- We’re sharing particulars about Strobelight, Meta’s profiling orchestrator.
- Strobelight combines a number of applied sciences, many open supply, right into a single service that helps engineers at Meta enhance effectivity and utilization throughout our fleet.
- Utilizing Strobelight, we’ve seen vital effectivity wins, together with one which has resulted in an estimated 15,000 servers’ price of annual capability financial savings.
Strobelight, Meta’s profiling orchestrator, will not be actually one expertise. It’s a number of (many open supply) mixed to make one thing that unlocks really superb effectivity wins. Strobelight can be not a single profiler however an orchestrator of many various profilers (even ad-hoc ones) that runs on all manufacturing hosts at Meta, amassing detailed details about CPU utilization, reminiscence allocations, and different efficiency metrics from working processes. Engineers and builders can use this info to determine efficiency and useful resource bottlenecks, optimize their code, and enhance utilization.
Whenever you mix proficient engineers with wealthy efficiency information you will get effectivity wins by each creating tooling to determine points earlier than they attain manufacturing and discovering alternatives in already working code. Let’s say an engineer makes a code change that introduces an unintended copy of some massive object on a service’s essential path. Meta’s present instruments can determine the problem and question Strobelight information to estimate the affect on compute value. Then Meta’s code overview instrument can notify the engineer that they’re about to waste, say, 20,000 servers.
In fact, static evaluation instruments can choose up on these kinds of points, however they’re unaware of worldwide compute value and oftentimes these inefficiencies aren’t an issue till they’re regularly serving hundreds of thousands of requests per minute. The frog can boil slowly.
Why can we use profilers?
Profilers function by sampling information to carry out statistical evaluation. For instance, a profiler takes a pattern each N occasions (or milliseconds within the case of time profilers) to know the place that occasion happens or what is occurring for the time being of that occasion. With a CPU-cycles occasion, for instance, the profile might be CPU time spent in capabilities or perform name stacks executing on the CPU. This may give an engineer a high-level understanding of the code execution of a service or binary.
Selecting your personal journey with Strobelight
There are different daemons at Meta that accumulate observability metrics, however Strobelight’s wheelhouse is software program profiling. It connects useful resource utilization to supply code (what builders perceive greatest). Strobelight’s profilers are sometimes, however not completely, constructed utilizing eBPF, which is a Linux kernel expertise. eBPF permits the protected injection of customized code into the kernel, which allows very low overhead assortment of several types of information and unlocks so many prospects within the observability area that it’s onerous to think about how Strobelight would work with out it.
As of the time of penning this, Strobelight has 42 totally different profilers, together with:
- Reminiscence profilers powered by jemalloc.
- Operate name depend profilers.
- Occasion-based profilers for each native and non-native languages (e.g., Python, Java, and Erlang).
- AI/GPU profilers.
- Profilers that observe off-CPU time.
- Profilers that observe service request latency.
Engineers can make the most of any one among these to gather information from servers on demand through Strobelight’s command line instrument or internet UI.
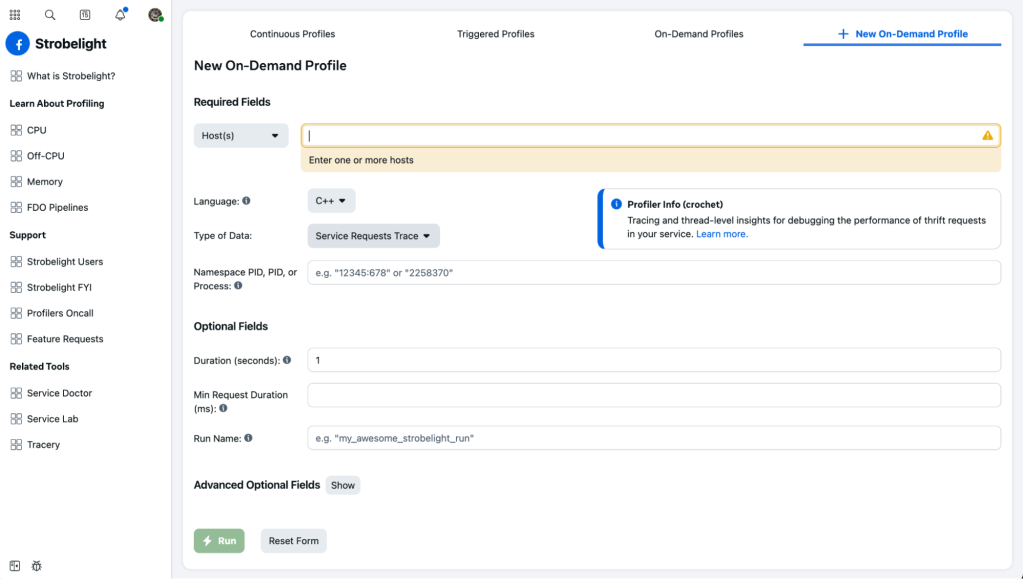
Customers even have the flexibility to arrange steady or “triggered” profiling for any of those profilers by updating a configuration file in Meta’s Configerator, permitting them to focus on their complete service or, for instance, solely hosts that run in sure areas. Customers can specify how usually these profilers ought to run, the run period, the symbolization technique, the method they need to goal, and much more.
