- We’re sharing how we streamline system reliability investigations utilizing a brand new AI-assisted root trigger evaluation system.
- The system makes use of a mix of heuristic-based retrieval and enormous language model-based rating to hurry up root trigger identification throughout investigations.
- Our testing has proven this new system achieves 42% accuracy in figuring out root causes for investigations at their creation time associated to our net monorepo.
Investigation is a crucial a part of making certain system reliability, and a prerequisite to mitigating points shortly. That is why Meta is investing in advancing our suite of investigation tooling with instruments like Hawkeye, which we use internally for debugging end-to-end machine studying workflows.
Now, we’re leveraging AI to advance our investigation instruments even additional. We’ve streamlined our investigations by means of a mix of heuristic-based retrieval and enormous language mannequin (LLM)-based rating to supply AI-assisted root trigger evaluation. Throughout backtesting, this technique has achieved promising outcomes: 42% accuracy in figuring out root causes for investigations at their creation time associated to our net monorepo.
Investigations at Meta
Each investigation is exclusive. However figuring out the basis explanation for a difficulty is critical to mitigate it correctly. Investigating points in techniques depending on monolithic repositories can current scalability challenges as a result of accumulating variety of modifications concerned throughout many groups. As well as, responders have to construct context on the investigation to begin engaged on it, e.g., what’s damaged, which techniques are concerned, and who is perhaps impacted.
