In a earlier weblog publish—A Simple Kubernetes Admission Webhook—I mentioned the method of making a Kubernetes webhook with out counting on Kubebuilder. At Slack, we use this webhook for numerous duties, like serving to us assist long-lived Pods (see Supporting Long-Lived Pods), and immediately, I delve as soon as extra into the subject of long-lived Pods, specializing in our strategy to deploying stateful purposes by way of custom resources managed by Kubebuilder.
Lack of management
A lot of our groups at Slack use StatefulSets to run their purposes with stateful storage, so StatefulSets are naturally a superb match for distributed caches, databases, and different stateful companies that depend on distinctive Pod id and chronic exterior volumes.
Natively in Kubernetes, there are two methods of rolling out StatefulSets, two replace methods, set by way of the .spec.updateStrategy discipline:
- When a StatefulSet’s .spec.updateStrategy.kind is ready to OnDelete, the StatefulSet controller won’t mechanically replace the Pods in a StatefulSet. Customers should manually delete Pods to trigger the controller to create new Pods that replicate modifications made to a StatefulSet’s .spec.template.
- The RollingUpdate replace technique implements automated, rolling updates for the Pods in a StatefulSet. That is the default replace technique.
RollingUpdate comes full of options like Partitions (percent-based rollouts) and .spec.minReadySeconds to decelerate the tempo of the rollouts. Sadly the maxUnavailable field for StatefulSet remains to be alpha and gated by the MaxUnavailableStatefulSet api-server function flag, making it unavailable to be used in AWS EKS on the time of this writing.
Which means that utilizing RollingUpdate solely lets us roll out one Pod at a time, which could be excruciatingly gradual to deploy purposes with a whole lot of Pods.
OnDelete nonetheless lets the person management the rollout by deleting the Pods themselves, however doesn’t include RollingUpdate’s bells and whistles like percent-based rollouts.