Right here is an instance of a easy configuration for one among these profilers:
add_continuous_override_for_offcpu_data(
"my_awesome_team", // the workforce that owns this service
Kind.SERVICE_ID,
"my_awseome_service",
30_000, // desired samples per hour
)
Why does Strobelight have so many profilers? As a result of there are such a lot of various things occurring in these programs powered by so many various applied sciences.
That is additionally why Strobelight gives ad-hoc profilers. For the reason that type of information that may be gathered from a binary is so diversified, engineers usually want one thing that Strobelight doesn’t present out of the field. Including a brand new profiler from scratch to Strobelight entails a number of code adjustments and will take a number of weeks to get reviewed and rolled out.
Nonetheless, engineers can write a single bpftrace script (a easy language/instrument that means that you can simply write eBPF applications) and inform Strobelight to run it like it could another profiler. An engineer that basically cares in regards to the latency of a specific C++ perform, for instance, might write up a bit bpftrace script, commit it, and have Strobelight run it on any variety of hosts all through Meta’s fleet – all inside a matter of hours, if wanted.
If all of this sounds powerfully harmful, that’s as a result of it’s. Nonetheless, Strobelight has a number of safeguards in place to forestall customers from inflicting efficiency degradation for the focused workloads and retention points for the databases Strobelight writes to. Strobelight additionally has sufficient consciousness to make sure that totally different profilers don’t battle with one another. For instance, if a profiler is monitoring CPU cycles, Strobelight ensures one other profiler can’t use one other PMU counter on the identical time (as there are different companies that additionally use them).
Strobelight additionally has concurrency guidelines and a profiler queuing system. In fact, service homeowners nonetheless have the pliability to essentially hammer their machines in the event that they need to extract quite a lot of information to debug.
Default information for everybody
Since its inception, one among Strobelight’s core rules has been to supply computerized, regularly-collected profiling information for all of Meta’s companies. It’s like a flight recorder – one thing that doesn’t need to be considered till it’s wanted. What’s worse than waking as much as an alert {that a} service is unhealthy and there’s no information as to why?
For that cause, Strobelight has a handful of curated profilers which might be configured to run robotically on each Meta host. They’re not working on a regular basis; that may be “dangerous” and probably not “profiling.” As an alternative, they’ve customized run intervals and sampling charges particular to the workloads working on the host. This gives simply the correct amount of knowledge with out impacting the profiled companies or overburdening the programs that retailer Strobelight information.
Right here is an instance:
A service, named Smooth Server, runs on 1,000 hosts and let’s say we would like profiler A to assemble 40,000 CPU-cycles samples per hour for this service (keep in mind the config above). Strobelight, understanding what number of hosts Smooth Server runs on, however not how CPU intensive it’s, will begin with a conservative run chance, which is a sampling mechanism to forestall bias (e.g., profiling these hosts at midday every single day would conceal visitors patterns).
The following day Strobelight will have a look at what number of samples it was in a position to collect for this service after which robotically tune the run chance (with some quite simple math) to attempt to hit 40,000 samples per hour. We name this dynamic sampling and Strobelight does this readjustment every single day for each service at Meta.
And if there’s multiple service working on the host (excluding daemons like systemd or Strobelight) then Strobelight will default to utilizing the configuration that may yield extra samples for each.
Grasp on, grasp on. If the run chance or sampling fee is totally different relying on the host for a service, then how can the information be aggregated or in contrast throughout the hosts? And the way can profiling information for a number of companies be in contrast?
Since Strobelight is conscious of all these totally different knobs for profile tuning, it adjusts the “weight” of a profile pattern when it’s logged. A pattern’s weight is used to normalize the information and forestall bias when analyzing or viewing this information in combination. So even when Strobelight is profiling Smooth Server much less usually on one host than on one other, the samples will be precisely in contrast and grouped. This additionally works for evaluating two totally different companies since Strobelight is used each by service homeowners taking a look at their particular service in addition to effectivity specialists who search for “horizontal” wins throughout the fleet in shared libraries.
