![]()
Gemma is a household of open fashions constructed from the identical analysis and know-how used to create the Gemini fashions. Gemma fashions are able to performing a variety of duties, together with textual content technology, code completion and technology, fine-tuning for particular duties, and working on varied units.
Ray is an open-source framework for scaling AI and Python functions. Ray offers the infrastructure to carry out distributed computing and parallel processing in your machine studying (ML) workflow.
By the tip of this tutorial, you will have a stable understanding of how you can use Gemma Supervised tuning on Ray on Vertex AI to coach and serve machine studying fashions effectively and successfully.
You possibly can discover the “Get started with Gemma on Ray on Vertex AI” tutorial pocket book on GitHub to be taught extra about Gemma on Ray. All of the code under is on this pocket book to make your journey simpler.
Prerequisite
The next steps are required, no matter your atmosphere.
2. Make sure that billing is enabled for your project.
3. Enable APIs.
In the event you’re working this tutorial domestically, it’s worthwhile to set up the Cloud SDK.
Prices
This tutorial makes use of billable elements of Google Cloud:
Find out about pricing, use the Pricing Calculator to generate a price estimate based mostly in your projected utilization.
What you want
Dataset
We’ll use the Extreme Summarization (XSum) dataset, which is a dataset about abstractive single-document summarization techniques.
Cloud Storage Bucket
It’s important to create a storage bucket to retailer intermediate artifacts comparable to datasets.
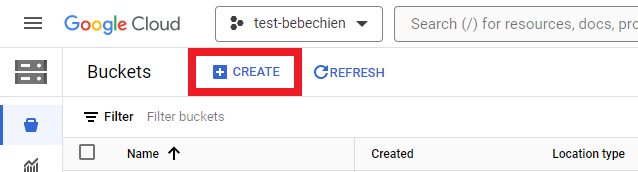
gsutil mb -l {REGION} -p {PROJECT_ID} {BUCKET_URI}
# for instance: gsutil mb -l asia-northeast1 -p test-bebechien gs://test-bebechien-ray-bucket
Docker Picture Repository
To retailer the customized cluster picture, create a Docker repository within the Artifact Registry.
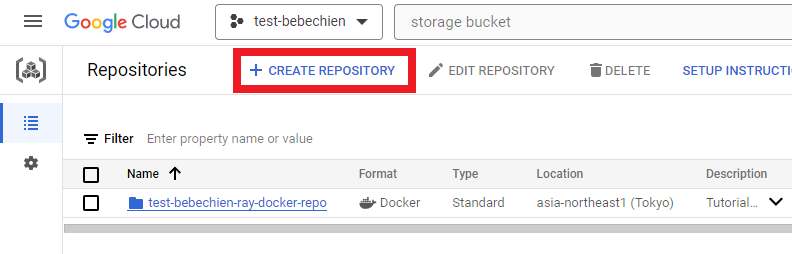
gcloud artifacts repositories create your-repo --repository-format=docker --location=your-area --description="Tutorial repository"
Vertex AI TensorBoard Occasion
A TensorBoard occasion is for monitoring and monitoring your tuning jobs. You possibly can create one from Experiments.
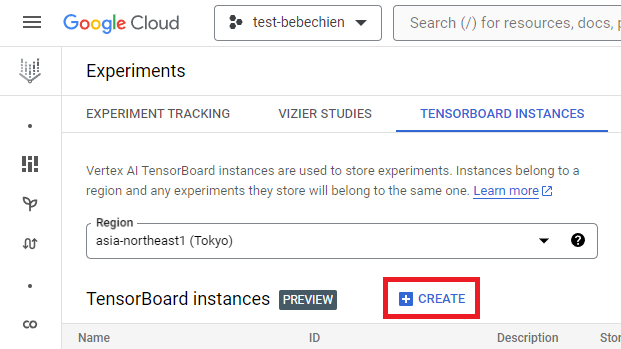
gcloud ai tensorboards create --show-title your-tensorboard --undertaking your-undertaking --area your-area
Easy methods to set a Ray cluster on Vertex AI
Construct the customized cluster picture
To get began with Ray on Vertex AI, you possibly can select to both create a Dockerfile for a customized picture from scratch or make the most of one of many pre-built Ray base pictures. One such base picture is offered here.
