
The newest 27B parameters Keras mannequin: Gemma 2
Following within the footsteps of Gemma 1.1 (Kaggle, Hugging Face), CodeGemma (Kaggle, Hugging Face) and the PaliGemma multimodal mannequin (Kaggle, Hugging Face), we’re glad to announce the discharge of the Gemma 2 mannequin in Keras.
Gemma 2 is offered in two sizes – 9B and 27B parameters – with commonplace and instruction-tuned variants. You could find them right here:
Gemma 2’s top-notch outcomes on LLM benchmarks are coated elsewhere (see goo.gle/gemma2report). On this put up we want to showcase how the mix of Keras and JAX may help you’re employed with these massive fashions.
JAX is a numerical framework constructed for scale. It leverages the XLA machine studying compiler and trains the biggest fashions at Google.
Keras is the modeling framework for ML engineers, now operating on JAX, TensorFlow or PyTorch. Keras now brings the ability mannequin parallel scaling via a pleasant Keras API. You’ll be able to attempt the brand new Gemma 2 fashions in Keras right here:
Distributed fine-tuning on TPUs/GPUs with ModelParallelism
Due to their measurement, these fashions can solely be loaded and fine-tuned at full precision by splitting their weights throughout a number of accelerators. JAX and XLA have in depth help for weights partitioning (SPMD model parallelism) and Keras provides the keras.distribution.ModelParallel API that will help you specify shardings layer by layer in a easy method:
# Checklist accelerators
gadgets = keras.distribution.list_devices()
# Prepare accelerators in a logical grid with named axes
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], gadgets)
# Inform XLA partition weights (defaults for Gemma)
layout_map = gemma2_lm.spine.get_layout_map()
# Outline a ModelParallel distribution
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# Set is because the default and cargo the mannequin
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.fashions.GemmaCausalLM.from_preset(...)
The gemma2_lm.spine.get_layout_map()perform is a helper returning a layer by layer sharding configuration for all of the weights of the mannequin. It follows the Gemma paper (goo.gle/gemma2report) suggestions. Right here is an excerpt:
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("mannequin", "knowledge")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("mannequin", "knowledge", None)
layout_map["decoder_block.*attention_output.kernel"] = ("mannequin", None, "knowledge")
...
In a nutshell, for every layer, this config specifies alongside which axis or axes to separate every block of weights, and on which accelerators to position the items. It’s simpler to grasp with an image. Let’s take for instance the “question” weights within the Transformer consideration structure, that are of form (nb heads, embed measurement, head dim):
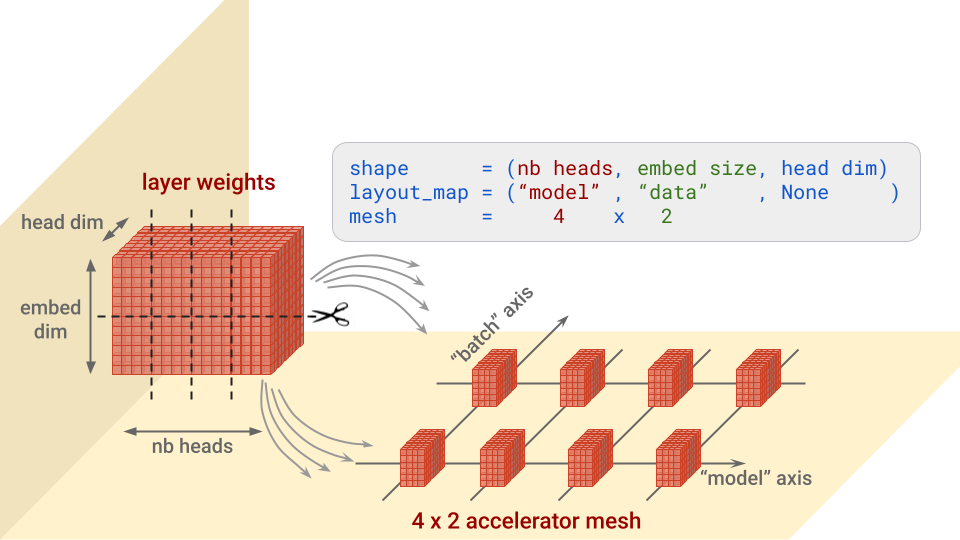
Weight partitioning instance for the question (or key or worth) weights within the Transformer consideration structure.
