On this planet of frontend improvement, one factor stays sure: change is the one fixed. New frameworks emerge, and libraries can turn out to be out of date with out warning. Maintaining with the ever-changing ecosystem includes dealing with code conversions, each large and small. One vital shift for us was the transition from Enzyme to React Testing Library (RTL), prompting many engineers to transform their check code to a extra user-focused RTL method. Whereas each Enzyme and RTL have their very own strengths and weaknesses, the absence of native help for React 18 by Enzyme offered a compelling rationale for transitioning to RTL. It’s so compelling that we at Slack determined to transform greater than 15,000 of our frontend unit and integration Enzyme exams to RTL, as a part of the replace to React 18.
We began by exploring probably the most easy avenue of looking for out potential Enzyme adapters for React 18. Sadly, our search yielded no viable choices. In his article titled “Enzyme is dead. Now what?“, Wojciech Maj, the writer of the React 17 adapter, unequivocally recommended, “you must contemplate in search of Enzyme different proper now.”

Contemplating our final purpose of updating to React 18, which Enzyme doesn’t help, we began with a radical evaluation of the issue’s scope and methods to automate this course of. Our initiative started with a monumental activity of changing greater than 15,000 Enzyme check instances, which translated to greater than 10,000 potential engineering hours. At that scale with that many engineering hours required, it was virtually compulsory to optimize and automate that course of. Regardless of thorough opinions of present instruments and in depth Google searches, we discovered no appropriate options for this quite common downside. On this weblog, I’ll stroll you thru our method to automating the Enzyme-to-RTL conversion course of. It contains analyzing and scoping the problem, using conventional Summary Syntax Tree (AST) transformations and an AI Giant Language Mannequin (LLM) independently, adopted by our customized hybrid method of mixing AST and LLM methodologies.
Summary Syntax Tree (AST) transformations
Our preliminary method centered round a extra standard approach of performing automated code conversions — Summary Syntax Tree (AST) transformations. These transformations allow us to symbolize code as a tree construction with nodes and create focused queries with conversions from one code node to a different. For instance, wrapper.discover('selector'); can will be represented as:

Naturally, we aimed to create guidelines to handle the most typical conversion patterns. Apart from specializing in the rendering strategies, similar to mount and shallow, and varied helpers using them, we recognized probably the most often used Enzyme strategies to prioritize the conversion efforts. These are the highest 10 strategies in our codebase:
[
{ method: 'find', count: 13244 },
{ method: 'prop', count: 3050 },
{ method: 'simulate', count: 2755 },
{ method: 'text', count: 2181 },
{ method: 'update', count: 2147 },
{ method: 'instance', count: 1549 },
{ method: 'props', count: 1522 },
{ method: 'hostNodes', count: 1477 },
{ method: 'exists', count: 1174 },
{ method: 'first', count: 684 },
... and 55 more methods
]One essential requirement for our conversion was reaching 100%-correct transformations, as a result of any deviation would end in incorrect code era. This problem was significantly pronounced with AST conversions, the place as a way to create transformations with 100% accuracy we wanted to painstakingly create extremely particular guidelines for every state of affairs manually. Inside our codebase, we discovered 65 Enzyme strategies, every with its personal quirks, resulting in a quickly increasing rule set and rising considerations about the feasibility of our efforts.
Take, for instance, the Enzyme technique discover, which accepts quite a lot of arguments like selector strings, element varieties, constructors, and object properties. It additionally helps nested filtering strategies like first or filter, providing highly effective factor concentrating on capabilities however including complexity to AST manipulation.
Along with the massive variety of handbook guidelines wanted for technique conversions, sure logic was depending on the rendered element Doc Object Mannequin (DOM) quite than the mere presence or absence of comparable strategies in RTL. As an illustration, the selection between getByRole and getByTestId trusted the accessibility roles or check IDs current within the rendered element. Nonetheless, AST lacks the potential to include such contextual data. Its performance is confined to processing the conversion logic primarily based solely on the contents of the file being remodeled, with out consideration for exterior sources such because the precise DOM or React element code.