Our inner groups at Slack had been asking us for extra managed rollouts: they wished quicker percent-based rollouts, quicker rollbacks, the power to pause rollouts, an integration with our inner service discovery (Consul), and naturally, an integration with Slack to replace groups on rollout standing.
Bedrock rollout operator
So we constructed the Bedrock Rollout Operator: a Kubernetes operator that manages StatefulSet rollouts. Bedrock is our inner platform; it supplies Slack engineers opinionated configuration for Kubernetes deployments by way of a easy config interface and highly effective, easy-to-use integrations with the remainder of Slack, similar to:
…and it has nothing to do with AWS’ new generative AI service of the identical title!
We constructed this operator with Kubebuilder, and it manages a {custom} useful resource named StatefulsetRollout. The StatefulsetRollout useful resource accommodates the StatefulSet Spec in addition to further parameters to supply numerous further options, like pause and Slack notifications. We’ll have a look at an instance in a later part on this publish.
Structure
At Slack, engineers deploy their purposes to Kubernetes through the use of our inner Bedrock tooling. As of this writing, Slack has over 200 Kubernetes clusters, over 50 stateless companies (Deployments) and almost 100 stateful companies (StatefulSets). The operator is deployed to every cluster, which lets us management who can deploy the place. The diagram beneath is a simplification displaying how the items match collectively:
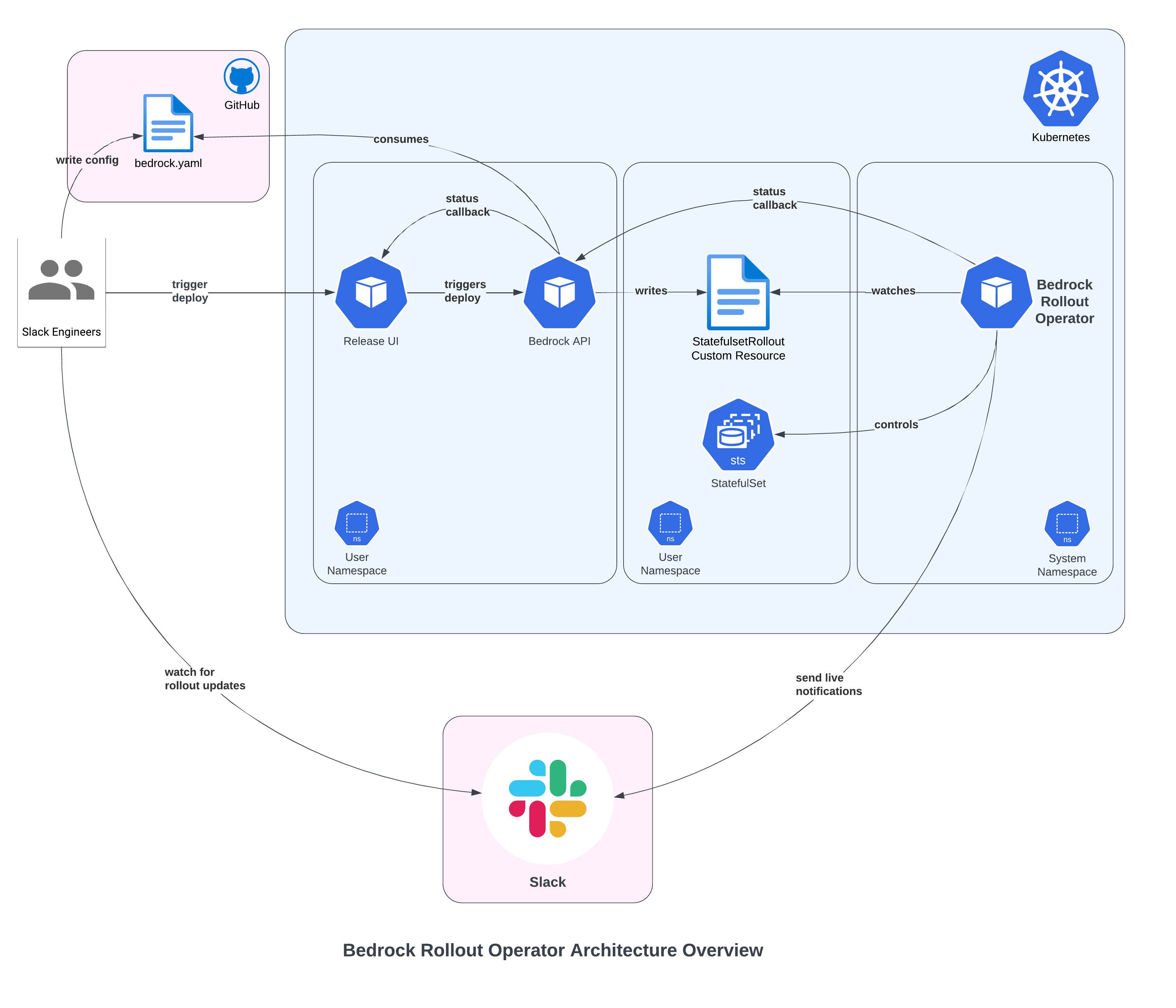
Rollout circulate
Following the diagram above, right here’s an end-to-end instance of a StatefulSet rollout.
1. bedrock.yaml
First, Slack engineers write their intentions in a `bedrock.yaml` config file saved of their app repository on our inner Github. Right here’s an instance:
photographs:
bedrock-tester:
dockerfile: Dockerfile
companies:
bedrock-tester-sts:
notify_settings:
launch:
degree: "debug"
channel: "#devel-rollout-operator-notifications"
variety: StatefulSet
disruption_policy:
max_unavailable: 50%
containers:
- picture: bedrock-tester
phases:
dev:
technique: OnDelete
orchestration:
min_pod_eviction_interval_seconds: 10
phases:
- 1
- 50
- 100
clusters:
- playground
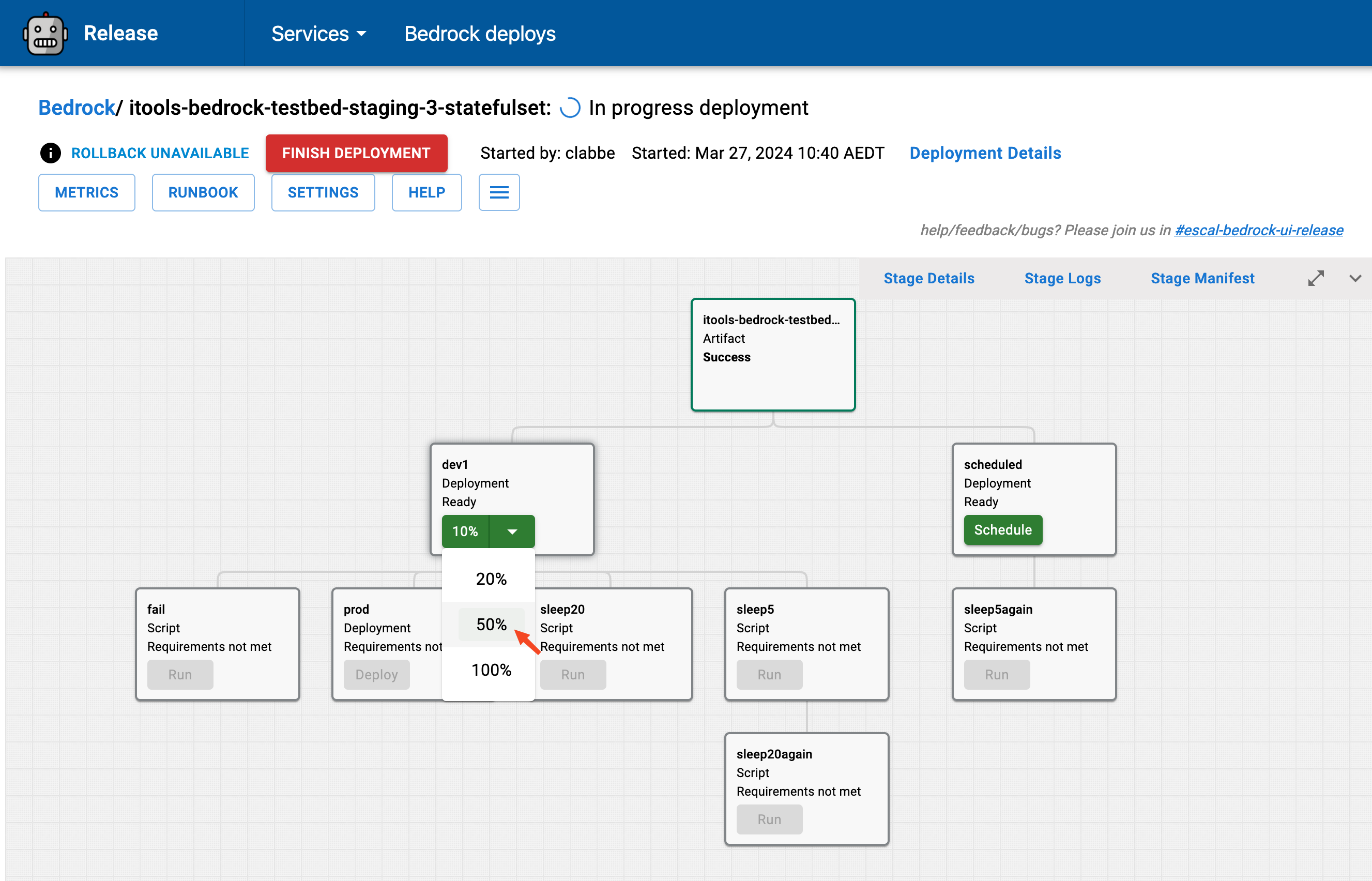
replicas: 22. Launch UI
