- We’re sharing how Meta constructed assist for knowledge logs, which offer folks with extra knowledge about how they use our merchandise.
- Right here we discover preliminary system designs we thought-about, an outline of the present structure, and a few essential ideas Meta takes under consideration in making knowledge accessible and simple to grasp.
Customers have quite a lot of instruments they will use to handle and entry their data on Meta platforms. Meta is all the time on the lookout for methods to reinforce its entry instruments according to technological advances, and in February 2024 we started together with data logs within the Download Your Information (DYI) device. Information logs embody issues resembling details about content material you’ve seen on Fb. A few of this knowledge may be distinctive, however it could actually additionally embody extra particulars about data that we already make obtainable elsewhere, resembling via a person’s profile, merchandise like Access Your Information or Activity Log, or account downloads. This replace is the results of important investments over quite a few years by a big cross-functional crew at Meta, and consultations with specialists on the way to proceed enhancing our entry instruments.
Information logs are simply the latest instance of how Meta offers customers the ability to entry their knowledge on our platforms. We’ve got an extended historical past of giving customers transparency and management over their knowledge:
- 2010: Customers can retrieve a replica of their data via DYI.
- 2011: Customers can simply overview actions taken on Fb via Activity Log.
- 2014: Customers have extra transparency and management over adverts they see with the “Why Am I Seeing This Ad?” characteristic on Fb.
- 2018: Customers have a curated expertise to seek out details about them via Access Your Information. Customers can retrieve a replica of their data on Instagram via Download Your Data and on WhatsApp via Request Account Information.
- 2019: Customers can view their exercise off Meta-technologies and clear their historical past. Meta joins the Data Transfer Project and has constantly led the event of shared applied sciences that allow customers to port their knowledge from one platform to a different.
- 2020: Customers proceed to receive more information in DYI resembling extra details about their interactions on Fb and Instagram.
- 2021: Customers can extra simply navigate classes of knowledge in Access Your Information
- 2023: Customers can extra simply use our instruments as entry options are consolidated inside Accounts Center.
- 2024: Customers can entry knowledge logs in Obtain Your Info.
What are knowledge logs?
In distinction to our manufacturing techniques, which may be queried billions of instances per second due to strategies like caching, Meta’s knowledge warehouse, powered by Hive, is designed to assist low volumes of huge queries for issues like analytics and can’t scale to the question charges wanted to energy real-time knowledge entry.
We created knowledge logs as an answer to offer customers who need extra granular data with entry to knowledge saved in Hive. On this context, a person knowledge log entry is a formatted model of a single row of information from Hive that has been processed to make the underlying knowledge clear and simple to grasp.
Acquiring this knowledge from Hive in a format that may be introduced to customers isn’t simple. Hive tables are partitioned, sometimes by date and time, so retrieving all the info for a particular person requires scanning via each row of each partition to examine whether or not it corresponds to that person. Fb has over 3 billion month-to-month lively customers, which means that, assuming a good distribution of information, ~99.999999967% of the rows in a given Hive desk is likely to be processed for such a question despite the fact that they gained’t be related.
Overcoming this elementary limitation was difficult, and adapting our infrastructure to allow it has taken a number of years of concerted effort. Information warehouses are generally utilized in a spread of trade sectors, so we hope that this answer ought to be of curiosity to different corporations searching for to offer entry to the info of their knowledge warehouses.
Preliminary designs
Once we began designing an answer to make knowledge logs obtainable, we first thought-about whether or not it might be possible to easily run queries for every particular person as they requested their knowledge, even though these queries would spend nearly all of their time processing irrelevant knowledge. Sadly, as we highlighted above, the distribution of information at Meta’s scale makes this strategy infeasible and extremely wasteful: It could require scanning total tables as soon as per DYI request, scaling linearly with the variety of particular person customers that provoke DYI requests. These efficiency traits have been infeasible to work round.
We additionally thought-about caching knowledge logs in a web-based system able to supporting a spread of listed per-user queries. This might make the per-user queries comparatively environment friendly. Nevertheless, copying and storing knowledge from the warehouse in these different techniques introduced materials computational and storage prices that weren’t offset by the general effectiveness of the cache, making this infeasible as effectively.