With every new transformation rule we tackled, the problem appeared to escalate. After establishing patterns for 10 Enzyme strategies and addressing different apparent patterns associated to our customized Jest matchers and question selectors, it grew to become obvious that AST alone couldn’t deal with the complexity of this conversion activity. Consequently, we opted for a realistic method: we achieved comparatively passable conversions for the most typical instances whereas resorting to handbook intervention for the extra complicated eventualities. For each line of code requiring handbook changes, we added feedback with options and hyperlinks to related documentation. This hybrid technique yielded a modest success charge of 45% robotically transformed code throughout the chosen recordsdata used for analysis. Ultimately, we determined to supply this device to our frontend developer groups, advising them to run our AST-based codemod first after which deal with the remaining conversions manually.
Exploring the AST offered helpful insights into the complexity of the issue. We confronted the problem of various testing methodologies in Enzyme and RTL with no easy mapping between them. Moreover, there have been no appropriate instruments accessible to automate this course of successfully. In consequence, we needed to hunt down different approaches to handle this problem.
Giant Language Fashions (LLMs) transformations

Amidst the widespread conversations on AI options and their potential purposes throughout the business, our workforce felt compelled to discover their applicability to our personal challenges. Collaborating with the DevXP AI workforce at Slack, who concentrate on integrating AI into the developer expertise, we built-in the capabilities of Anthropic’s AI mannequin, Claude 2.1, into our workflows. We created the prompts and despatched the check code together with them to our recently-implemented API endpoint.
Regardless of our greatest efforts, we encountered vital variation and inconsistency. Conversion success charges fluctuated between 40-60%. The outcomes ranged from remarkably efficient conversions to disappointingly insufficient ones, relying largely on the complexity of the duty. Whereas some conversions proved spectacular, significantly in remodeling extremely Enzyme-specific strategies into practical RTL equivalents, our makes an attempt to refine prompts had restricted success. Our efforts to fine-tune prompts might have difficult issues, presumably perplexing the AI mannequin quite than aiding it. The scope of the duty was too massive and multifaceted, so the standalone software of AI failed to supply the constant outcomes we sought, highlighting the complexities inherent in our conversion activity.
The conclusion that we needed to resort to handbook conversions with minimal automation was disheartening. It meant dedicating a considerable quantity of our workforce’s and firm’s time to check migration, time that would in any other case be invested in constructing new options for our clients or enhancing developer expertise. Nonetheless, at Slack, we extremely worth creativity and craftsmanship and we didn’t halt our efforts there. As an alternative, we remained decided to discover each doable avenue accessible to us.
AST + LLM transformations
We determined to watch how actual people carry out check conversions and establish any elements we would have ignored. One notable benefit within the comparability between handbook human conversion and automatic processes was the wealth of knowledge accessible to people throughout conversion duties. People profit from helpful insights taken from varied sources, together with the rendered React element DOM, React element code (usually authored by the identical people), AST conversions, and in depth expertise with frontend applied sciences. Recognizing the importance of this, we reviewed our workflows and built-in most of this related data into our conversion pipeline. That is our ultimate pipeline flowchart:
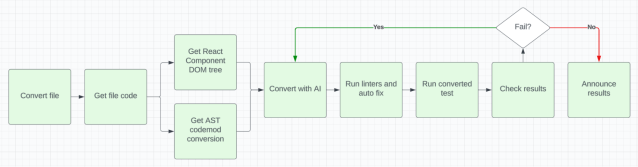
This strategic pivot, and the mixing of each AST and AI applied sciences, helped us obtain the exceptional 80% conversion success charge, primarily based on chosen recordsdata, demonstrating the complementary nature of those approaches and their mixed efficacy in addressing the challenges we confronted.