Be aware: mesh dimensions for which there are not any splits will obtain copies. This is able to be the case for instance if the structure map above was (“mannequin”, None, None).
Discover additionally the batch_dim_name="batch" parameter in ModelParallel. If the “batch” axis has a number of rows of accelerators on it, which is the case right here, knowledge parallelism can even be used. Every row of accelerators will load and prepare on solely part of every knowledge batch, after which the rows will mix their gradients.
As soon as the mannequin is loaded, listed below are two helpful code snippets to show the load shardings that had been really utilized:
for variable in gemma2_lm.spine.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.form):<16}
{str(variable.worth.sharding.spec)}')
#... set an optimizer via gemma2_lm.compile() after which:
gemma2_lm.optimizer.construct(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.form):<16}
{str(variable.worth.sharding.spec)}')
And if we have a look at the output (beneath), we discover one thing essential: the regexes within the structure spec matched not solely the layer weights, but in addition their corresponding momentum and velocity variables within the optimizer and sharded them appropriately. This is a vital level to examine when partitioning a mannequin.
# for layers:
# weight identify . . . . . . . . . . form . . . . . . structure spec
decoder_block_1/consideration/question/kernel (16, 3072, 256)
PartitionSpec('mannequin', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'mannequin')
...
# for optimizer vars:
# var identify . . . . . . . . . . . .form . . . . . . structure spec
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('mannequin', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('mannequin', None, None)
...
Coaching on restricted HW with LoRA
LoRA is a method that freezes mannequin weights and replaces them with low-rank, i.e. small, adapters.
