
Gemma 2 is the newest model in Google’s household of light-weight, state-of-the-art open fashions constructed from the identical analysis and expertise used to create the Gemini fashions. Massive language fashions (LLMs) like Gemma are remarkably versatile, opening up many potential integrations for enterprise processes. This weblog explores how you need to use Gemma to gauge the sentiment of a dialog, summarize that dialog’s content material, and help with making a reply for a tough dialog that may then be authorised by an individual. One of many key necessities is that prospects who’ve expressed a damaging sentiment have their wants addressed in close to real-time, which implies that we might want to make use of a streaming knowledge pipeline that leverages LLM’s with minimal latency.
Gemma
Gemma 2 presents unmatched performance at size. Gemma fashions have been proven to attain distinctive benchmark outcomes , even outperforming some bigger fashions. The small dimension of the fashions allows architectures the place the mannequin is deployed or embedded immediately onto the streaming knowledge processing pipeline, permitting for the advantages, similar to:
- Information locality with native employee calls moderately than RPC of knowledge to a separate system
- A single system to autoscale, permitting the usage of metrics similar to again stress at supply for use as direct alerts to the autoscaler
- A single system to look at and monitor in manufacturing
Dataflow supplies a scalable, unified batch and streaming processing platform. With Dataflow, you need to use the Apache Beam Python SDK to develop streaming knowledge, occasion processing pipelines. Dataflow supplies the next advantages:
- Dataflow is absolutely managed, autoscaling up and down primarily based on demand
- Apache Beam supplies a set of low-code turnkey transforms that may prevent time, effort, and value on writing generic boilerplate code. In spite of everything the perfect code is the one you do not have to jot down
- Dataflow ML immediately helps GPUs, putting in the mandatory drivers and offering entry to a spread of GPU devices
The next instance reveals the right way to embed the Gemma mannequin inside the streaming knowledge pipeline for operating inference utilizing Dataflow.
State of affairs
This situation revolves round a bustling meals chain grappling with analyzing and storing a excessive quantity of buyer help requests by means of numerous chat channels. These interactions embrace each chats generated by automated chatbots and extra nuanced conversations that require the eye of reside help employees. In response to this problem, we have set bold targets:
- First, we need to effectively handle and retailer chat knowledge by summarizing constructive interactions for straightforward reference and future evaluation.
- Second, we need to implement real-time concern detection and backbone, utilizing sentiment evaluation to swiftly establish dissatisfied prospects and generate tailor-made responses to handle their considerations.
The answer makes use of a pipeline that processes accomplished chat messages in close to actual time. Gemma is used within the first occasion to hold out evaluation work monitoring the sentiment of those chats. All chats are then summarized, with constructive or impartial sentiment chats despatched immediately to a knowledge platform, BigQuery, by utilizing the out-of-the-box I/Os with Dataflow. For chats that report a damaging sentiment, we use Gemma to ask the mannequin to craft a contextually acceptable response for the dissatisfied buyer. This response is then despatched to a human for evaluation, permitting help employees to refine the message earlier than it reaches a doubtlessly dissatisfied buyer.
With this use case, we discover some attention-grabbing elements of utilizing an LLM inside a pipeline. For instance, there are challenges with having to course of the responses in code, given the non-deterministic responses that may be accepted. For instance, we ask our LLM to reply in JSON, which it isn’t assured to do. This request requires us to parse and validate the response, which is an analogous course of to how you’ll usually course of knowledge from sources that won’t have accurately structured knowledge.
With this resolution, prospects can expertise quicker response instances and obtain customized consideration when points come up. The automation of constructive chat summarization frees up time for help employees, permitting them to deal with extra complicated interactions. Moreover, the in-depth evaluation of chat knowledge can drive data-driven decision-making whereas the system’s scalability lets it effortlessly adapt to growing chat volumes with out compromising response high quality.