Present design
Lastly, we thought-about whether or not it might be attainable to construct a system that depends on amortizing the price of costly full desk scans by batching particular person customers’ requests right into a single scan. After important engineering investigation and prototyping, we decided that this method gives sufficiently predictable efficiency traits to infrastructure groups to make this attainable. Even with this batching over brief durations of time, given the comparatively small dimension of the batches of requests for this data in comparison with the general person base, many of the rows thought-about in a given desk are filtered and scoped out as they aren’t related to the customers whose knowledge has been requested. It is a vital commerce off to allow this data to be made accessible to our customers.
In additional element, following a pre-defined schedule, a job is triggered utilizing Meta’s inner task-scheduling service to arrange the latest requests, over a short while interval, for customers’ knowledge logs right into a single batch. This batch is submitted to a system constructed on high of Meta’s Core Workflow Service (CWS). CWS gives a helpful set of ensures that allow long-running duties to be executed with predictable efficiency traits and reliability ensures which might be vital for complicated multi-step workflows.
As soon as the batch has been queued for processing, we copy the listing of person IDs who’ve made requests in that batch into a brand new Hive desk. For every knowledge logs desk, we provoke a brand new employee activity that fetches the related metadata describing the way to appropriately question the info. As soon as we all know what to question for a particular desk, we create a activity for every partition that executes a job in Dataswarm (our knowledge pipeline system). This job performs an INNER JOIN between the desk containing requesters’ IDs and the column in every desk that identifies the proprietor of the info in that row. As tables in Hive might leverage safety mechanisms like entry management lists (ACLs) and privateness protections constructed on high of Meta’s Privacy Aware Infrastructure, the roles are configured with acceptable safety and privateness insurance policies that govern entry to the info.
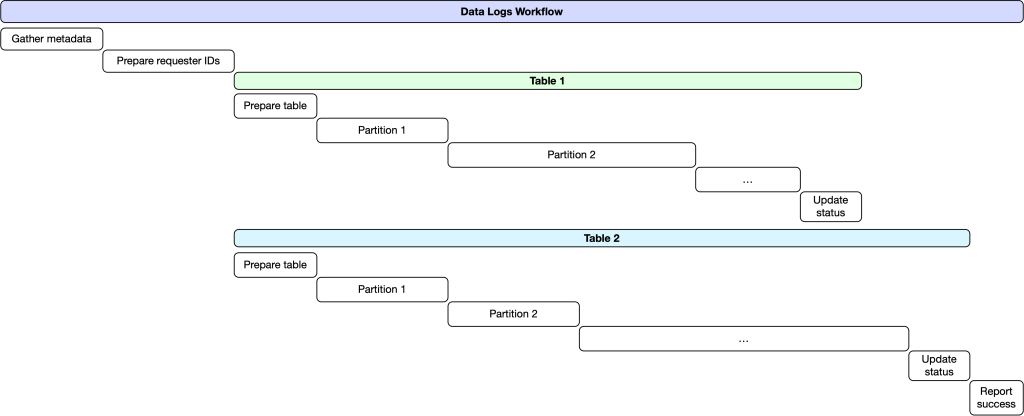
As soon as this job is accomplished, it outputs its outcomes to an intermediate Hive desk containing a mix of the info logs for all customers within the present batch. This processing is dear, because the INNER JOIN requires a full desk scan throughout all related partitions of the Hive desk, an operation which can devour important computational sources. The output desk is then processed utilizing PySpark to determine the related knowledge and cut up it into particular person information for every person’s knowledge in a given partition.
