Introduction
Slack handles a lot of log information. The truth is, we devour over 6 million log messages per second. That equates to over 10 GB of knowledge per second! And it’s all saved utilizing Astra, our in-house, open-source log search engine. To make this information searchable, Astra teams it by time and splits the information into blocks that we confer with as “chunks”.
Initially, we constructed Astra with the idea that every one chunks could be the identical dimension. Nevertheless, that assumption has led to inefficiencies from unused disk area and resulted in additional spend for our infrastructure.
We determined to deal with that drawback in a pursuit to lower the fee to function Astra.
The Drawback with Fastened-Measurement Chunks
The most important drawback with fixed-sized chunks was the truth that not all of our chunks have been absolutely utilized, resulting in in a different way sized chunks. Whereas assuming fixed-sized chunks simplified the code, it additionally led to us allocating extra space than required on our cache nodes, leading to pointless spend.
Beforehand, every cache node was given a set variety of slots, the place every slot could be assigned a piece. Whereas this simplified the code, it meant that undersized chunks of knowledge would have extra space allotted for them than required.
As an illustration, on a 3TB cache node, we’d have 200 slots, the place every slot was anticipated to carry a 15GB chunk. Nevertheless, if any chunks have been undersized (say 10GB as an alternative of 15GB), this is able to end in additional area (5GB) being allotted however not used. On clusters the place we’d have 1000’s of chunks, this rapidly led to a fairly giant proportion of area being allotted however unused.
A further drawback with fixed-sized chunks was that some chunks have been truly larger than our assumed dimension. This might probably occur at any time when Astra created a restoration process to compensate for older information. We create restoration duties primarily based on the variety of messages that we’re behind and not the scale of knowledge we’re behind. If the typical dimension of every message is larger than we anticipate, this can lead to an outsized chunk being created, which is even worse than undersized chunks because it means we aren’t allocating sufficient area.
Designing Dynamic Chunks
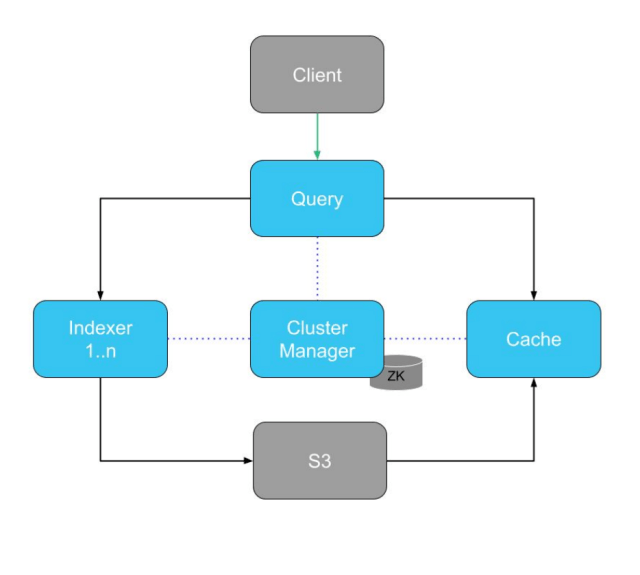 Astra’s structure diagram – “ZK” is the Zookeeper retailer which holds metadata.
Astra’s structure diagram – “ZK” is the Zookeeper retailer which holds metadata.
To be able to construct dynamic chunks, we needed to modify two components of Astra: the Cluster Supervisor and the Cache.
Redesigning Cache Nodes
We first checked out how cache nodes are structured: Beforehand, at any time when a cache node got here on-line, it might promote its variety of slots in Zookeeper (our centralized coordination retailer). Then, the Astra supervisor would assign every slot a piece, and the cache node would go and obtain and serve that chunk.
Every cache node has a lifecycle:
- Cache node comes on-line, advertises the # of slots it has.
- Supervisor picks up on the slots, and assigns a piece to every one.
- Every cache node downloads the chunks assigned to its slots.