The Information processing pipeline
The pipeline movement may be seen under:
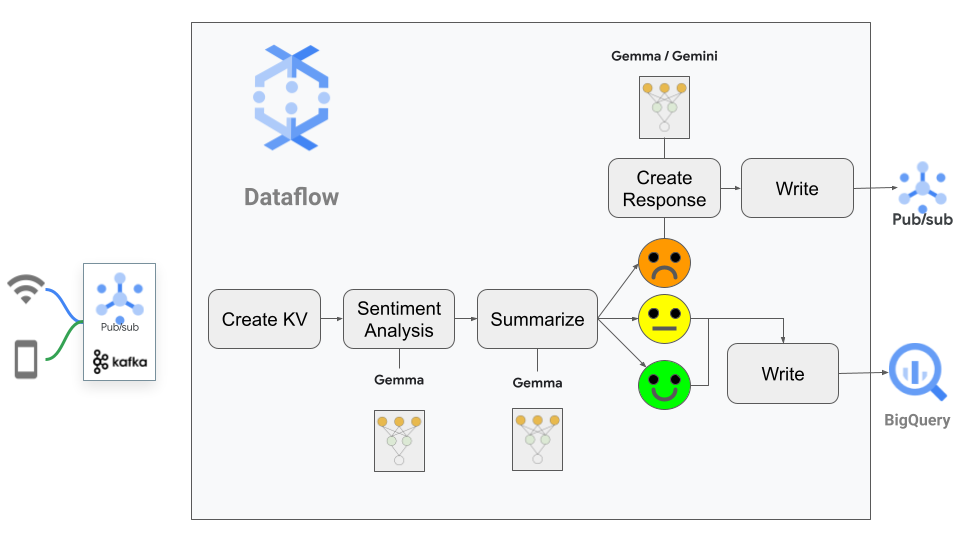
The high-level pipeline may be described with a couple of strains:
- Learn the evaluation knowledge from Pub/Sub, our occasion messaging supply. This knowledge incorporates the chat ID and the chat historical past as a JSON payload. This payload is processed within the pipeline.
2. The pipeline passes the textual content from this message to Gemma with a immediate. The pipeline requests that two duties be accomplished.
- Connect a sentiment rating to the message, utilizing the next three values: 1 for a constructive chat, 0 for a impartial chat, and -1 for a damaging chat.
- Summarize the chat with a single sentence.
3. Subsequent, the pipeline branches, relying on the sentiment rating:
- If the rating is 1 or 0, the chat with summarization is shipped onwards to our knowledge analytics system for storage and future evaluation makes use of.
- If the rating is -1, we ask Gemma to offer a response. This response, mixed with the chat info, is then despatched to an occasion messaging system that acts because the glue between the pipeline and different functions. This step permits an individual to evaluation the content material.
The pipeline code
Setup
Entry and obtain Gemma
In our instance, we use Gemma by means of the KerasNLP, and we use Kaggle’s ‘Instruction tuned’ gemma2_keras_gemma2_instruct_2b_en variant. You will need to obtain the mannequin and retailer it in a location that the pipeline can entry.
Use the Dataflow service
Though it is attainable to make use of CPUs for testing and improvement, given the inference instances, for a manufacturing system we have to use GPUs on the Dataflow ML service. Using GPUs with Dataflow is facilitated by a customized container. Particulars for this setup can be found at Dataflow GPU support. We advocate that you just comply with the local development information for improvement, which permits for fast testing of the pipeline. You too can reference the guide for using Gemma on Dataflow, which incorporates hyperlinks to an instance Docker file.
Gemma customized mannequin handler
The RunInference rework in Apache Beam is on the coronary heart of this resolution, making use of a mannequin handler for configuration and abstracting the person from the boilerplate code wanted for productionization. Most mannequin sorts may be supported with configuration solely utilizing Beam’s in-built mannequin handlers, however for Gemma, this weblog makes use of a customized mannequin handler, which supplies us full management of our interactions with the mannequin whereas nonetheless utilizing all of the equipment that RunInference supplies for processing. The pipeline custom_model_gemma.py has an instance GemmModelHandler that you need to use. Please be aware the usage of the max_length worth used within the mannequin.generate() name from that GemmModelHandler. This worth controls the utmost size of Gemma’s response to queries and can must be modified to match the wants of the use case, for this weblog we used the worth 512.
