At Slack, we handle tens of 1000’s of EC2 cases that host quite a lot of providers, together with our Vitess databases, Kubernetes employees, and varied elements of the Slack utility. The vast majority of these cases run on some model of Ubuntu, whereas a portion operates on Amazon Linux. With such an enormous infrastructure, the essential query arises: how can we effectively provision these cases and deploy adjustments throughout them? The answer lies in a mixture of internally-developed providers, with Chef enjoying a central position. On this weblog submit, I’ll focus on the evolution of our Chef infrastructure through the years and the challenges we encountered alongside the way in which.
A journey down reminiscence lane: our earlier course of
Within the early days of Slack, we relied on a single Chef stack. Our Chef infrastructure included a set of EC2 cases, an AWS utility load balancer, an RDS cluster, and an AWS OpenSearch cluster. As our fleet of cases began to develop, we scaled up and out this stack to match our growing demand.
We had three environments on this Chef stack: Sandbox, Dev, and Prod. Nodes from every setting in our fleet have been mapped to one among these environments. Slack has two varieties of cookbooks: cookbooks we obtain from the Chef Grocery store and those which can be internally created. When these cookbooks are modified, we add them utilizing a course of referred to as DishPig. When a change is merged to our repo, we triggered a CI job to search for any adjustments to the cookbooks or roles and constructed an artifact with this. Then this artifact will get uploaded to a S3 bucket after which from this S3 bucket, we notify an SQS queue. We triggered the DishPig course of on the highest of every hour to search for any new messages within the queue. When DishPig detected a brand new occasion within the queue, it downloaded the artifact and uploaded the modified cookbooks to the Chef server. We add the cookbooks we take from the grocery store with their very own model, however we are going to at all times add the cookbooks we create with a hard and fast model quantity. Subsequently we didn’t have a number of variations of the cookbooks we created and solely a single model of them have been accessible on the Chef server.
As soon as the cookbooks have been uploaded to the Chef server, all three environments have been up to date to incorporate the newest variations of the Grocery store cookbooks. Since we’re importing our personal cookbooks with the identical model, their references within the environments didn’t want updating.
With this method, all our environments bought the adjustments on the hour.

We additionally offered tooling that allowed builders to create customized Chef environments with particular variations of cookbooks, enabling them to check their adjustments on a small set of nodes inside a brief setting. As soon as testing was full, the tooling would routinely clear up the non permanent setting and take away the customized cookbook variations.
This method had a couple of important drawbacks: all adjustments have been deployed throughout all environments concurrently. This meant that any defective adjustments might doubtlessly disrupt all present Chef runs and new server provisions throughout our whole infrastructure.
Counting on a single Chef stack additionally meant that any points with this stack might have widespread results, doubtlessly impacting our whole infrastructure.
Transitioning to a sharded Chef infrastructure
As our infrastructure grew quickly, making certain assured reliability turned a prime precedence. We acknowledged that counting on a single Chef stack posed a major danger, because it was a significant single level of failure. To deal with this, we started redesigning our Chef infrastructure, beginning by eliminating our dependence on a single Chef stack.
We determined to create a number of Chef stacks to distribute the load extra successfully and guarantee resilience. This method additionally gave us the flexibleness to direct new provisions to the remaining operational Chef stacks if one have been to fail. Nonetheless, implementing this new technique launched a number of challenges. Let’s discover essentially the most important ones.
Problem 1: Assigning a shard to a node
Our first step was to discover a methodology for steering new provisions to particular shards. We achieved this utilizing an AWS Route53 Weighted CNAME document. When an occasion spins up, it queries the CNAME document and, based mostly on the assigned weight, receives a document from the set. This document then determines which Chef stack the occasion can be assigned to.
Moreover, as illustrated under, we separated the event and manufacturing Chef infrastructure into distinct stacks. This segregation helps strengthen the boundary between our growth and manufacturing environments.

Problem 2: Neighborhood discovery
Traditionally, Slack lacked a devoted EC2 stock administration system, and our Chef stack was the closest various. Because of this, groups started querying the Chef server at any time when they wanted details about particular cases within the fleet. They’d use Chef search to find nodes based mostly on standards, similar to nodes with a selected Chef position in a particular AWS area.
This method labored properly till we moved to a sharded Chef infrastructure. With the brand new setup, operating the identical question would solely return nodes from the precise Chef stack you queried. Since nodes are actually distributed throughout a number of Chef stacks, this methodology not gives an entire view of all cases.