Then, they go to our inner deploy UI to impact a deployment:
3. Bedrock API
The Launch platform then calls to the Bedrock API, which parses the person bedrock.yaml and generates a StatefulsetRollout useful resource:
apiVersion: bedrock.operator.slack.com/v1
variety: StatefulsetRollout
metadata:
annotations:
slack.com/bedrock.git.department: grasp
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
app.kubernetes.io/model: v1.custom-1709074522
title: bedrock-tester-sts-dev
namespace: default
spec:
bapi:
bapiUrl: http://bedrock-api.inner.url
stageId: 2dD2a0GTleDCxkfFXD3n0q9msql
channel: '#devel-rollout-operator-notifications'
minPodEvictionIntervalSeconds: 10
pauseRequested: false
%: 25
rolloutIdentity: GbTdWjQYgiiToKdoWDLN
serviceDiscovery:
dc: cloud1
serviceNames:
- bedrock-tester-sts
statefulset:
apiVersion: apps/v1
variety: StatefulSet
metadata:
annotations:
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
title: bedrock-tester-sts-dev
namespace: default
spec:
replicas: 4
selector:
matchLabels:
app: bedrock-tester-sts-dev
template:
metadata:
annotations:
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
spec:
containers:
picture: account-id.dkr.ecr.us-east-1.amazonaws.com/bedrock-tester@sha256:SHA
title: bedrock-tester
updateStrategy:
kind: OnDeleteLet’s have a look at the fields within the high degree of the StatefulsetRollout spec, which give the additional functionalities:
bapi: This part accommodates the main points wanted to name again to the Bedrock API as soon as a rollout is full or has failedchannel: The Slack channel to ship notifications tominPodEvictionIntervalSeconds: Non-obligatory; the time to attend between every Pod rotationpauseRequested: Non-obligatory; will pause an ongoing rollout if set to true%: Set to 100 to roll out all Pods, or much less for a percent-based deployrolloutIdentity: We go a randomly generated string to this rollout as a option to allow retries when a rollout has failed however the problem was transient.serviceDiscovery: This part accommodates the main points associated to the service Consul registration. That is wanted to question Consul for the well being of the service as a part of the rollout.