First, put together the necessities file that features the dependencies your Ray utility must run.
Then, create the Dockerfile for the customized picture by leveraging one of many prebuilt Ray on Vertex AI base pictures.
Lastly, construct the Ray cluster customized picture utilizing Cloud Construct.
gcloud builds submit --area=your-area
--tag=your-area-docker.pkg.dev/your-undertaking/your-repo/prepare --machine-sort=E2_HIGHCPU_32 ./dockerfile-path
If every little thing goes effectively, you’ll see the customized picture has been efficiently pushed to your docker picture repository.
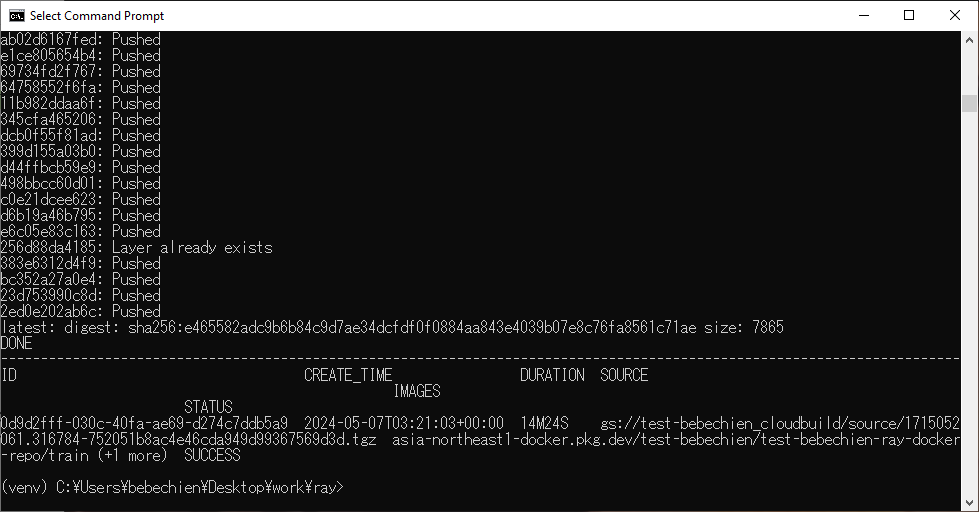
Additionally in your Artifact Registry
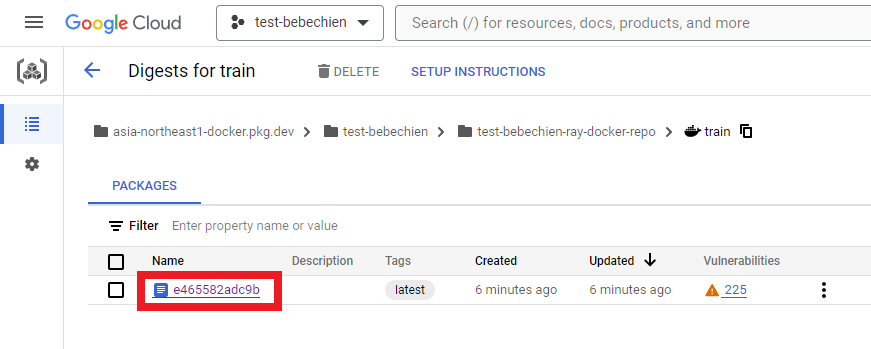
Create the Ray Cluster
You possibly can create the ray cluster from Ray on Vertex AI.