Let’s take a step again and have a look at how a Chef run operates. A Chef run consists of two phases: compile and converge. Throughout the compile part, Chef collects details about its run lists, reads all its cookbooks, assigns variables, creates attributes, and maps out the assets it must create. Within the converge part, Chef then creates these assets based mostly on the knowledge gathered within the compile part.
A few of our cookbooks have been designed to create attributes and variables based mostly on the outcomes from Chef searches. With the transition to sharded Chef stacks, we wanted to seek out a substitute for these node discovery strategies. After contemplating our choices, we determined to leverage an present service at Slack: Consul.
We started registering sure providers in Consul for service discovery, profiting from Consul’s tagging capabilities. By creating and registering providers, we might now question Consul for details about different nodes, changing the necessity for Chef searches.
Nonetheless, this launched a brand new problem. At Slack, we use an overlay community referred to as Nebula, which transparently handles community encryption between endpoints. To question Consul, cases have to be linked by Nebula. But, Nebula is configured by Chef, making a round dependency downside. We couldn’t arrange attributes or variables utilizing Consul throughout Chef’s compile part, resulting in a traditional chicken-and-egg state of affairs.
After some consideration, we devised an answer utilizing Chef’s ruby_block assets. We positioned the logic for creating assets and assigning variables inside these ruby_block assets. Since ruby_block assets are executed solely throughout the converge part of the Chef run, we will management the execution order to make sure that Nebula is put in and configured earlier than these assets are processed.
Nonetheless, for values calculated inside Ruby blocks that have to be used elsewhere, we make the most of the lazy key phrase. This ensures that these values are loaded throughout the Chef converge part.
We additionally developed a set of Chef library capabilities to facilitate node lookups based mostly on varied tags, service names, and different standards. This allowed us to duplicate the performance we beforehand achieved with Chef search. We built-in these helper capabilities into our cookbooks, enabling us to retrieve the required values from Consul effectively.
Instance:
node.override['some_attribute'] = []
# In Chef, when a useful resource is outlined all its variables are evaluated throughout
# compile time and the execution of the useful resource takes place in converge part.
# So if the worth of a selected attribute is modified in converge
# (and never in compile) the useful resource can be executed with the outdated worth.
# Subsequently we have to put the next name contained in the ruby block as a result of,
# We want to ensure Nebula is up so we will connect with Consul (Nebula will get stup throughout converge time)
ruby_block 'lets_set_some_attribute' do
block do
lengthen SomeHelper
node.override['some_attribute'] = consul_service_lookup_helper_func()
finish
finish
# Please observe that we're not utilizing `lazy` with the `only_if` under for the worth that's calculated within the ruby block above
# It is as a result of `only_if` is already lazy
# https://github.com/chef/chef/points/10243#issuecomment-668187830
systemd_unit 'some_service' do
motion [:enable, :start]
only_if { node.override['some_attribute'].empty?
finishThough this method required including giant Ruby blocks with complicated logic to some cookbooks, it allowed us to effectively roll out a number of Chef stacks. In the event you’re a Chef knowledgeable with strategies for a greater methodology, we’d love to listen to from you. Please don’t hesitate to succeed in out!
Problem 3: Looking out Chef
As talked about earlier, we initially relied on Chef as a list administration system. This method was helpful for locating details about nodes and their attributes inside our fleet. For example, we might observe the progress of function rollouts utilizing these attributes. To facilitate Chef searches and reporting for builders, we created an interface referred to as Gaz.
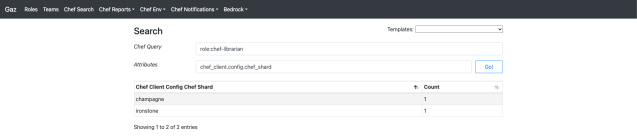
This method labored properly with a single Chef stack, however with a number of stacks in play, we wanted a brand new resolution. We developed a service referred to as Shearch (Sharded Chef Search) which options an API that accepts Chef queries, runs them throughout a number of shards, and consolidates the outcomes. This permits us to make use of Shearch behind Gaz, reasonably than having Gaz work together immediately with a Chef stack.
Moreover, we changed the Knife command on our growth containers with a brand new software referred to as Gnife (a nod to “Go Knife,” because it’s written in Go). Gnife affords the identical performance because the Chef Knife command however operates throughout a number of shards utilizing the Shearch service.