Be aware that the disruption_policy.max_unavailable that was current within the bedrock.yaml doesn’t present up within the {custom} useful resource. As a substitute, it’s used to create a Pod disruption policy. At run-time, the operator reads the Pod disruption coverage of the managed service to determine what number of Pods it may roll out in parallel.
4. Bedrock Rollout Operator
Then, the Bedrock Rollout Operator takes over and converges the prevailing state of the cluster to the specified state outlined within the StatefulsetRollout. See “The Reconcile Loop” part beneath for extra particulars.
5. Slack notifications
We used Block Kit Builder to design wealthy Slack notifications that inform customers in actual time of the standing of the continued rollout, offering particulars just like the model quantity and the listing of Pods being rolled out:
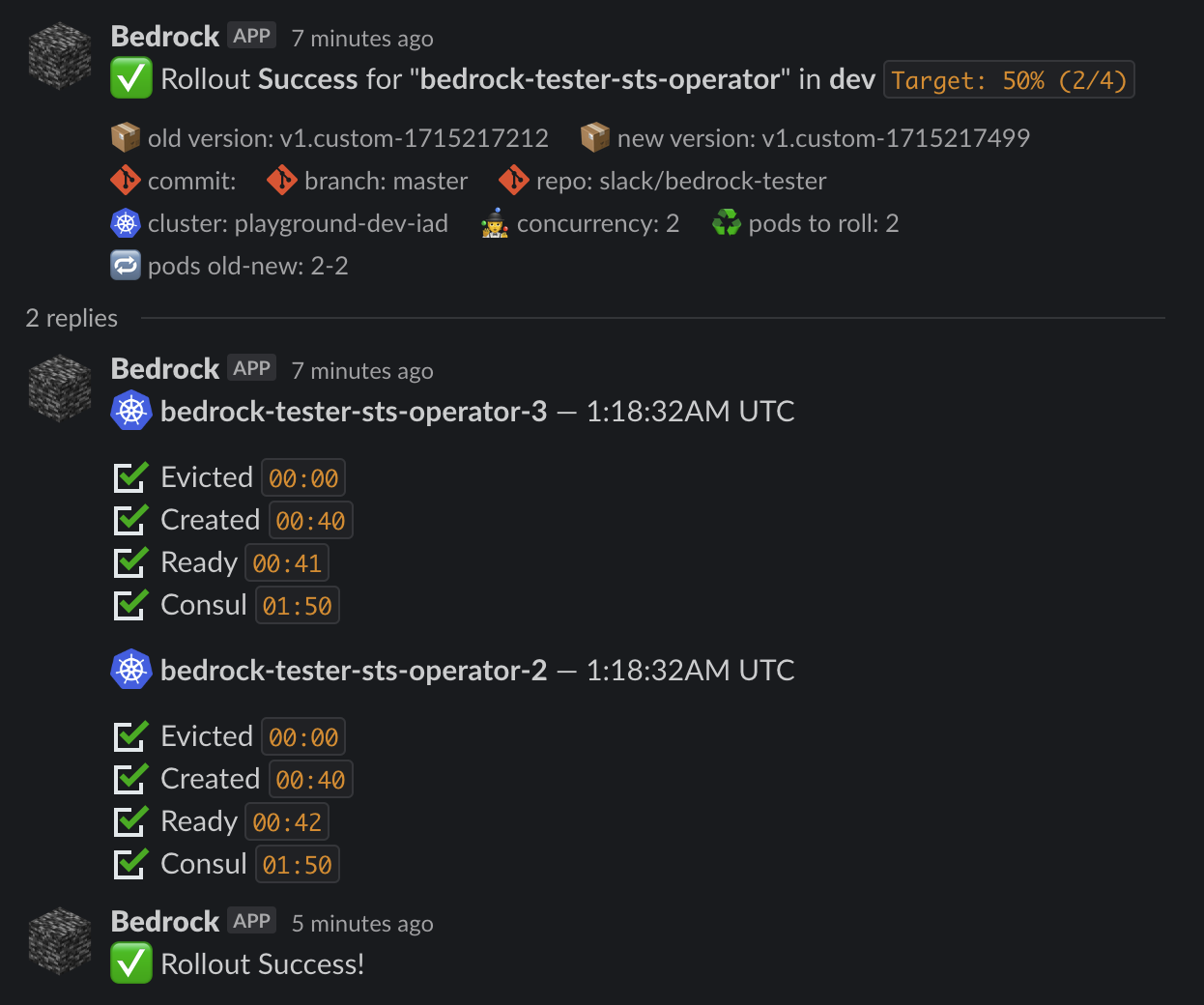
6. Callbacks
Whereas Slack notifications are good for the tip customers, our techniques additionally have to know the state of the rollout. As soon as completed converging a StatefulsetRollout useful resource, the Operator calls again to the Bedrock API to tell it of the success or failure of the rollout. Bedrock API then sends a callback to Launch for the standing of rollout to be mirrored within the UI.
The reconcile loop
The Bedrock Rollout Operator watches the StatefulsetRollout useful resource representing the desired state of the world, and reconciles it towards the actual world. This implies, for instance, creating a brand new StatefulSet if there isn’t one, or triggering a brand new rollout. A typical rollout is completed by making use of a brand new StatefulSet spec after which terminating a desired quantity of Pods (half of them in our %: 50 instance).
The core performance of the operator lies throughout the reconcile loop through which it:
- Appears on the anticipated state: the spec of the {custom} useful resource
- Appears on the state of the world: the spec of the StatefulSet and of its Pods
- Takes actions to maneuver the world nearer to the anticipated state, for instance by:
- Updating the StatefulSet with the most recent spec supplied by the person; or by
- Evicting Pods to get them changed by Pods operating the newer model of the appliance being rolled out
When the {custom} useful resource is up to date, we start the reconciliation loop course of. Usually after that, Kubernetes controllers watch the sources they give the impression of being after and work in an event-driven style. Right here, this might imply watching the StatefulSets and its Pods. Every time one among them will get up to date, the reconcile loop would run.
However as a substitute of working on this event-driven means, we determined to work by enqueuing the following reconcile loop ourselves: so long as we’re anticipating change, we re-enqueue a request sooner or later. As soon as we attain a ultimate state like RolloutDone or RolloutFailed, we merely exit with out re-enqueueing. Working on this style has a couple of benefits and results in so much much less reconciliations. It additionally enforces reconciliations being achieved sequentially for a given {custom} useful resource, which dodges race situations introduced by mutating a given {custom} useful resource in reconcile loops operating in parallel.