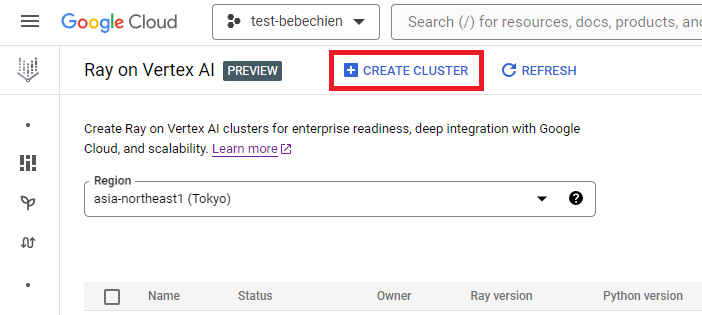
Or use the Vertex AI Python SDK to create a Ray cluster with a customized picture and to customise the cluster configuration. To be taught extra concerning the cluster configuration, see the documentation.
Under is an instance Python code to create the Ray cluster with the predefined customized configuration.
NOTE: Making a cluster can take a number of minutes, relying on its configuration.
# Arrange Ray on Vertex AI
import vertex_ray
from google.cloud import aiplatform as vertex_ai
from vertex_ray import NodeImages, Assets
# Retrieves an present managed tensorboard given a tensorboard ID
tensorboard = vertex_ai.Tensorboard(your-tensorboard-id, undertaking=your-undertaking, location=your-area)
# Initialize the Vertex AI SDK for Python in your undertaking
vertex_ai.init(undertaking=your-undertaking, location=your-area, staging_bucket=your-bucket-uri, experiment_tensorboard=tensorboard)
HEAD_NODE_TYPE = Assets(
machine_type= "n1-standard-16",
node_count=1,
)
WORKER_NODE_TYPES = [
Resources(
machine_type="n1-standard-16",
node_count=1,
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=2,
)
]
CUSTOM_IMAGES = NodeImages(
head="your-region-docker.pkg.dev/your-project/your-repo/prepare",
employee="your-region-docker.pkg.dev/your-project/your-repo/prepare",
)
ray_cluster_name = vertex_ray.create_ray_cluster(
head_node_type=HEAD_NODE_TYPE,
worker_node_types=WORKER_NODE_TYPES,
custom_images=CUSTOM_IMAGES,
cluster_name=”your-cluster-title”,
)
Now you will get the Ray cluster with get_ray_cluster(). Use list_ray_clusters() if you wish to see all clusters related together with your undertaking.
ray_clusters = vertex_ray.list_ray_clusters()
ray_cluster_resource_name = ray_clusters[-1].cluster_resource_name
ray_cluster = vertex_ray.get_ray_cluster(ray_cluster_resource_name)
print("Ray cluster on Vertex AI:", ray_cluster_resource_name)
Wonderful-Tune Gemma with Ray on Vertex AI
To fine-tune Gemma with Ray on Vertex AI, you should use Ray Train for distributing HuggingFace Transformers with PyTorch coaching, as you possibly can see under.
With Ray Prepare, you outline a coaching operate which accommodates your HuggingFace Transformers code for tuning Gemma that you simply need to distribute. Subsequent, you outline the scaling configuration to specify the specified variety of staff and point out whether or not the distributed coaching course of requires GPUs. Moreover, you possibly can outline a runtime configuration to specify checkpointing and synchronization behaviors. Lastly, you submit the fine-tuning by initiating a TorchTrainer and run it utilizing its match technique.
On this tutorial, we’ll fine-tune Gemma 2B (gemma-2b-it) for summarizing newspaper articles utilizing HuggingFace Transformer on Ray on Vertex AI. We wrote a easy Python coach.py script and can submit it to the Ray cluster.
Put together Python Scripts
Let’s put together the prepare script, under is an instance Python script for initializing Gemma fine-tuning utilizing HuggingFace TRL library.
Subsequent, put together the distributed coaching script. Under is an instance Python script for executing the Ray distributed coaching job.
Now we submit the script to the Ray cluster utilizing the Ray Jobs API through the Ray dashboard tackle. It’s also possible to discover the dashboard tackle on the Cluster details page like under.