We additionally needed to replace lots of our internally developed instruments and libraries to make use of the Shearch service as an alternative of interacting immediately with a Chef stack. As you’ll be able to think about, this required appreciable effort.
Sharding our Chef infrastructure considerably enhanced its resilience. Nonetheless, we nonetheless confronted challenges with how we deploy our cookbooks. At the moment, we replace all our environments concurrently and add the identical cookbook variations throughout the board. We would have liked a extra environment friendly method to enhance this course of.
Problem 4: Cookbook uploads
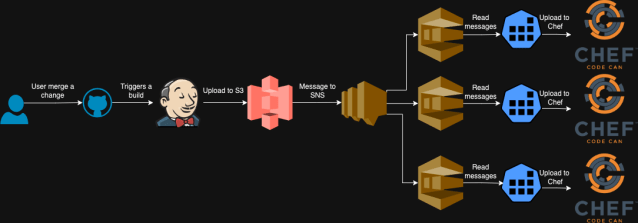
To implement this alteration shortly, we determined to retain our present DishPig cookbook uploader utility. Nonetheless, since DishPig was designed to work with a single Chef stack, we needed to deploy a number of cases of the applying, every devoted to a particular stack.
We modified our S3 bucket to ship notifications to an SNS subject (as an alternative of on to SQS), which then fanned out these messages to a number of SQS queues, every akin to a distinct DishPig deployment. This setup allowed adjustments to be uploaded independently to every Chef stack with none consistency checks between them.
For instance, we encountered points the place artifacts constructed near the highest of the hour (when DishPig is triggered) resulted in SQS messages reaching some queues on time however not others. This led to Chef stacks having totally different variations of cookbooks. Whereas we did create a small monitoring system to test for and alert on consistency errors, it was removed from a really perfect resolution.
Cookbook versioning and Chef Librarian
We would have liked an answer that may permit us to model our cookbooks and replace environments independently, whereas additionally managing a number of Chef stacks and making certain they continue to be in sync. Moreover, it was essential for the applying to trace what adjustments are included in every model and the place it has been deployed. To deal with these necessities, we designed a brand new service referred to as Chef Librarian to switch our earlier service, DishPig, as mentioned earlier.
Our cookbooks are managed inside a single Git repository. Internally developed cookbooks are saved within the site-cookbooks listing, whereas Grocery store cookbooks are saved within the cookbooks listing.
. ├── cookbooks │ ├── supermarket-cookbook-1 │ │ ├── information │ │ │ └── default │ │ │ └── file1.txt │ │ └── recipes │ │ └── default.rb │ └── supermarket-cookbook-2 │ ├── information │ │ └── default │ │ └── file1.txt │ └── recipes │ └── default.rb ├── site-cookbooks │ ├── our-cookbook-1 │ │ ├── information │ │ │ └── default │ │ │ └── file1.txt │ │ └── recipes │ │ └── default.rb │ └── our-cookbook-2 │ ├── information │ │ └── default │ │ └── file1.txt │ └── recipes │ └── default.rb └── roles ├── sample-role-1.json └── sample-role-2.json
When adjustments to any of these things are merged, we use GitHub Actions to set off a construct job. This job creates a tarball that features a full copy of the repository. For internally developed cookbooks, we replace the model quantity within the site-cookbooks listing to a brand new model utilizing the usual Chef cookbook versioning format: YYYYMMDD.TIMESTAMP.0 (e.g., 20240809.1723164435.0). The model numbers for Grocery store cookbooks stay unchanged except we fetch a brand new model from the upstream supply.
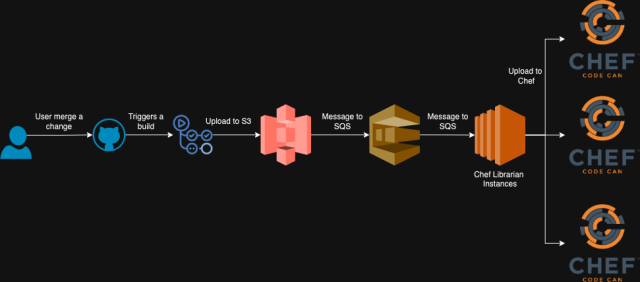
As soon as the artifact is constructed, GitHub Actions uploads it to S3. S3 then generates a notification in an SQS queue, which the Chef Librarian utility listens to. Chef Librarian promptly processes the brand new artifact and uploads the up to date variations of cookbooks to all our Chef stacks. Though these new variations are actually on the Chef stacks, they received’t be utilized till explicitly specified.
