations
Earlier than launching the animate function throughout our household of apps and on the Meta AI web site, making animation fashions quick was one among our prime priorities. We wished individuals to see the magic of requesting an animation and seeing it seem in only a few seconds. Not solely was this vital from a person perspective, however the sooner and extra environment friendly we made our mannequin, the extra we may do with fewer GPUs, serving to us scale in a sustainable means. Our work in creating animated stickers with video diffusion, accelerating picture technology with Imagine Flash, and accelerating diffusion models through block caching all helped us develop novel methods we used to perform giant latency wins.
Halving floating-point precision
The primary of these optimization methods concerned halving floating-point precision. We transformed the mannequin from float32 to float16, which hurries up the inference time for 2 causes. First, the reminiscence footprint of the mannequin is halved. Second, 16 floating-point operations may be executed sooner than 32. For all fashions, to seize these advantages we use bfloat16, a float16 variant with a smaller mantissa for coaching and inference.
Bettering temporal-attention enlargement
The second optimization improved temporal-attention enlargement. Temporal-attention layers, that are attending between the time axis and textual content conditioning, require the context tensors to be replicated to match the time dimension, or the variety of frames. Beforehand, this might be finished earlier than passing to cross-attention layers. Nevertheless, this leads to less-than-optimal efficiency features. The optimized implementation we went with reduces compute and reminiscence by benefiting from the truth that the repeated tensors are similar, permitting for enlargement to happen after passing by means of the cross-attention’s linear projection layers.
Leveraging DPM-Solver to scale back sampling steps
The third optimization utilized DPM-Solver. Diffusion probabilistic fashions (DPMs) are highly effective and influential fashions that may produce extraordinarily high-quality generations—however they are often gradual. Different doable options, resembling denoising diffusion-implicit fashions or denoising diffusion-probabilistic fashions, can present high quality technology however on the computational value of extra sampling steps. We leveraged DPM-Solver and a linear-in-log signal-to-noise time to scale back the variety of sampling steps to fifteen.
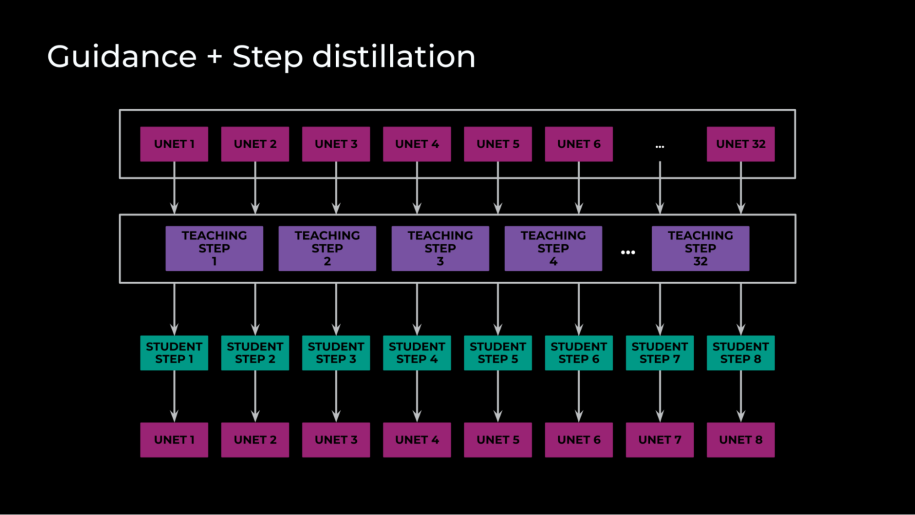
Combining steerage and step distillation
The fourth optimization we applied mixed steerage and step distillation. We achieved step distillation by initializing a trainer and pupil with the identical weights, after which educated the scholar to match a number of trainer steps in a single step. Steering distillation, in distinction, refers to how diffusion fashions leverage a classifier-free steerage for conditional picture technology. This requires each a conditional and unconditional ahead cross for each solver step.
In our case, nonetheless, we had three ahead passes per step: an unconditional, an image-conditional, and a full-conditional, text-and-image step. Steering distillation decreased these three ahead passes into one, chopping inference by an element of three. The actual magic right here, although, was combining these two optimizations. By coaching a pupil to mimic the classifier-free steerage and a number of steps on the identical time with one ahead cross by means of the U-Internet, our closing mannequin required solely eight solver steps, with only one ahead cross by means of the U-Internet per step. Ultimately, throughout coaching we distilled 32 trainer steps into eight pupil steps.
PyTorch optimizations
The ultimate optimization pertains to deployment and structure and includes two transformations. The primary was leveraging torch scripting and freezing. By changing the mannequin to TorchScript, we achieved many computerized optimizations. These included steady folding, fusing a number of operations, and lowering the complexity of the computational graph. These three optimizations helped to extend inference velocity, whereas freezing allowed additional optimization by remodeling dynamically computed values within the graph to constants, lowering the overall variety of operations.