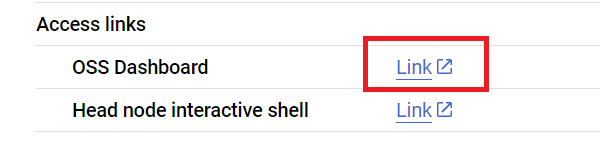
First, provoke the shopper to submit the job.
import ray
from ray.job_submission import JobSubmissionClient
shopper = JobSubmissionClient(
tackle="vertex_ray://{}".format(ray_cluster.dashboard_address)
)
Let’s set some job configuration together with mannequin path, job id, prediction entrypoint, and extra.
import random, string, datasets, transformers
from etils import epath
from huggingface_hub import login
# Initialize some libraries settings
login(token=”your-hf-token”)
datasets.disable_progress_bar()
transformers.set_seed(8)
train_experiment_name = “your-experiment-title”
train_submission_id = “your-submission-id”
train_entrypoint = f"python3 coach.py --experiment-name={train_experiment_name} --logging-dir=”your-bucket-uri/logs” --num-workers=2 --use-gpu"
train_runtime_env = {
"working_dir": "your-working-dir",
"env_vars": {"HF_TOKEN": ”your-hf-token”, "TORCH_NCCL_ASYNC_ERROR_HANDLING": "3"},
}
train_job_id = shopper.submit_job(
submission_id=train_submission_id,
entrypoint=train_entrypoint,
runtime_env=train_runtime_env,
)
Test the standing of the job from the OSS dashboard.
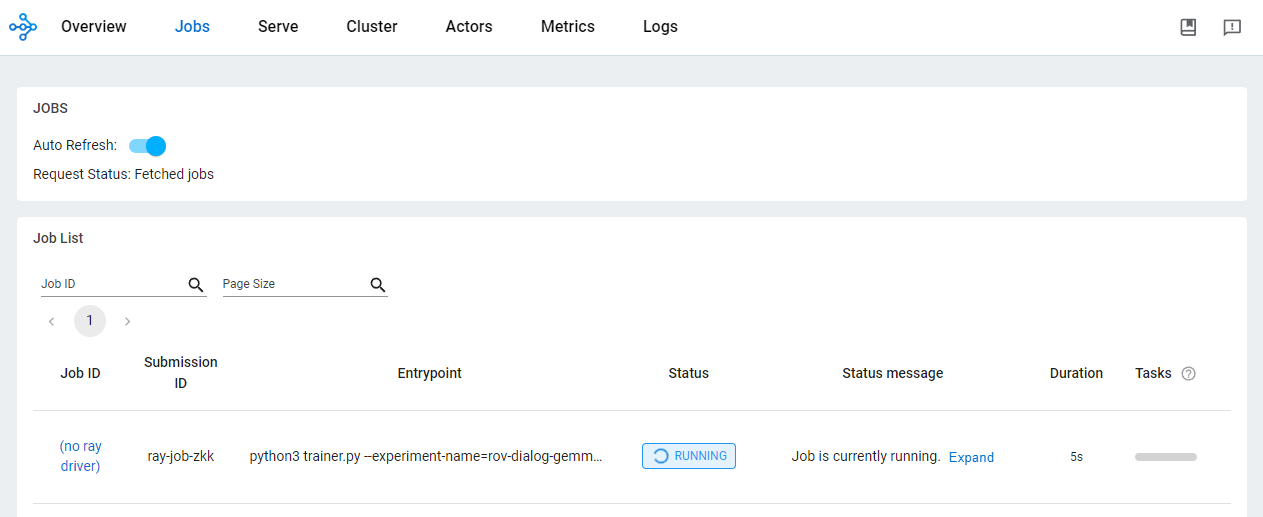
Test coaching artifacts and monitor the coaching
Utilizing Ray on Vertex AI for creating AI/ML functions provides varied advantages. On this state of affairs, you should use Cloud storage to conveniently retailer mannequin checkpoints, metrics, and extra. This lets you shortly eat the mannequin for AI/ML downstreaming duties together with monitoring the coaching course of utilizing Vertex AI TensorBoard or producing batch predictions utilizing Ray Information.