In our pursuit of optimizing our conversion course of, we carried out a number of strategic selections that led to a notable 20-30% enchancment past the capabilities of our LLM mannequin out-of-the-box. Amongst these, two modern approaches stood out that I’ll write about subsequent:
- DOM tree assortment
- LLM management with prompts and AST
DOM tree assortment
One essential side of our method was the gathering of the DOM tree of React parts. This step proved vital as a result of RTL testing depends closely on the DOM construction of a element quite than its inside construction. By capturing the precise rendered DOM for every check case, we offered our AI mannequin with important contextual data that enabled extra correct and related conversions.
This assortment step was important as a result of every check case might need completely different setups and properties handed to the element, leading to various DOM constructions for every check case. As a part of our pipeline, we ran Enzyme exams and extracted the rendered DOM. To streamline this course of, we developed adaptors for Enzyme rendering strategies and saved the rendered DOM for every check case in a format consumable by the LLM mannequin. As an illustration:
// Import authentic strategies
import enzyme, { mount as originalMount, shallow as originalShallow } from 'enzyme';
import fs from 'fs';
let currentTestCaseName: string | null = null;
beforeEach(() => {
// Set the present check case title earlier than every check
const testName = count on.getState().currentTestName;
currentTestCaseName = testName ? testName.trim() : null;
});
afterEach(() => {
// Reset the present check case title after every check
currentTestCaseName = null;
});
// Override mount technique
enzyme.mount = (node: React.ReactElement, choices?: enzyme.MountRendererProps) => {
const wrapper = originalMount(node, choices);
const htmlContent = wrapper.html();
if (course of.env.DOM_TREE_FILE) {
fs.appendFileSync(
course of.env.DOM_TREE_FILE,
`<test_case_title>${currentTestCaseName}</test_case_title> and <dom_tree>${htmlContent}</dom_tree>;n`,
);
}
return wrapper;
};
...LLM management with prompts and AST
The second inventive change we needed to combine was a extra sturdy and strict controlling mechanism for hallucinations and erratic responses from our LLM. We achieved this by using two key mechanisms: prompts and in-code directions made with the AST codemod. By means of a strategic mixture of those approaches, we created a extra coherent and dependable conversion course of, guaranteeing larger accuracy and consistency in our AI-driven transformations.
We initially experimented with prompts as the first technique of instructing the LLM mannequin. Nonetheless, this proved to be a time-consuming activity. Our makes an attempt to create a common immediate for all requests, together with preliminary and suggestions requests, have been met with challenges. Whereas we might have condensed our code by using a single, complete immediate, we discovered that this method led to a major enhance within the complexity of requests made to the LLM. As an alternative, we opted to streamline the method by formulating a immediate with probably the most vital directions that consisted of three elements: introduction and common context setting, essential request (10 express required duties and 7 elective), adopted by the directions on the right way to consider and current the outcomes:
Context setting:
`I want help changing an Enzyme check case to the React Testing Library framework.
I'll give you the Enzyme check file code inside <code></code> xml tags.
I may also provide the partially transformed check file code inside <codemod></codemod> xml tags.
The rendered element DOM tree for every check case can be offered in <element></element> tags with this construction for a number of check instances "<test_case_title></test_case_title> and <dom_tree></dom_tree>".`Principal request:
`Please carry out the next duties:
1. Full the conversion for the check file inside <codemod></codemod> tags.
2. Convert all check instances and make sure the identical variety of exams within the file. ${numTestCasesString}
3. Exchange Enzyme strategies with the equal React Testing Library strategies.
4. Replace Enzyme imports to React Testing Library imports.
5. Alter Jest matchers for React Testing Library.
6. Return the whole file with all transformed check instances, enclosed in <code></code> tags.
7. Don't modify anything, together with imports for React parts and helpers.
8. Protect all abstracted features as they're and use them within the transformed file.
9. Keep the unique group and naming of describe and it blocks.
10. Wrap element rendering into <Supplier retailer={createTestStore()}><Element></Supplier>. With a view to do this you should do two issues
First, import these:
import { Supplier } from '.../supplier';
import createTestStore from '.../test-store';
Second, wrap element rendering in <Supplier>, if it was not accomplished earlier than.