This had the advantage of the slots being ephemeral, which means at any time when a cache node went offline, its slots would disappear from Zookeeper, and the supervisor would reassign the chunks the slots used to carry.
Nevertheless, with dynamic chunks, every cache node may solely promote their capability, as it might not know forward of time what number of chunks it might be assigned. This meant we sadly may now not depend on slots to supply these advantages to us.
To repair these two issues, we determined to persist two new forms of information in Zookeeper: the cache node task and the cache node metadata.
Right here’s a fast breakdown:
- Cache Node Task: a mapping of chunk ID to cache node
- Cache Node Metadata: metadata about every cache node, together with capability, hostname, and so forth.
Using these two new forms of information, the brand new circulation seems like this:
- Cache node comes on-line, advertises its disk area.
- Supervisor picks up on the disk area every cache node has, and creates assignments for every cache node, using bin packing to reduce the variety of cache nodes it makes use of.
- Cache nodes decide up on the assignments that have been created for it, and downloads its chunks.
Redesigning the supervisor
The following change was within the supervisor, upgrading it to make the most of the 2 new forms of information we launched: the cache node assignments and the cache node metadata.
To make the most of the cache node assignments, we determined to implement first-fit bin packing to determine which cache node needs to be assigned which chunk. We then used the cache node metadata as a way to make applicable selections concerning whether or not or not we may match a sure chunk right into a given cache node.
Beforehand, the logic for assigning slots was:
- Seize the checklist of slots
- Seize the checklist of chunks to assign
- Zip down each lists, assigning a slot to a piece
Now, the logic seems like this:
- Seize checklist of chunks to assign
- Seize checklist of cache nodes
- For every chunk
- Carry out first-fit bin packing to find out which cache node it needs to be assigned to
- Persist the mapping of cache node to chunk
Bin Packing
Probably the most juicy a part of redesigning the supervisor was implementing the first-fit bin packing. It’s a well known drawback of minimizing the variety of bins (cache nodes) used to carry a certain quantity of things (chunks). We determined to make use of first-fit bin packing, favoring it for its velocity and ease of implementation.
Utilizing pseudocode, we describe the bin-packing algorithm:
for every chunk
for every cache node
if the present chunk matches into the cache node:
assign the chunk
else:
transfer on to the subsequent cache node
if there aren’t any cache nodes left and the chunk hasn’t been assigned:
create a brand new cache nodeThis helped be sure that we have been capable of pack the cache nodes as tightly as doable, leading to a better utilization of allotted area.
Rolling it out
General, this was a big change to the Astra codebase. It touched many key components of Astra, basically rewriting the entire logic that dealt with the task and downloading of chunks. With such a change, we wished to watch out with the roll out to make sure that nothing would break.
To make sure nothing would break we did the next:
- Hosted two replicas of the identical information
- Positioned all dynamic chunk code behind a characteristic flag
We leaned closely on these two guardrails as a way to guarantee a secure roll out.
Internet hosting two replicas of the identical information allowed us to incrementally deploy to one of many two replicas and monitor its habits. It additionally ensured that if our adjustments ever broke something, we’d nonetheless have a second duplicate capable of serve the information.
Having all of the code behind a characteristic flag allowed us to merge the code into grasp early on, because it wouldn’t run until explicitly enabled. It additionally allowed us to incrementally roll out and check our adjustments. We began with smaller clusters, earlier than shifting on to larger and larger clusters after verifying every part labored.
Outcomes
What sort of outcomes did we find yourself seeing from this? For starters, we have been capable of scale back the # of cache nodes required by as much as 50% for our clusters with many undersized chunks! General our cache node prices have been diminished by 20%, giving us important value financial savings for working Astra.
Acknowledgments
An enormous shout out to everybody who has helped alongside the best way to carry dynamic chunks to life:
- Bryan Burkholder
- George Luong
- Ryan Katkov
Occupied with constructing progressive tasks and making builders’ work lives simpler? We’re hiring 💼











{kind=link}