Whereas the Ray coaching job is working and after it has accomplished, you see the mannequin artifacts within the Cloud Storage location with Google Cloud CLI.
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-title
You need to use Vertex AI TensorBoard for validating your coaching job by logging ensuing metrics.
vertex_ai.upload_tb_log(
tensorboard_id=tensorboard.title,
tensorboard_experiment_name=train_experiment_name,
logdir=./experiments,
)
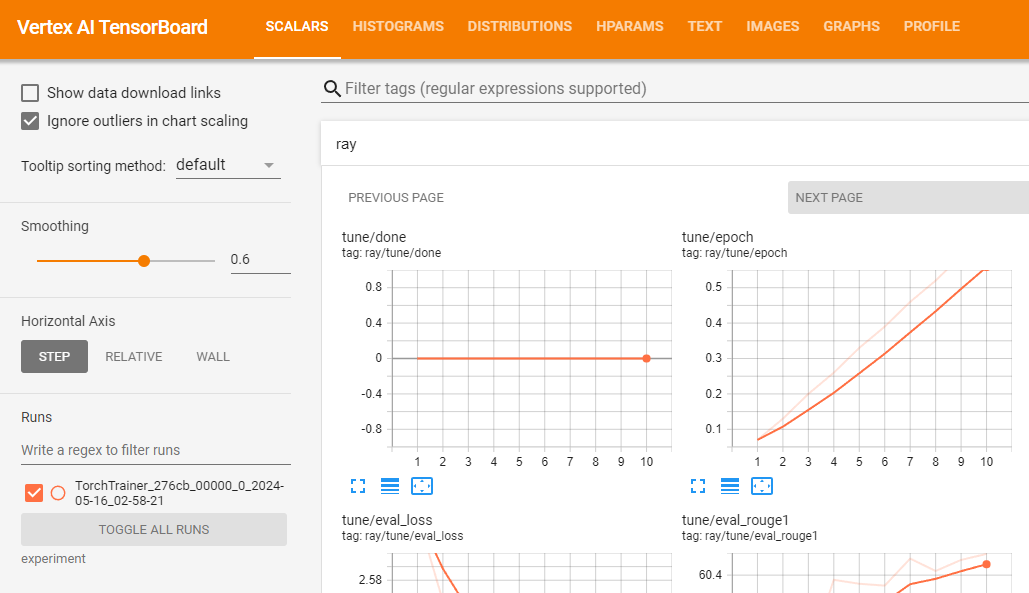
Validate Gemma coaching on Vertex AI
Assuming that your coaching runs efficiently, you possibly can generate predictions domestically to validate the tuned mannequin.
First, obtain all ensuing checkpoints from Ray job with Google Cloud CLI.
# copy all artifacts
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-title ./your-experiment-path
Use the ExperimentAnalysis technique to retrieve the very best checkpoint based on related metrics and mode.
import ray
from ray.tune import ExperimentAnalysis
experiment_analysis = ExperimentAnalysis(“./your-experiment-path”)
log_path = experiment_analysis.get_best_trial(metric="eval_rougeLsum", mode="max")
best_checkpoint = experiment_analysis.get_best_checkpoint(
log_path, metric="eval_rougeLsum", mode="max"
)
Now you realize which one is the very best checkpoint. Under is an instance output.

And cargo the fine-tuned mannequin as described within the Hugging Face documentation.