Tip: For this weblog, we discovered that utilizing the jax keras backend carried out considerably higher. To allow this, the DockerFile should comprise the instruction ENV KERAS_BACKEND="jax". This have to be set in your container earlier than the employee begins up Beam (which imports Keras)
Construct the pipeline
Step one within the pipeline is commonplace for occasion processing programs: we have to learn the JSON messages that our upstream programs have created, which bundle chat messages right into a easy construction that features the chat ID.
chats = ( pipeline | "Learn Subject" >>
beam.io.ReadFromPubSub(subscription=args.messages_subscription)
| "Decode" >> beam.Map(lambda x: x.decode("utf-8")
)
The next instance reveals one among these JSON messages, in addition to a vital dialogue about pineapple and pizza, with ID 221 being our buyer.
{
"id": 1,
"user_id": 221,
"chat_message": "nid 221: Hay I'm actually aggravated that your menu features a pizza with pineapple on it! nid 331: Sorry to listen to that , however pineapple is sweet on pizzanid 221: What a horrible factor to say! Its by no means okay, so sad proper now! n"
}
We now have a PCollection of python chat objects. Within the subsequent step, we extract the wanted values from these chat messages and incorporate them right into a immediate to go to our instruction tuned LLM. To do that step, we create a immediate template that gives directions for the mannequin.
prompt_template = """
<immediate>
Present the outcomes of doing these two duties on the chat historical past supplied under for the person {}
activity 1 : assess if the tone is blissful = 1 , impartial = 0 or indignant = -1
activity 2 : summarize the textual content with a most of 512 characters
Output the outcomes as a json with fields [sentiment, summary]
@@@{}@@@
<reply>
"""
The next is a instance of a immediate being despatched to the mannequin:
<immediate>
Present the outcomes of doing these two duties on the chat historical past supplied under for the person 221
activity 1 : assess if the tone is blissful = 1 , impartial = 0 or indignant = -1
activity 2 : summarize the textual content with a most of 512 characters
Output the outcomes as a json with fields [sentiment, summary]
@@@"nid 221: Hay I'm actually aggravated that your menu features a pizza with pineapple on it! nid 331: Sorry to listen to that , however pineapple is sweet on pizzanid 221: What a horrible factor to say! Its by no means okay, so sad proper now! n"@@@
<reply>
Some notes in regards to the immediate:
- This immediate is meant as an illustrative instance. To your personal prompts, run full evaluation with indicative knowledge in your utility.
- For prototyping you need to use aistudio.google.com to check Gemma and Gemini conduct shortly. There is also a one click on API key in the event you’d like to check programmatically.
2. With smaller, much less highly effective fashions, you may get higher responses by simplifying the directions to a single activity and making a number of calls in opposition to the mannequin.
3. We restricted chat message summaries to a most of 512 characters. Match this worth with the worth that’s supplied within the max_length config to the Gemma generate name.
4. The three ampersands, ‘@@@’ are used as a trick to permit us to extract the unique chats from the message after processing. Different methods we are able to do that activity embrace:
- Use the entire chat message as a key within the key-value pair.
- Be part of the outcomes again to the unique knowledge. This method requires a shuffle.
5. As we have to course of the response in code, we ask the LLM to create a JSON illustration of its reply with two fields: sentiment and abstract.
To create the immediate, we have to parse the data from our supply JSON message after which insert it into the template. We encapsulate this course of in a Beam DoFN and use it in our pipeline. In our yield assertion, we assemble a key-value construction, with the chat ID being the important thing. This construction permits us to match the chat to the inference after we name the mannequin.