These challenges could make investigating anomalies a fancy and time consuming course of. AI gives a chance to streamline the method, decreasing the time wanted and serving to responders make higher choices. We centered on constructing a system able to figuring out potential code modifications that is perhaps the basis trigger for a given investigation.
Our strategy to root trigger isolation
The system incorporates a novel heuristics-based retriever that’s able to decreasing the search area from 1000’s of modifications to a couple hundred with out important discount in accuracy utilizing, for instance., code and listing possession or exploring the runtime code graph of impacted techniques. As soon as we now have decreased the search area to a couple hundred modifications related to the continued investigation, we depend on a LLM-based ranker system to determine the basis trigger throughout these modifications.
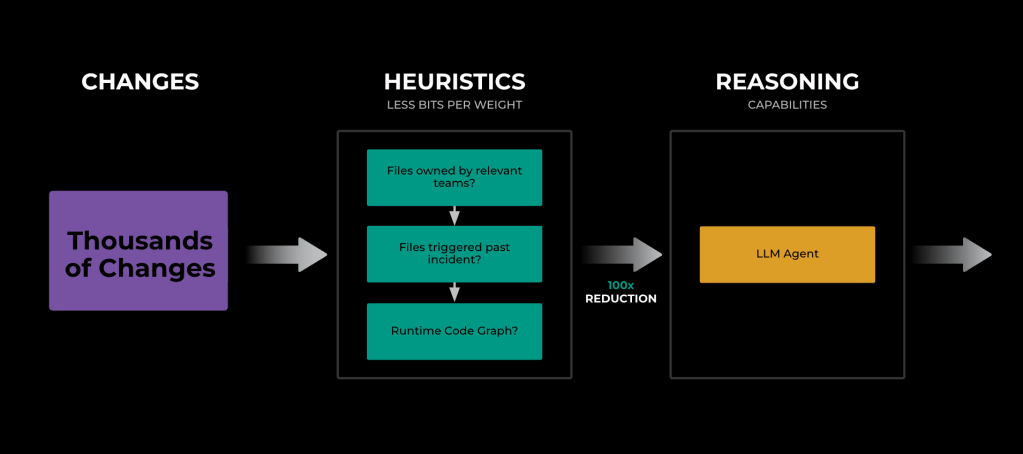
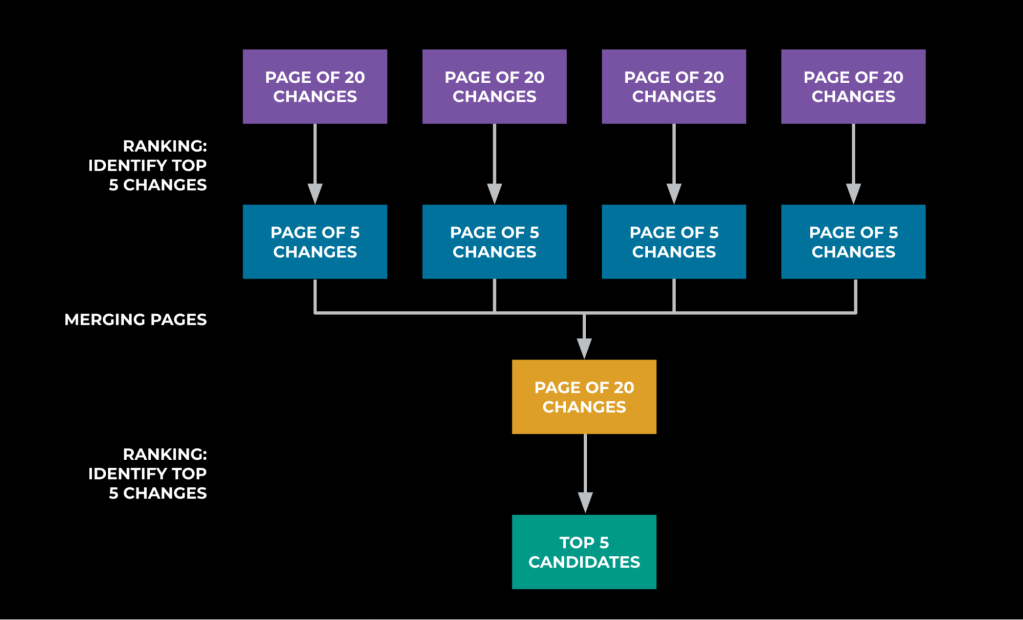
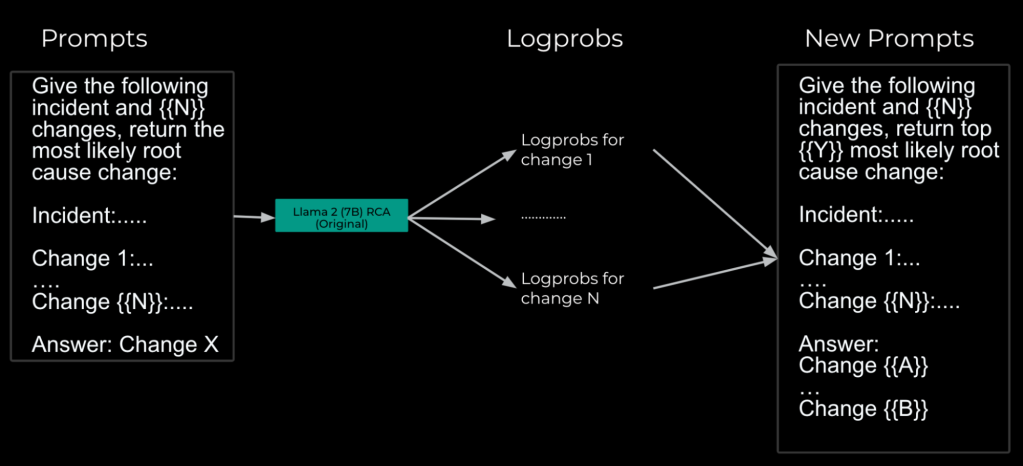
The ranker system makes use of a Llama mannequin to additional cut back the search area from a whole bunch of potential code modifications to an inventory of the highest 5. We explored totally different rating algorithms and prompting eventualities and located that rating by means of election was best to accommodate context window limitations and allow the mannequin to motive throughout totally different modifications. To rank the modifications, we construction prompts to comprise a most of 20 modifications at a time, asking the LLM to determine the highest 5 modifications. The output throughout the LLM requests are aggregated and the method is repeated till we now have solely 5 candidates left. Primarily based on exhaustive backtesting, with historic investigations and the data accessible at their begin, 42% of those investigations had the basis trigger within the high 5 steered code modifications.