Whereas these optimizations have been crucial for our preliminary launch, now we have continued to push the boundaries. For instance, now we have since migrated all of our media inference from TorchScript to make use of a PyTorch 2.0-based resolution, and this resulted in a number of wins for us. We have been in a position to optimize mannequin parts at a extra granular degree with pytorch.compile on the part degree, in addition to allow superior optimization methods resembling context parallel and sequence parallel within the new structure. This led to extra wins, from lowering the event time of superior options to enhancements in tracing and to having the ability to assist multi-GPU inference.
Deploying and working picture animation at scale
As soon as we had totally optimized the mannequin, we had a brand new set of challenges to sort out. How may we run this mannequin at scale to assist site visitors from all over the world, all whereas sustaining quick technology time with minimal failures and making certain that GPUs can be found for all different vital use instances across the firm?
We began by trying on the knowledge for earlier site visitors on our AI-generated media each at their launches and over time. We used this information to calculate tough estimates of the amount of requests we may anticipate, after which used our benchmarking of mannequin velocity to find out what number of GPUs can be wanted to accommodate that amount. As soon as we’d scaled that up, we started working load checks to see if we may deal with a spread of site visitors ranges, addressing the assorted bottlenecks till we have been in a position to deal with the site visitors projected for launch.
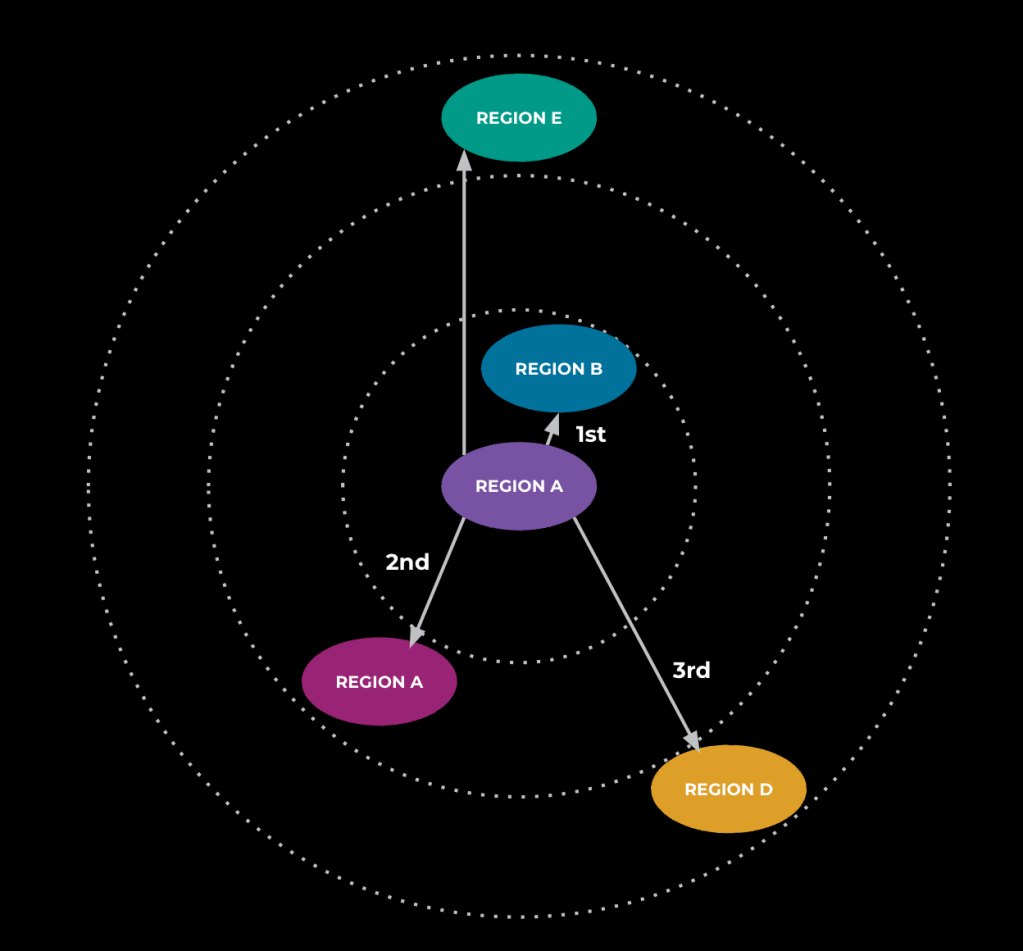
Throughout this testing, we seen that the end-to-end latency of an animation request was larger than anticipated—in addition to larger than what we had seen after constructing in all of the optimizations described above. Our investigations yielded that site visitors was being routed globally, leading to important community and communication overhead and including seconds to the end-to-end technology time. To deal with this, we utilized a site visitors administration system that fetches the service’s site visitors or load knowledge and makes use of that to calculate a routing desk. The first goal of the routing desk is to maintain as many requests as doable in the identical area as their requester to keep away from having site visitors throughout areas like we have been seeing earlier than. The routing desk additionally leverages our predefined load thresholds and routing rings to stop overload by offloading site visitors to different areas when nearing most capability in a area. With these modifications, the preponderance of requests remained in area and latency dropped to roughly what we’d anticipate.