Right here’s a non-exhaustive circulate chart illustrating the way it works for our StatefulsetRollout (Sroll for brief) {custom} useful resource:
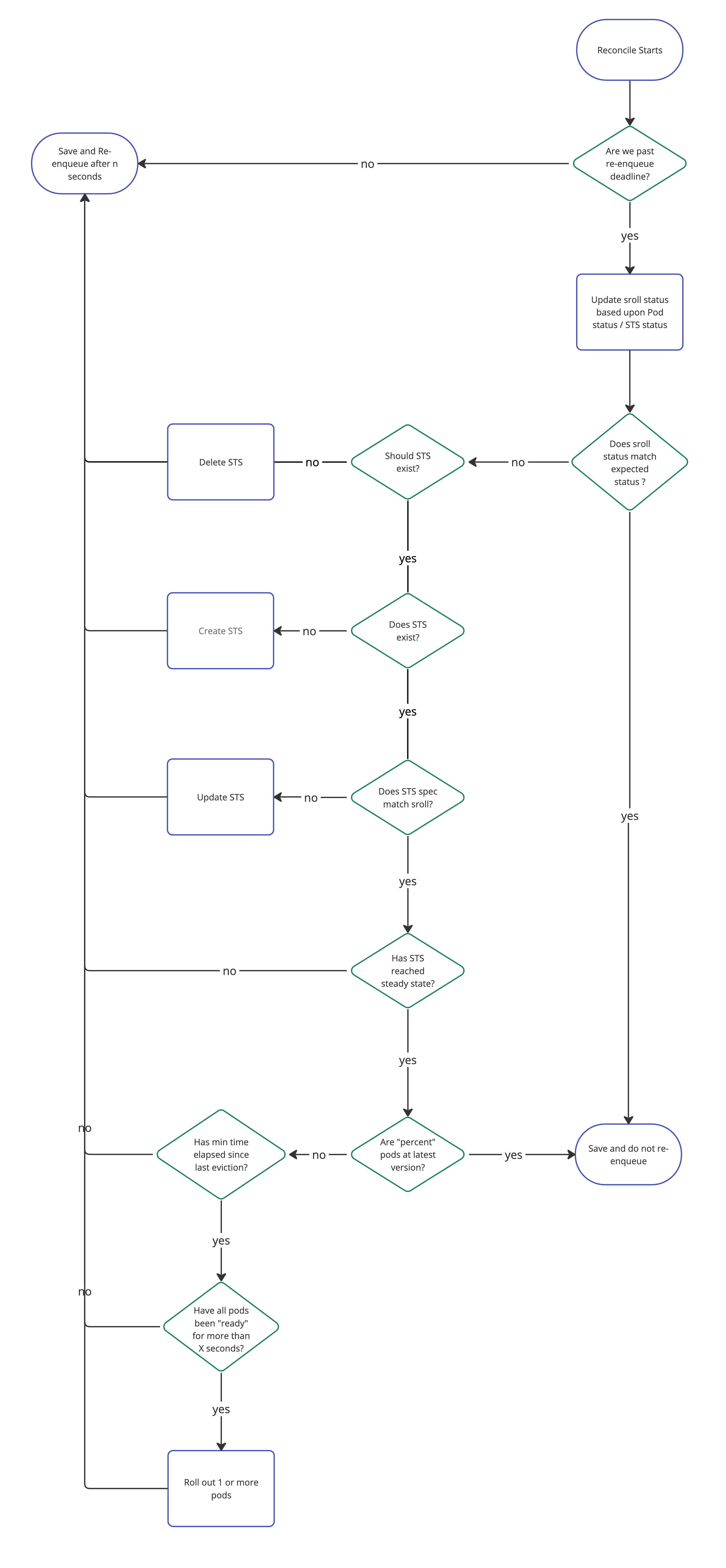
As you’ll be able to see, we’re making an attempt to do as little as we are able to in every reconciliation loop: we take one motion and re-enqueue a request a couple of seconds sooner or later. This works nicely as a result of it retains every loop quick and so simple as doable, which makes the operator resilient to disruptions. We obtain this by saving the final resolution the loop took, specifically the `Part` data, within the standing of the {custom} useful resource. Right here’s what the StatefulsetRollout standing struct seems to be like:
// StatefulsetRolloutStatus defines the noticed state of StatefulsetRollout
kind StatefulsetRolloutStatus struct {
// The Part is a excessive degree abstract of the place the StatefulsetRollout is in its lifecycle.
Part RolloutPhase `json:"part,omitempty"`
// PercentRequested ought to match Spec.P.c on the finish of a rollout
PercentRequested int `json:"percentDeployed,omitempty"`
// A human readable message indicating particulars about why the StatefulsetRollout is on this part.