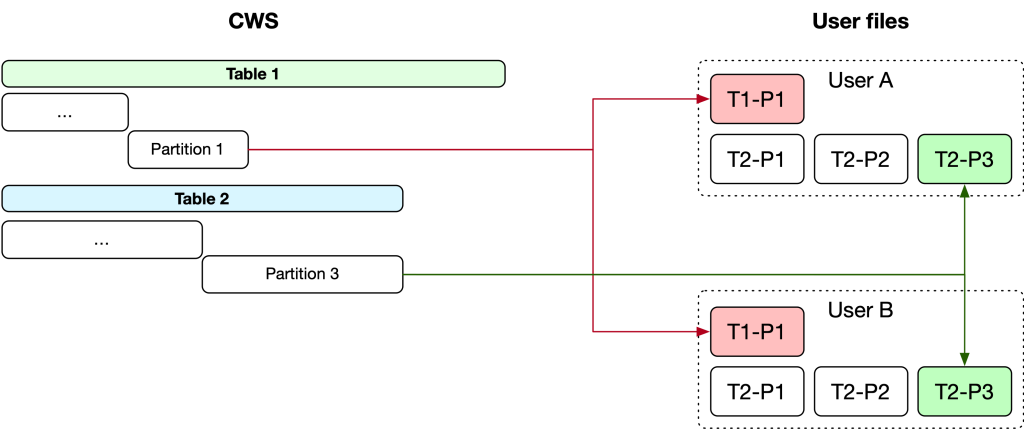
The results of these batch operations within the knowledge warehouse is a set of comma delimited textual content information containing the unfiltered uncooked knowledge logs for every person. This uncooked knowledge isn’t but defined or made intelligible to customers, so we run a post-processing step in Meta’s Hack language to use privateness guidelines and filters and render the uncooked knowledge into significant, well-explained HTML information. We do that by passing the uncooked knowledge via numerous renderers, mentioned in additional element within the subsequent part. Lastly, as soon as all the processing is accomplished, the outcomes are aggregated right into a ZIP file and made obtainable to the requestor via the DYI device.
Classes discovered from constructing knowledge logs
All through the event of this method we discovered it vital to develop strong checkpointing mechanisms that allow incremental progress and resilience within the face of errors and non permanent failures. Whereas processing every part in a single move might scale back latency, the danger is {that a} single challenge will trigger all the earlier work to be wasted. For instance, along with jobs timing out and failing to finish, we additionally skilled errors the place full-table-scan queries would run out of reminiscence and fail partway via processing. The potential to renew work piecemeal will increase resiliency and optimizes the general throughput of the system.
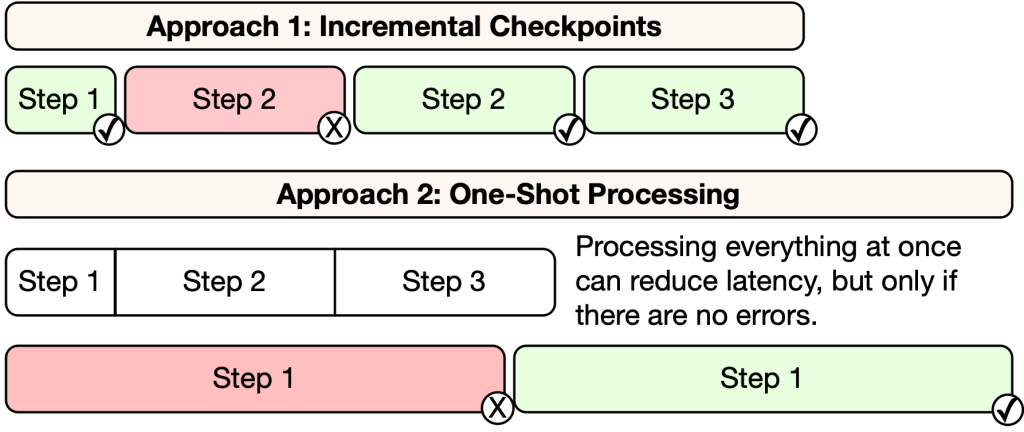
Making certain knowledge correctness can be crucial. As we constructed the element that splits mixed outcomes into particular person information for every person, we encountered a difficulty that affected this correctness assure and will have led to knowledge being returned to the mistaken person. The basis reason behind the problem was a Spark concurrency bug that partitioned knowledge incorrectly throughout the parallel Spark staff. To forestall this challenge, we constructed verification within the post-processing stage to make sure that the person ID column within the knowledge matches the identifier for the person whose logs we’re producing. Which means even when related bugs have been to happen within the core knowledge processing infrastructure we’d forestall any incorrect knowledge from being proven to customers.