Under is an instance Python code to load the bottom mannequin and merge the adapters into the bottom mannequin so you should use the mannequin like a traditional transformers mannequin. Yow will discover the saved tuned mannequin at tuned_model_path. For instance, “tutorial/fashions/xsum-tuned-gemma-it”
import torch
from etils import epath
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model_path = "google/gemma-2b-it"
peft_model_path = epath.Path(best_checkpoint.path) / "checkpoint"
tuned_model_path = models_path / "xsum-tuned-gemma-it"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.padding_side = "proper"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path, device_map="auto", torch_dtype=torch.float16
)
peft_model = PeftModel.from_pretrained(
base_model,
peft_model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
is_trainable=False,
)
tuned_model = peft_model.merge_and_unload()
tuned_model.save_pretrained(tuned_model_path)
Tidbit: Because you tremendous tuned a mannequin, it’s also possible to publish it to the Hugging Face Hub through the use of this single line of code.
tuned_model.push_to_hub("my-awesome-model")
To generate summaries with the tuned mannequin, let’s use the validation set of the tutorial dataset.
The next Python code instance demonstrates how you can pattern one article from a dataset to summarize. It then generates the related abstract and prints each the reference abstract from the dataset and the generated abstract aspect by aspect.
import random, datasets
from transformers import pipeline
dataset = datasets.load_dataset(
"xsum", break up="validation", cache_dir=”./information”, trust_remote_code=True
)
pattern = dataset.choose([random.randint(0, len(dataset) - 1)])
doc = pattern["document"][0]
reference_summary = pattern["summary"][0]
messages = [
{
"role": "user",
"content": f"Summarize the following ARTICLE in one sentence.n###ARTICLE: {document}",
},
]
immediate = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
tuned_gemma_pipeline = pipeline(
"text-generation", mannequin=tuned_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_tuned_gemma_summary = tuned_gemma_pipeline(
immediate, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference abstract: {reference_summary}")
print("-" * 100)
print(f"Tuned generated abstract: {generated_tuned_gemma_summary}")
Under is an instance output from the tuned mannequin. Notice that the tuned consequence may require additional refinement. To realize optimum high quality, it is necessary to iterate by means of the method a number of instances, adjusting components comparable to the training price and the variety of coaching steps.

Consider the tuned mannequin
As a further step, you possibly can consider the tuned mannequin. To guage the mannequin you examine fashions qualitatively and quantitatively.
In a single case, you examine responses generated by the bottom Gemma mannequin with those generated by the tuned Gemma mannequin. Within the different case, you calculate ROUGE metrics and its enhancements which supplies you an concept of how effectively the tuned mannequin is ready to reproduce the reference summaries appropriately with respect to the bottom mannequin.
Under is a Python code to judge fashions by evaluating generated summaries.
gemma_pipeline = pipeline(
"text-generation", mannequin=base_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_gemma_summary = gemma_pipeline(
immediate, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference abstract: {reference_summary}")
print("-" * 100)
print(f"Base generated abstract: {generated_gemma_summary}")
print("-" * 100)
print(f"Tuned generated abstract: {generated_tuned_gemma_summary}")
Under is an instance output from the bottom mannequin and tuned mannequin.