# Create the immediate utilizing the data from the chat
class CreatePrompt(beam.DoFn):
def course of(self, ingredient, *args, **kwargs):
user_chat = json.hundreds(ingredient)
chat_id = user_chat['id']
user_id = user_chat['user_id']
messages = user_chat['chat_message']
yield (chat_id, prompt_template.format(user_id, messages))
prompts = chats | "Create Immediate" >> beam.ParDo(CreatePrompt())
We are actually able to name our mannequin. Because of the RunInference equipment, this step is easy. We wrap the GemmaModelHandler inside a KeyedModelhandler, which tells RunInference to simply accept the incoming knowledge as a key-value pair tuple. Throughout improvement and testing, the mannequin is saved within the gemma2 listing. When operating the mannequin on the Dataflow ML service, the mannequin is saved in Google Cloud Storage, with the URI format gs://<your_bucket>/gemma-directory.
keyed_model_handler = KeyedModelHandler(GemmaModelHandler('gemma2'))
outcomes = prompts | "RunInference-Gemma" >> RunInference(keyed_model_handler)
The outcomes assortment now incorporates outcomes from the LLM name. Right here issues get somewhat attention-grabbing: though the LLM name is code, in contrast to calling simply one other operate, the outcomes should not deterministic! This contains that ultimate little bit of our immediate request “Output the outcomes as a JSON with fields [sentiment, summary]“. Usually, the response matches that form, however it’s not assured. We must be somewhat defensive right here and validate our enter. If it fails the validation, we output the outcomes to an error assortment. On this pattern, we go away these values there. For a manufacturing pipeline, you may need to let the LLM strive a second time and run the error assortment ends in RunInference once more after which flatten the response with the outcomes assortment. As a result of Beam pipelines are Directed Acyclic Graphs, we are able to’t create a loop right here.
We now take the outcomes assortment and course of the LLM output. To course of the outcomes of RunInference, we create a brand new DoFn SentimentAnalysis and performance extract_model_reply This step returns an object of kind PredictionResult:
def extract_model_reply(model_inference):
match = re.search(r"({[sS]*?})", model_inference)
json_str = match.group(1)
consequence = json.hundreds(json_str)
if all(key in consequence for key in ['sentiment', 'summary']):
return consequence
elevate Exception('Malformed mannequin reply')
class SentimentAnalysis(beam.DoFn):
def course of(self, ingredient):
key = ingredient[0]
match = re.search(r"@@@([sS]*?)@@@", ingredient[1].instance)
chats = match.group(1)
strive:
# The consequence will comprise the immediate, exchange the immediate with ""
consequence = extract_model_reply(ingredient[1].inference.exchange(ingredient[1].instance, ""))
processed_result = (key, chats, consequence['sentiment'], consequence['summary'])
if (consequence['sentiment'] <0):
output = beam.TaggedOutput('damaging', processed_result)
else:
output = beam.TaggedOutput('foremost', processed_result)
besides Exception as err:
print("ERROR!" + str(err))
output = beam.TaggedOutput('error', ingredient)
yield output
It is value spending a couple of minutes on the necessity for extract_model_reply(). As a result of the mannequin is self-hosted, we can’t assure that the textual content will likely be a JSON output. To make sure that we get a JSON output, we have to run a few checks. One advantage of utilizing the Gemini API is that it features a characteristic that ensures the output is at all times JSON, often called constrained decoding.
Let’s now use these features in our pipeline:
filtered_results = (outcomes | "Course of Outcomes" >> beam.ParDo(SentimentAnalysis()).with_outputs('foremost','damaging','error'))
Utilizing with_outputs creates a number of accessible collections in filtered_results. The primary assortment has sentiments and summaries for constructive and impartial opinions, whereas error incorporates any unparsable responses from the LLM. You may ship these collections to different sources, similar to BigQuery, with a write rework. This instance doesn’t display this step, nonetheless, the damaging assortment is one thing that we need to do extra inside this pipeline.