With this method, we add all cookbooks, no matter whether or not they have modified or not, to the Chef stacks with the brand new model.
Now we have developed two API endpoints for the Chef Librarian utility:
/update_environment_to_version– This endpoint updates an setting to a specified model. To make use of it, ship a POST request with parameters together with the goal setting and the model to replace to./update_environment_from_environment– This endpoint updates an setting to match the variations of one other setting.
We now have the flexibility to replace environments to particular variations independently of one another. This permits us to first replace the sandbox and growth environments, monitor metrics for any potential points, and guarantee stability earlier than selling the artifact to manufacturing.
In follow, which means that any problematic adjustments deployed to Chef don’t influence all environments concurrently. We will detect and tackle errors earlier, stopping them from propagating additional.
Chef Librarian additionally shops artifact variations, the environments they’re deployed to, and different state-related data in DynamoDB. This makes it a lot simpler for us to trace adjustments and visualize our rollout course of.
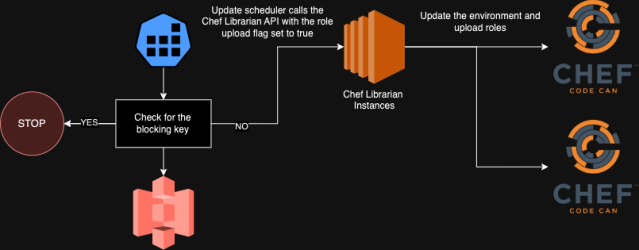
Nonetheless, Chef roles are a distinct problem since they aren’t versioned. If you add them, they propagate throughout all environments, making position updates a dangerous operation. To deal with this, we’ve stripped many of the logic out of our Chef roles, leaving them with solely primary data and a run listing. Moreover, as a result of we’ve break up our Chef infrastructure into dev and prod environments, we solely add roles to the related Chef stacks when their corresponding environments are up to date (e.g., roles are uploaded to prod shards solely when the prod setting is up to date).

At the moment, we use a Kubernetes CronJob to name the API endpoints mentioned earlier on a schedule, selling variations throughout our environments. Nonetheless, this course of first checks for a key in a chosen S3 bucket to make sure that promotions will not be blocked earlier than continuing. Which means if we detect failures within the sandbox or dev environments, we will place this key within the bucket to forestall additional promotion of artifact variations.
At current, it is a guide course of triggered by a human after they obtain alerts about Chef run failures or provisioning points. Our aim, nevertheless, is to switch this Kubernetes CronJob with a extra clever system that may routinely monitor metrics and impose these blocks with out human intervention.
We’ve additionally developed an interface for Chef Librarian, permitting customers to view which artifacts have been uploaded with particular commits, in addition to when an setting was up to date to a selected model in a particular Chef shard.

We developed a Slack app for the Chef Librarian utility, permitting us to inform customers when their adjustments are being promoted to an setting. The app identifies the consumer who made the change by inspecting the Git commit after which makes use of the Slack API to lookup their Slack deal with. This permits us to tag the consumer immediately within the notification, making certain they’re promptly knowledgeable when the message is posted.
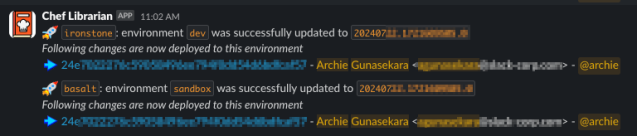
What’s subsequent?
Though we’ve made important strides in enhancing deployment security, there’s nonetheless way more we will do. One avenue we’re exploring is additional segmentation of our Chef environments. For instance, we’re contemplating breaking down our manufacturing Chef environments by AWS availability zones, permitting us to advertise adjustments independently inside every zone and stop unhealthy adjustments from being deployed in all places concurrently.
One other long-term possibility we’re investigating is the adoption of Chef PolicyFiles and PolicyGroups. Whereas this represents a major departure from our present setup, it might supply a lot larger flexibility and security when deploying adjustments to particular nodes.
Implementing these adjustments at our scale is a fancy endeavor. We’re nonetheless conducting analysis and assessing the potential impacts and advantages. There’s a number of thrilling work occurring on this house at Slack, so keep tuned to our weblog for extra updates on the cool tasks we’re engaged on!











{kind=link}