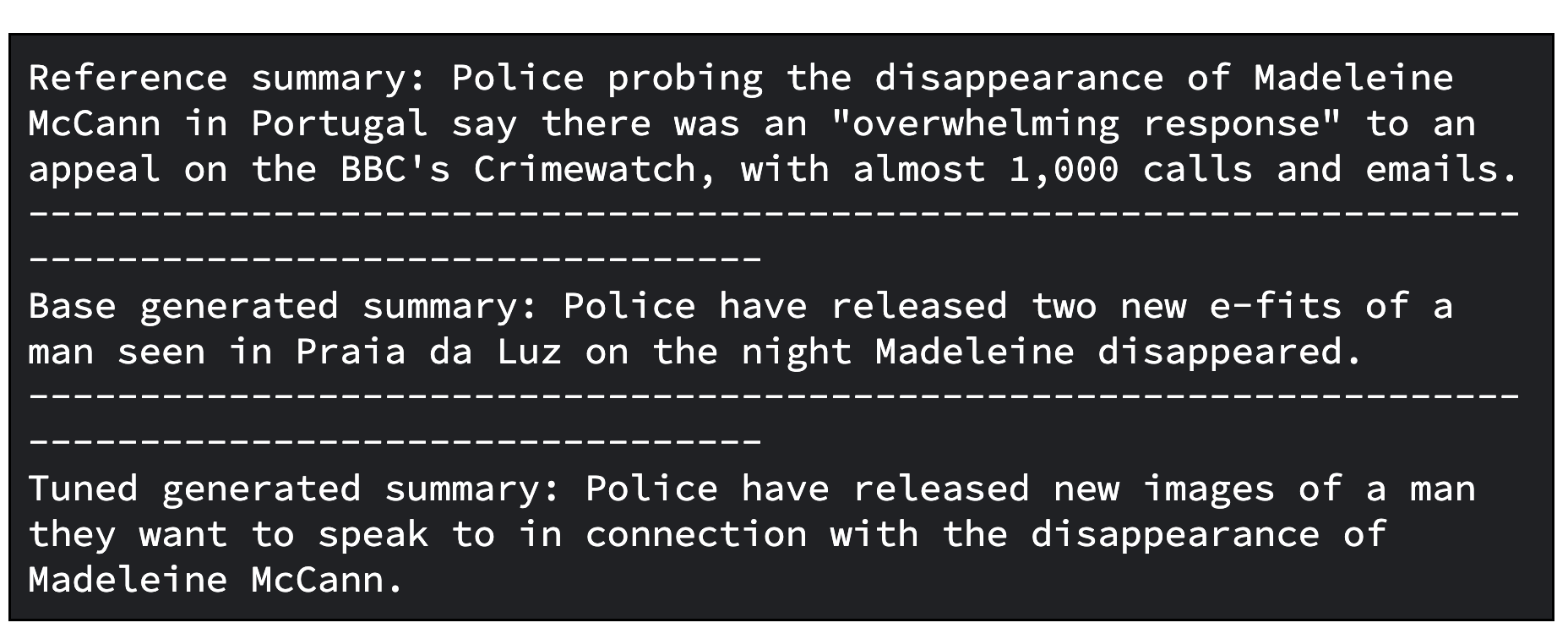
And under is a code to judge fashions by computing ROUGE metrics and its enhancements.
import consider
rouge = consider.load("rouge")
gemma_results = rouge.compute(
predictions=[generated_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
tuned_gemma_results = rouge.compute(
predictions=[generated_tuned_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
enhancements = {}
for rouge_metric, gemma_rouge in gemma_results.gadgets():
tuned_gemma_rouge = tuned_gemma_results[rouge_metric]
if gemma_rouge != 0:
enchancment = ((tuned_gemma_rouge - gemma_rouge) / gemma_rouge) * 100
else:
enchancment = None
enhancements[rouge_metric] = enchancment
print("Base Gemma vs Tuned Gemma - ROUGE enhancements")
for rouge_metric, enchancment in enhancements.gadgets():
print(f"{rouge_metric}: {enchancment:.3f}%")
And the instance output for the analysis.

Serving tuned Gemma mannequin with Ray Information for offline predictions
To generate offline predictions at scale with the tuned Gemma on Ray on Vertex AI, you should use Ray Information, a scalable information processing library for ML workloads.
Utilizing Ray Information for producing offline predictions with Gemma, it’s worthwhile to outline a Python class to load the tuned mannequin in Hugging Face Pipeline. Then, relying in your information supply and its format, you employ Ray Information to carry out distributed information studying and you employ a Ray dataset technique to use the Python class for performing predictions in parallel to a number of batches of information.
Batch prediction with Ray Information
To generate batch prediction with the tuned mannequin utilizing Ray Information on Vertex AI, you want a dataset to generate predictions and the tuned mannequin saved within the Cloud bucket.
Then, you possibly can leverage Ray Information which offers an easy-to-use API for offline batch inference.
First, add the tuned mannequin on the Cloud storage with Google Cloud CLI
gsutil -q cp -r “./fashions” “your-bucket-uri/fashions”
Put together the batch prediction coaching script file for executing the Ray batch prediction job.