Lastly, we discovered that complicated knowledge workflows require superior instruments and the aptitude to iterate on code modifications rapidly with out re-processing every part. To this finish, we constructed an experimentation platform that allows operating modified variations of the workflows to rapidly take a look at modifications, with the power to independently execute phases of the method to expedite our work. For instance, we discovered that innocent-looking modifications resembling altering which column is being fetched can result in complicated failures within the knowledge fetching jobs. We now have the power to run a take a look at job beneath the brand new configuration when making a change to a desk fetcher.
Making knowledge constantly comprehensible and explainable
Meta cares about making certain that the data we offer is significant to end-users. A key problem in offering clear entry is presenting usually extremely technical data in a method that’s approachable and simple to grasp, even for these with little experience in expertise.
Offering folks entry to their knowledge includes working throughout quite a few merchandise and surfaces that our customers work together with day by day. The best way that data is saved on our back-end techniques isn’t all the time instantly intelligible to end-users, and it takes each understanding of the person merchandise and options in addition to the wants of customers to make it user-friendly. It is a giant, collaborative enterprise, leveraging many types of experience. Our course of entails working with product groups acquainted with the info from their respective merchandise, making use of our historic experience in entry surfaces, utilizing progressive instruments we’ve got developed, and consulting with specialists.
In additional element, a cross-functional crew of entry specialists works with specialist groups to overview these tables, taking care to keep away from exposing data that would adversely have an effect on the rights and freedoms of different customers. For instance, for those who block one other person Fb, this data wouldn’t be supplied to the person who you could have blocked. Equally, if you view one other person’s profile, this data will probably be obtainable to you, however not the individual whose profile you seen. It is a key precept Meta upholds to respect the rights of everybody who engages with our platforms. It additionally signifies that we want a rigorous course of to make sure that the info made obtainable is rarely shared incorrectly. Most of the datasets that energy a social community will reference multiple individual, however that doesn’t indicate everybody referenced ought to all the time have equal entry to that data.
Moreover, Meta should take care to not disclose data that will compromise our integrity or security techniques, or our mental property rights. For example, Meta sends millions of NCMEC Cybertip reports per year to assist defend kids on our platforms. Disclosing this data, or the info alerts used to detect obvious violations of legal guidelines defending kids, might undermine the delicate strategies we’ve got developed to proactively hunt down and report most of these content material and interactions.
One notably time consuming and difficult activity is making certain that Meta-internal textual content strings that describe our techniques and merchandise are translated into extra simply human readable phrases. For example, a Hack enum may outline a set of person interface component references. Exposing the jargon-heavy inner variations of those enums would undoubtedly not be significant to an end-user — they is probably not significant at first look to different staff with out enough context! On this case, user-friendly labels are created to exchange these internal-facing strings. The ensuing content material is reviewed for explainability, simplicity, and consistency, with product specialists additionally serving to to confirm that the ultimate model is correct.
This course of makes data extra helpful by decreasing duplicative data. When engineers construct and iterate on a product for our platforms, they could log barely totally different variations of the identical data with the aim of higher understanding how folks use the product. For instance, when customers choose an choice from an inventory of actions, every a part of the system might use barely totally different values that signify the identical underlying choice, resembling an choice to maneuver content material to trash as a part of Manage Activity. As a concrete instance, we discovered this motion saved with totally different values: Within the first occasion it was entered as MOVE_TO_TRASH, within the second as StoryTrashPostMenuItem, and within the third FBFeedMoveToTrashOption. These variations stemmed from the truth that the logging in query was coming from totally different components of the system with totally different conventions. Via a sequence of cross-functional opinions with assist from product specialists, Meta determines an acceptable column header (e.g., “Which choice you interacted with”), and one of the best label for the choice (e.g., “Transfer to trash”).
Lastly, as soon as content material has been reviewed, it may be applied in code utilizing the renderers we described above. These are liable for studying the uncooked values and remodeling them into user-friendly representations. This contains reworking uncooked integer values into significant references to entities and changing uncooked enum values into user-friendly representations. An ID like 1786022095521328 may turn into “John Doe”; enums with integer values 0, 1, 2, transformed into textual content like “Disabled,” “Lively,” or “Hidden;”and columns with string enums can take away jargon that’s not comprehensible to end-users and de-duplicate (as in our “Transfer to trash” instance above).
Collectively, these culminate in a a lot friendlier illustration of the info that may seem like this:












{kind=link}