Adverse sentiment processing
Ensuring prospects are blissful is important for retention. Whereas we have now used a light-hearted instance with our pineapple on pizza debate, the direct interactions with a buyer ought to at all times attempt for empathy and constructive responses from all components of a corporation. At this stage, we go on this chat to one of many educated help representatives, however we are able to nonetheless see if the LLM is ready to help that help individual in decreasing the time to decision.
For this step, we make a name to the mannequin and ask it to formulate a response. We once more use the Gemma 2B mannequin for this name within the code.
generated_responses = (outcomes.damaging
| "Generate Response" >> beam.Map(lambda x: ((x[0], x[3]), "<immediate>Generate an apology response for the person on this chat textual content: " + x[1] + "<reply>"))
| "Gemma-Response" >> RunInference(keyed_model_handler)
Usually, you wrap the immediate creation code in a DoFn, however it is usually attainable to make use of a easy lambda within the pipeline code itself. Right here we generate a immediate that incorporates the unique chat message, which was extracted within the SentimentAnalysis operate.
For native operating and testing we are able to make use of some easy print statements to see the outputs on the varied PCollections:
generated_responses | "Print Response" >> beam.Map(print)
filtered_results.foremost | "Print Important" >> beam.Map(print)
filtered_results.error | "Print Errors" >> beam.Map(print)
In fact for the actual utilization, these outputs will likely be despatched to varied sinks similar to Pub/Sub and BigQuery.
Run the pipeline
Lets see how the mannequin does with the earlier JSON message:
Step 1: Sentiment evaluation and summarization
“sentiment”: -1,
“abstract”: “Consumer 221 may be very sad in regards to the presence of pineapple on pizza.”
The responses that the 2B mannequin generated aren’t unhealthy. The sentiment is appropriate, and since the outcomes of the abstract are extra subjective, the correctness of the response is determined by the downstream makes use of of this info.
Step 2: Generated response
“I perceive that you just’re upset in regards to the pineapple pizza. It is a very private desire, and I apologize that it may need precipitated you some frustration. We try to supply a various menu to cater to a variety of tastes, and we’re at all times open to suggestions. Would you wish to share your ideas on the pizza with pineapple?“
Are these responses acceptable? At this stage, we intend to ship the entire knowledge bundle to a help consultant for evaluation and if they’re proud of it they’ll ship it as is, or they’ll make some edits and changes.
Subsequent Steps
Perhaps at this stage we need to make use of a mannequin with extra parameters, similar to Gemma2 9B or 27B. We may additionally use a mannequin that’s giant sufficient that it requires an API name to an exterior service name, similar to Gemini, as an alternative of being loaded onto a employee. In spite of everything, we decreased the work wanted to ship to those bigger fashions by utilizing the smaller mannequin as a filter. Making these decisions is not only a technical resolution, but in addition a enterprise resolution. The prices and advantages must be measured. We are able to once more make use of Dataflow to extra simply arrange A/B testing.
You additionally might select to finetune a mannequin customized to your use case. That is a method of fixing the “voice” of the mannequin to fit your wants.
A/B Testing
In our generate step, we handed all incoming damaging chats to our 2B mannequin. If we needed to ship a portion of the gathering to a different mannequin, we are able to use the Partition operate in Beam with the filtered_responses.damaging assortment. By directing some buyer messages to completely different fashions and having help employees price the generated responses earlier than sending them, we are able to accumulate precious suggestions on response high quality and enchancment margins.
Abstract
With these few strains of code, we constructed a system able to processing buyer sentiment knowledge at excessive velocity and variability. By utilizing the Gemma 2 open mannequin, with its ‘unmatched efficiency for its dimension’, we have been capable of incorporate this highly effective LLM inside a stream processing use case that helps create a greater expertise for patrons.











{kind=link}