Instance:
<Supplier retailer={createTestStore()}>
<Element {...props} />
</Supplier>
Make sure that all 10 circumstances are met. The transformed file needs to be runnable by Jest with none handbook adjustments.
Different directions part, use them when relevant:
1. "data-qa" attribute is configured for use with "display.getByTestId" queries.
2. Use these 4 augmented matchers which have "DOM" on the finish to keep away from conflicts with Enzyme
toBeCheckedDOM: toBeChecked,
toBeDisabledDOM: toBeDisabled,
toHaveStyleDOM: toHaveStyle,
toHaveValueDOM: toHaveValue
3. For person simulations use userEvent and import it with "import userEvent from '@testing-library/user-event';"
4. Prioritize queries within the following order getByRole, getByPlaceholderText, getByText, getByDisplayValue, getByAltText, getByTitle, then getByTestId.
5. Use question* variants just for non-existence checks: Instance "count on(display.question*('instance')).not.toBeInTheDocument();"
6. Guarantee all texts/strings are transformed to lowercase regex expression. Instance: display.getByText(/your textual content right here/i), display.getByRole('button', {title: /your textual content right here/i}).
7. When asserting {that a} DOM renders nothing, substitute isEmptyRender()).toBe(true) with toBeEmptyDOMElement() by wrapping the element right into a container. Instance: count on(container).toBeEmptyDOMElement();`Directions to guage and current outcomes:
`Now, please consider your output and ensure your transformed code is between <code></code> tags.
If there are any deviations from the desired circumstances, record them explicitly.
If the output adheres to all circumstances and makes use of directions part, you possibly can merely state "The output meets all specified circumstances."`The second and arguably simpler method we used to regulate the output of the LLM was the utilization of AST transformations. This technique isn’t seen elsewhere within the business. As an alternative of solely counting on immediate engineering, we built-in the partially transformed code and options generated by our preliminary AST-based codemod. The inclusion of AST-converted code in our requests yielded exceptional outcomes. By automating the conversion of easier instances and offering annotations for all different cases via feedback within the transformed file, we efficiently minimized hallucinations and nonsensical conversions from the LLM. This system performed a pivotal position in our conversion course of. Now we have now established a strong framework for managing complicated and dynamic code conversions, leveraging a mess of knowledge sources together with prompts, DOM, check file code, React code, check run logs, linter logs, and AST-converted code. It’s value noting that solely an LLM was able to assimilating such disparate kinds of data; no different device accessible to us possessed this functionality.
Analysis and affect
Analysis and affect assessments have been essential parts of our mission, permitting us to measure the effectiveness of our strategies, quantify the advantages of AI-powered options, and validate the time financial savings achieved via AI integration.
We streamlined the conversion course of with on-demand runs, delivering leads to simply 2-5 minutes, in addition to with CI nightly jobs that dealt with tons of of recordsdata with out overloading our infrastructure. The recordsdata transformed in every nightly run have been categorized primarily based on their conversion standing—absolutely transformed, partially transformed with 50-99% of check instances handed, partially transformed with 20-49% of check instances handed, or partially transformed with lower than 20% of check instances handed—which allowed builders to simply establish and use probably the most successfully transformed recordsdata. This setup not solely saved time by liberating builders from working scripts but additionally enabled them to domestically tweak and refine the unique recordsdata for higher efficiency of the LLM with the native on-demand runs.
Notably, our adoption charge, calculated because the variety of recordsdata that our codemod ran on divided by the overall variety of recordsdata transformed to RTL, reached roughly 64%. This adoption charge highlights the numerous utilization of our codemod device by the frontend builders who have been the first shoppers, leading to substantial time financial savings.