Once more, you possibly can provoke the shopper to submit the job like under with the Ray Jobs API through the Ray dashboard tackle.
import ray
from ray.job_submission import JobSubmissionClient
shopper = JobSubmissionClient(
tackle="vertex_ray://{}".format(ray_cluster.dashboard_address)
)
Let’s set some job configuration together with mannequin path, job id, prediction entrypoint and extra.
import random, string
batch_predict_submission_id = "your-batch-prediction-job"
tuned_model_uri_path = "/gcs/your-bucket-uri/fashions"
batch_predict_entrypoint = f"python3 batch_predictor.py --tuned_model_path={tuned_model_uri_path} --num_gpus=1 --output_dir=”your-bucket-uri/predictions”"
batch_predict_runtime_env = {
"working_dir": "tutorial/src",
"env_vars": {"HF_TOKEN": “your-hf-token”},
}
You possibly can specify the variety of GPUs to make use of with the “–num_gpus” argument. This must be a worth that is the same as or lower than the variety of GPUs out there in your Ray cluster.
And submit the job.
batch_predict_job_id = shopper.submit_job(
submission_id=batch_predict_submission_id,
entrypoint=batch_predict_entrypoint,
runtime_env=batch_predict_runtime_env,
)
Let’s have a fast view of generated summaries utilizing a Pandas DataFrame.
import io
import pandas as pd
from google.cloud import storage
def read_json_files(bucket_name, prefix=None):
"""Reads JSON recordsdata from a cloud storage bucket and returns a Pandas DataFrame"""
# Arrange storage shopper
storage_client = storage.Consumer()
bucket = storage_client.bucket(bucket_name)
blobs = bucket.list_blobs(prefix=prefix)
dfs = []
for blob in blobs:
if blob.title.endswith(".json"):
file_bytes = blob.download_as_bytes()
file_string = file_bytes.decode("utf-8")
with io.StringIO(file_string) as json_file:
df = pd.read_json(json_file, strains=True)
dfs.append(df)
return pd.concat(dfs, ignore_index=True)
predictions_df = read_json_files(prefix="predictions/", bucket_name=”your-bucket-uri”)
predictions_df = predictions_df[
["id", "document", "prompt", "summary", "generated_summary"]
]
predictions_df.head()
And under is an instance output. The default variety of articles to summarize is 20. You possibly can specify the quantity with the “–sample_size” argument.

Abstract
Now you might have discovered many issues together with:
- Easy methods to create a Ray cluster on Vertex AI
- Easy methods to tune Gemma with Ray Prepare on Vertex AI
- Easy methods to validate Gemma coaching on Vertex AI
- Easy methods to consider tuned Gemma mannequin
- Easy methods to serve Gemma with Ray Information for offline predictions
We hope that this tutorial has been enlightening and offered you with helpful insights.
Take into account becoming a member of the Google Developer Community Discord server. It provides a chance to share your initiatives, join with different builders, and have interaction in collaborative discussions.
And don’t neglect to wash up all Google Cloud assets used on this undertaking. You possibly can merely delete the Google Cloud project that you simply used for the tutorial. In any other case, you possibly can delete the person assets that you simply created.
# Delete tensorboard
tensorboard_list = vertex_ai.Tensorboard.record()
for tensorboard in tensorboard_list:
tensorboard.delete()
# Delete experiments
experiment_list = vertex_ai.Experiment.record()
for experiment in experiment_list:
experiment.delete()
# Delete ray on vertex cluster
ray_cluster_list = vertex_ray.list_ray_clusters()
for ray_cluster in ray_cluster_list:
vertex_ray.delete_ray_cluster(ray_cluster.cluster_resource_name)
# Delete artifacts repo
gcloud artifacts repositories delete “your-repo” -q
# Delete Cloud Storage objects that had been created
gsutil -q -m rm -r “your-bucker-uri”
Thanks for studying!










{kind=link}