Motive string `json:"cause,omitempty"`
// The variety of Pods presently displaying prepared in kube
ReadyReplicas int `json:"readyReplicas"`
// The variety of Pods presently displaying prepared in service discovery
ReadyReplicasServiceDiscovey int `json:"readyReplicasRotor,omitempty"`
// Paused signifies that the rollout has been paused
Paused bool `json:"paused,omitempty"`
// Deleted signifies that the statefulset underneath administration has been deleted
Deleted bool `json:"deleted,omitempty"`
// The listing of Pods owned by the managed sts
Pods []Pod `json:"Pods,omitempty"`
// ReconcileAfter signifies if the controller ought to enqueue a reconcile for a future time
ReconcileAfter *metav1.Time `json:"reconcileAfter,omitempty"`
// LastUpdated is the time at which the standing was final up to date
LastUpdated *metav1.Time `json:"lastUpdated"`
// LastCallbackStageId is the BAPI stage ID of the final callback despatched
//+kubebuilder:validation:Non-obligatory
LastCallbackStageId string `json:"lastCallbackStageId,omitempty"`
// BuildMetadata like department and commit sha
BuildMetadata BuildMetadata `json:"buildMetadata,omitempty"`
// SlackMessage is used to replace an current message in Slack
SlackMessage *SlackMessage `json:"slackMessage,omitempty"`
// ConsulServices tracks if the consul companies laid out in spec.ServiceDiscovery exists
// will likely be nil if no companies exist in service discovery
ConsulServices []string `json:"consulServices,omitempty"`
// StatefulsetName tracks the title of the statefulset underneath administration.
// If no statefulset exists that matches the anticipated metadata, this discipline is left clean
StatefulsetName string `json:"statefulsetName,omitempty"`
// True if the statefulset underneath administration's spec matches the sts Spec in StatefulsetRolloutSpec.sts.spec
StatefulsetSpecCurrent bool `json:"statefulsetSpecCurrent,omitempty"`
// RolloutIdentity is the id of the rollout requested by the person
RolloutIdentity string `json:"rolloutIdentity,omitempty"`
}
This standing struct is how we hold observe of the whole lot and so we save plenty of metadata right here —the whole lot from the Slack message ID, to a listing of managed Pods that features which model every is presently operating.
Limitations and studying
Supporting giant apps
Slack manages a big quantity of visitors, which we again with sturdy companies working on our Bedrock platform constructed on Kubernetes:
This offers an instance of the dimensions we’re coping with. But, we acquired stunned once we discovered that a few of our StatefulSets spin as much as 1,000 Pods which induced our Pod by Pod notifications to get charge restricted as we had been sending one Slack message per Pod, and rotating as much as 100 Pods in parallel! This pressured us to rewrite the notifications stack within the operator: we launched pagination and moved to sending messages containing as much as 50 Pods.
Model leak
A few of you may need picked up on a not-so-subtle element associated to the (ab-)use of the OnDelete technique for StatefulSets: what we internally name the model leak problem. When a person decides to do a percent-based rollout, or pause an current rollout, the StatefulSet is left with some Pods operating the brand new model and a few Pods operating the earlier model. But when a Pod operating the earlier model will get terminated for another cause than being rolled out by the operator, it’ll get changed by a Pod operating the brand new model. Since we routinely terminate nodes for various causes similar to scaling clusters, rotating nodes for compliance in addition to chaos engineering, a stopped rollout will, over time, are inclined to converge in the direction of being totally rolled out. Happily, it is a well-understood limitation and Slack engineering groups deploy their companies out to 100% in a well timed method earlier than the model leak drawback would come up.
What’s subsequent?
We’ve discovered the Kubernetes operator mannequin to be efficient, so we have now chosen to handle all Kubernetes deployments utilizing this strategy. This doesn’t essentially contain extending our StatefulSet operator. As a substitute, for managing Deployment sources, we’re exploring current CNCF initiatives similar to Argo Rollouts and OpenKruise.
Conclusion
Implementing {custom} rollout logic in a Kubernetes operator shouldn’t be easy work, and incoming Kubernetes options just like the maxUnavailable discipline for StatefulSet would possibly, someday, allow us to pull out a few of our {custom} code. Managing rollouts in an operator is a mannequin that we’re pleased with, because the operator permits us to simply ship Slack notifications for the state of rollouts in addition to combine with a few of our different inner techniques like Consul. Since this sample has labored nicely for us, we goal to develop using the operator sooner or later.
Love Kube and deploy techniques? Come be a part of us! Apply now











{kind=link}