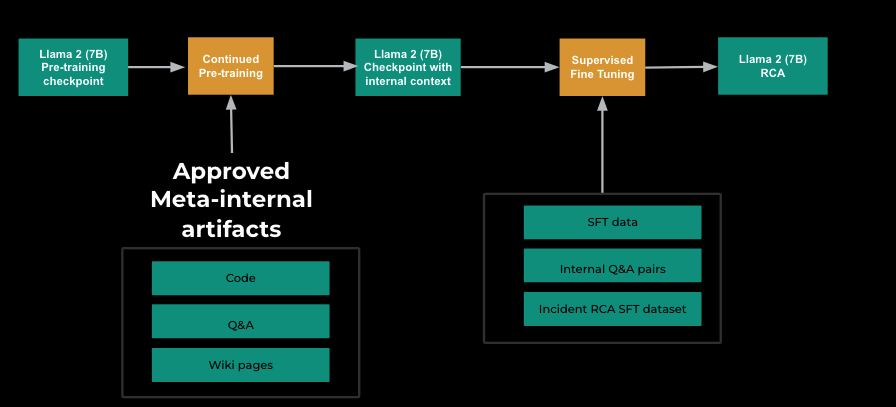
Coaching
The most important lever to reaching 42% accuracy was fine-tuning a Llama 2 (7B) mannequin utilizing historic investigations for which we knew the underlying root trigger. We began by operating continued pre-training (CPT) utilizing restricted and permitted inside wikis, Q&As, and code to reveal the mannequin to Meta artifacts. Later, we ran a supervised fine-tuning (SFT) part the place we blended Llama 2’s authentic SFT information with extra inside context and a devoted investigation root trigger evaluation (RCA) SFT dataset to show the mannequin to observe RCA directions.
Our RCA SFT dataset consists of ~5,000 instruction-tuning examples with particulars of 2-20 modifications from our retriever, together with the recognized root trigger, and knowledge recognized concerning the investigation at its begin, e.g., its title and noticed affect. Naturally, the accessible data density is low at this level, nevertheless this permits us to carry out higher in comparable real-world eventualities when we now have restricted data at the start of the investigation.
Utilizing the identical fine-tuning information format for every doable wrongdoer then permits us to assemble the mannequin’s llog chances(logprobs) and rank our search area based mostly on relevancy to a given investigation. We then curated a set of comparable fine-tuning examples the place we anticipate the mannequin to yield an inventory of potential code modifications possible accountable for the problem ordered by their logprobs-ranked relevance, with the anticipated root trigger initially. Appending this new dataset to the unique RCA SFT dataset and re-running SFT offers the mannequin the flexibility to reply appropriately to prompts asking for ranked lists of modifications related to the investigation.
The way forward for AI-assisted Investigations
The appliance of AI on this context presents each alternatives and dangers. As an illustration, it could possibly cut back time and effort wanted to root trigger an investigation considerably, however it could possibly doubtlessly recommend unsuitable root causes and mislead engineers. To mitigate this, we be sure that all employee-facing options prioritize closed suggestions loops and explainability of outcomes. This technique ensures that responders can independently reproduce the outcomes generated by our techniques to validate their outcomes. We additionally depend on confidence measurement methodologies to detect low confidence solutions and keep away from recommending them to the customers – sacrificing attain in favor of precision.
By integrating AI-based techniques into our inside instruments we’ve efficiently leveraged them for duties like onboarding engineers to investigations and root trigger isolation. Trying forward, we envision increasing the capabilities of those techniques to autonomously execute full workflows and validate their outcomes. Moreover, we anticipate that we will additional streamline the event course of by using AI to detect potential incidents previous to code push, thereby proactively mitigating dangers earlier than they come up.
Acknowledgements
We want to thank contributors to this effort throughout many groups all through Meta, significantly Alexandra Antiochou, Beliz Gokkaya, Julian Smida, Keito Uchiyama, Shubham Somani; and our management: Alexey Subach, Ahmad Mamdouh Abdou, Shahin Sefati, Shah Rahman, Sharon Zeng, and Zach Rait.











{kind=link}