We assessed the effectiveness of our AI-powered codemod alongside two key dimensions: handbook analysis of code high quality on particular check recordsdata and go charge of check instances throughout a bigger check recordsdata set. For the handbook analysis, we analyzed 9 check recordsdata of various complexities (three simple, three medium, and three complicated) which have been transformed by each the LLM and frontend builders. Our benchmark for high quality was set by the requirements achieved by the frontend builders primarily based on our high quality rubric that covers imports, rendering strategies, JavaScript/TypeScript logic, and Jest assertions. We aimed to match their stage of high quality. The analysis revealed that 80% of the content material inside these recordsdata was precisely transformed, whereas the remaining 20% required handbook intervention.
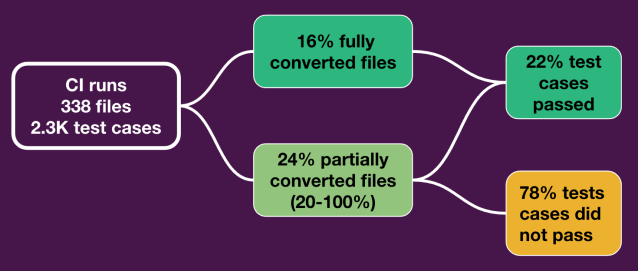
The second dimension of our evaluation delved into the go charge of check instances throughout a complete set of recordsdata. We examined the conversion charges of roughly 2,300 particular person check instances unfold out inside 338 recordsdata. Amongst these, roughly 500 check instances have been efficiently transformed, executed, and handed. This highlights how efficient AI will be, resulting in a major saving of twenty-two% of developer time. It’s essential to notice that this 22% time saving represents solely the documented instances the place the check case handed. Nonetheless, it’s conceivable that some check instances have been transformed correctly, but points similar to setup or importing syntax might have brought about the check file to not run in any respect, and time financial savings weren’t accounted for in these cases. This data-centric method supplies clear proof of tangible time financial savings, finally affirming the highly effective affect of AI-driven options. It’s value noting that the generated code was manually verified by people earlier than merging into our essential repository, guaranteeing the standard and accuracy of the automated conversion course of whereas preserving human experience within the loop.
As our mission nears its conclusion in Could 2024, we’re nonetheless within the strategy of gathering information and evaluating our progress. To this point it’s obvious that LLMs supply helpful help for the builders’ expertise and have a constructive impact on their productiveness, including one other device to our repertoire. Nonetheless, the shortage of knowledge surrounding code era, Enzyme-to-RTL conversion specifically, means that it’s a extremely complicated situation and AI may not be capable of be an final device for this type of conversion. Whereas our expertise has been considerably lucky within the respect that the mannequin we used had out-of-the-box capabilities for JavaScript and TypeScript, and we didn’t must do any additional coaching, it’s clear that customized implementations could also be obligatory to totally make the most of any LLM potential.
Our customized Enzyme-to-RTL conversion device has confirmed efficient to date. It has demonstrated dependable efficiency for large-scale migrations, saved frontend builders noticeable time, and acquired constructive suggestions from our customers. This success confirms the worth of our funding into this automation. Wanting forward, we’re desperate to discover automated frontend unit check era, a subject that has generated pleasure and optimism amongst our builders concerning the potential of AI.
Moreover, as a member of the Frontend Take a look at Frameworks workforce, I’d like to specific my gratitude for the collaboration, help, and dedication of our workforce members. Collectively, we created this conversion pipeline, carried out rigorous testing, made immediate enhancements, and contributed distinctive work on the AST codemod, considerably elevating the standard and effectivity of our AI-powered mission. Moreover, we prolong our due to the Slack DevXP AI workforce for offering an excellent expertise in using our LLM and for patiently addressing all inquiries. Their help has been instrumental in streamlining our workflows and reaching our improvement targets. Collectively, these groups exemplify collaboration and innovation, embodying the spirit of excellence inside our Slack engineering neighborhood.
Involved in constructing modern tasks and making builders’ work lives simpler? We’re hiring 💼











{kind=link}