Various shifting components make this service work. First, it takes every of the metrics that we outline for a tier, fetches the worth of every from the tier’s machines, and aggregates it by area. It then collects the variety of requests per second that every area sends to each different area and makes use of that to calculate the request-per-second load value. This tells the system that, usually talking, the load will improve by X for each added request per second. As soon as that is full, the algorithm begins, first by bringing all of the site visitors to the supply area. We don’t but test if the area has sufficient capability or not.
The following step is to enter a loop the place throughout each iteration we have a look at which area is working closest to most capability. The service tries to take a piece of that area’s requests and offload them to a close-by area that may deal with them with out turning into extra overloaded. Varied ranges of overload decide how distant we think about when taking a look at close by areas. For instance, if the principle area is barely simply beginning to run sizzling, solely the closest areas is likely to be utilized. If the area is working at nearly most capability, farther-away areas could also be unlocked for offloading. We’ll exit the loop if there are not any extra requests that may be moved between areas, which happens both when each area is under the outlined “overload” threshold or there are not any extra close by areas the service can offload to as a result of all close by areas are additionally above the edge. At this level, the service will calculate the optimum variety of requests per second for every area and use that to create the routing desk talked about above so our service can appropriately decide the place to ship site visitors at request time.
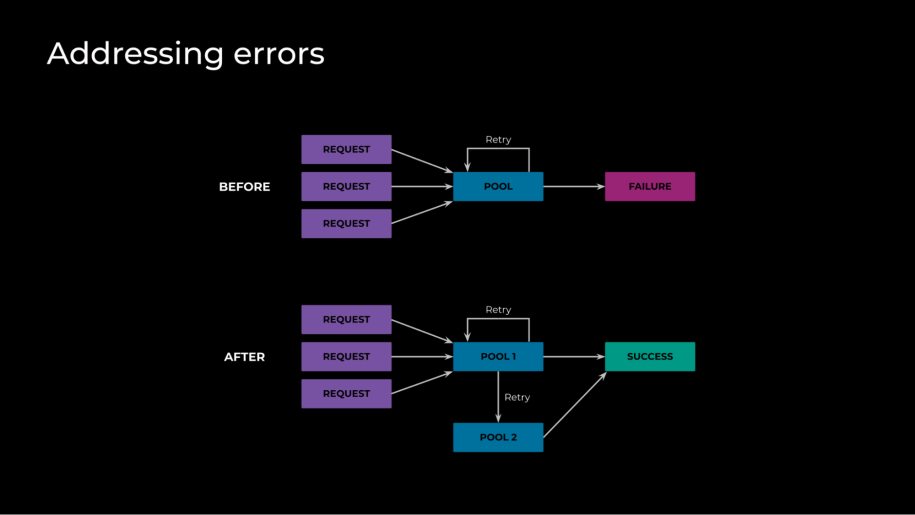
With these optimizations in place, latency returned to ranges that we have been proud of, however we have been seeing a dip in success charge. At a excessive degree, every GPU can solely actively work on one request at a time, as every request totally saturates the GPU. To take care of quick latency, it’s crucial that we don’t enable requests to queue up—in any other case, they’ll have an extended wait time. To implement this we made certain that the server load—queued requests plus in-flight requests—is at most one, and that the server rejects different new requests. Due to this, nonetheless, once we are working close to our capability restrict, we are going to run into numerous failures. The naive resolution to this challenge can be to make use of a queue, however as a result of having to load stability globally, that presents its personal units of advanced challenges to being environment friendly and quick. What we used as an alternative was approximating by abusing retries to create a probing system that checks totally free GPUs actually quick and prevents failures.
This labored nicely earlier than we applied the site visitors administration system. That system, whereas efficient at lowering latency, launched extra issues by lowering the variety of out there hosts for a request, since we now not had the worldwide routing. We seen that the retry polling was now not being useful and really tended to cascade if there have been any spikes. Additional investigation led us to find that our router wanted to have extra optimized settings for retries. It had neither delay nor backoff. So if we had a area the place numerous duties have been making an attempt to run, it was caught overloading till it began failing requests. To keep away from the cascading errors, we modified these retry settings so as to add a marginal execution delay to a proportion of jobs at scheduling time—making them out there to execute steadily as an alternative of all of sudden—in addition to an exponential backoff.
As soon as all of this was finished, we had a deployed mannequin that was extremely environment friendly, functioned at scale, and will deal with international site visitors with excessive availability and a minimal failure charge.
Learn extra
To be taught extra about our work creating and deploying GenAI to animate photos, learn:
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
Cache Me if You Can: Accelerating Diffusion Models through Block Caching











{kind=link}