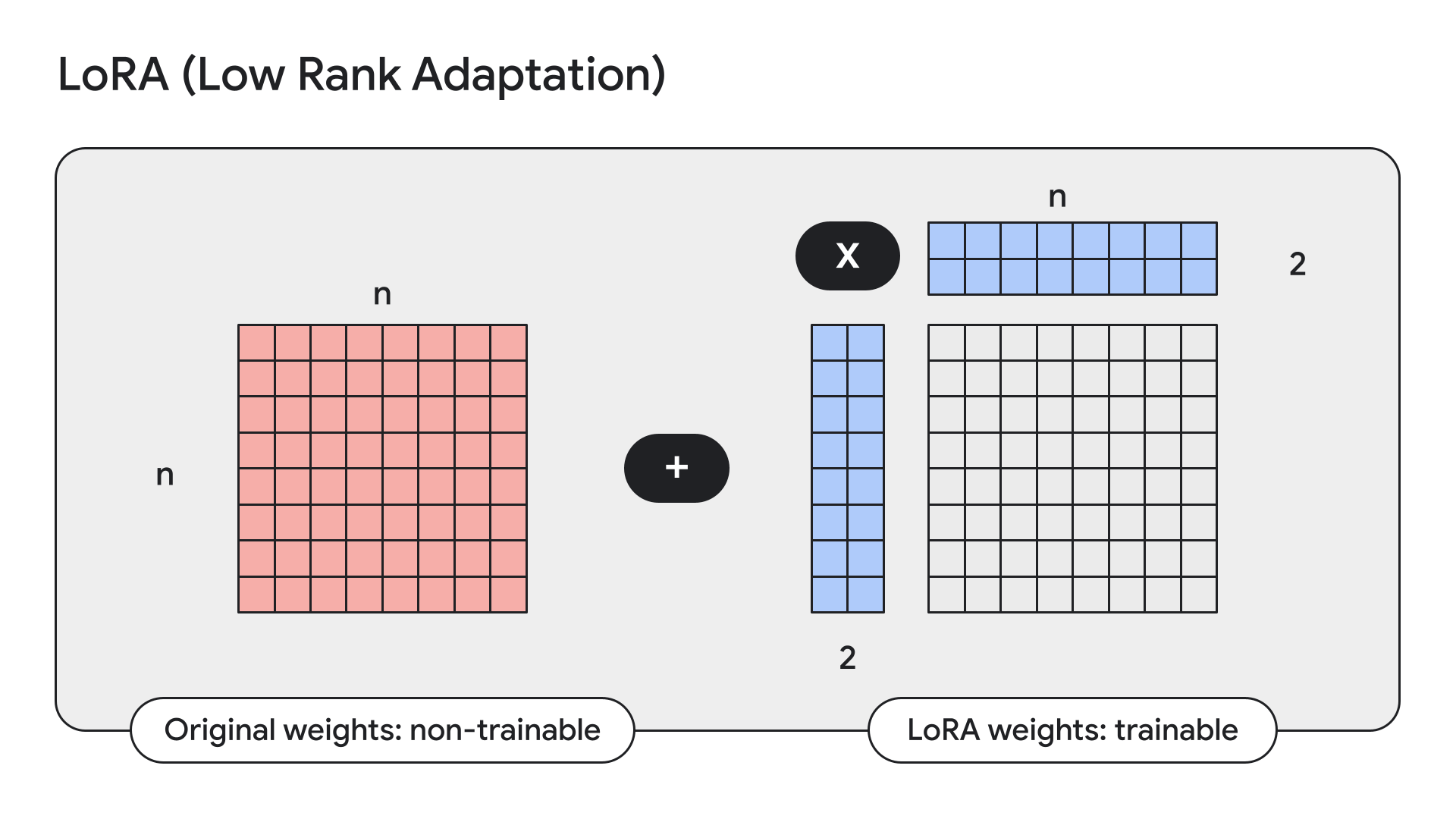
Keras additionally has easy APIs for this:
gemma2_lm.spine.enable_lora(rank=4) # Rank picked from empirical testing
Displaying mannequin particulars with mannequin.abstract() after enabling LoRA, we will see that LoRA reduces the variety of trainable parameters in Gemma 9B from 9 billion to 14.5 million.
An replace from Hugging Face
Final month, we announced that Keras fashions can be out there, for obtain and consumer uploads, on each Kaggle and Hugging Face. At present, we’re pushing the Hugging Face integration even additional: now you can load any fine-tuned weights for supported fashions, whether or not they have been skilled utilizing a Keras model of the mannequin or not. Weights might be transformed on the fly to make this work. Which means that you now have entry to the handfuls of Gemma fine-tunes uploaded by Hugging Face customers, instantly from KerasNLP. And never simply Gemma. This can finally work for any Hugging Face Transformers mannequin that has a corresponding KerasNLP implementation. For now Gemma and Llama3 work. You’ll be able to attempt it out on the Hermes-2-Pro-Llama-3-8B fine-tune for instance utilizing this Colab:
causal_lm = keras_nlp.fashions.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Professional-Llama-3-8B"
)
Discover PaliGemma with Keras 3
PaliGemma is a robust open VLM impressed by PaLI-3. Constructed on open parts together with the SigLIP imaginative and prescient mannequin and the Gemma language mannequin, PaliGemma is designed for class-leading fine-tune efficiency on a variety of vision-language duties. This contains picture captioning, visible query answering, understanding textual content in photographs, object detection, and object segmentation.
You could find the Keras implementation of PaliGemma on GitHub, Hugging Face models and Kaggle.
We hope you’ll take pleasure in experimenting or constructing with the brand new Gemma 2 fashions in Keras!











{kind=link}