How Strobelight saves capability
There are two default steady profilers that ought to be known as out due to how a lot they find yourself saving in capability.
The final department report (LBR) profiler
The LBR profiler, true to its title, is used to pattern last branch records (a {hardware} characteristic that began on Intel). The info from this profiler doesn’t get visualized however as a substitute is fed into Meta’s suggestions directed optimization (FDO) pipeline. This information is used to create FDO profiles which might be consumed at compile time (CSSPGO) and post-compile time (BOLT) to hurry up binaries via the added data of runtime conduct. Meta’s prime 200 largest companies all have FDO profiles from the LBR information gathered repeatedly throughout the fleet. A few of these companies see as much as 20% discount in CPU cycles, which equates to a 10-20% discount within the variety of servers wanted to run these companies at Meta.
The occasion profiler
The second profiler is Strobelight’s occasion profiler. That is Strobelight’s model of the Linux perf instrument. Its main job is to gather person and kernel stack traces from a number of efficiency (perf) occasions e.g., CPU-cycles, L3 cache misses, directions, and so on. Not solely is that this information checked out by particular person engineers to know what the most well liked capabilities and name paths are, however this information can be fed into monitoring and testing instruments to determine regressions; ideally earlier than they hit manufacturing.
Did somebody say Meta…information?
perform name stacks with flame graphs is nice, nothing in opposition to it. However a service proprietor taking a look at name stacks from their service, which imports many libraries and makes use of Meta’s software program frameworks, will see quite a lot of “international” capabilities. Additionally, what about discovering simply the stacks for p99 latency requests? Or how about all of the locations the place a service is making an unintended string copy?
Stack schemas
Strobelight has a number of mechanisms for enhancing the information it produces in keeping with the wants of its customers. One such mechanism is named Stack Schemas (impressed by Microsoft’s stack tags), which is a small DSL that operates on name stacks and can be utilized so as to add tags (strings) to complete name stacks or particular person frames/capabilities. These tags can then be utilized in our visualization instrument. Stack Schemas can even take away capabilities customers don’t care about with regex matching. Any variety of schemas will be utilized on a per-service and even per-profile foundation to customise the information.
There are even of us who create dashboards from this metadata to assist different engineers determine costly copying, use of inefficient or inappropriate C++ containers, overuse of good pointers, and way more. Static evaluation instruments that may do that have been round for a very long time, however they will’t pinpoint the actually painful or computationally costly situations of those points throughout a big fleet of machines.
Strobemeta
Strobemeta is one other mechanism, which makes use of thread native storage, to connect bits of dynamic metadata at runtime to name stacks that we collect within the occasion profiler (and others). This is likely one of the largest benefits of constructing profilers utilizing eBPF: complicated and customised actions taken at pattern time. Collected Strobemeta is used to attribute name stacks to particular service endpoints, or request latency metrics, or request identifiers. Once more, this permits engineers and instruments to do extra complicated filtering to focus the huge quantities of knowledge that Strobelight profilers produce.
Symbolization
Now is an efficient time to speak about symbolization: taking the digital deal with of an instruction, changing it into an precise image (perform) title, and, relying on the symbolization technique, additionally getting the perform’s supply file, line quantity, and sort info.
More often than not getting the entire enchilada means utilizing a binary’s DWARF debug information. However this may be many megabytes (and even gigabytes) in dimension as a result of DWARF debug information comprises way more than the image info.
This information must be downloaded then parsed. However making an attempt this whereas profiling, and even afterwards on the identical host the place the profile is gathered, is much too computationally costly. Even with optimum caching methods it might trigger reminiscence points for the host’s workloads.
Strobelight will get round this drawback through a symbolization service that makes use of a number of open supply applied sciences together with DWARF, ELF, gsym, and blazesym. On the finish of a profile Strobelight sends stacks of binary addresses to a service that sends again symbolized stacks with file, line, kind information, and even inline info.
It may possibly do that as a result of it has already carried out all of the heavy lifting of downloading and parsing the DWARF information for every of Meta’s binaries (particularly, manufacturing binaries) and shops what it wants in a database. Then it might serve a number of symbolization requests coming from totally different situations of Strobelight working all through the fleet.
So as to add to that enchilada (hungry but?), Strobelight additionally delays symbolization till after profiling and shops uncooked information to disk to forestall reminiscence thrash on the host. This has the additional benefit of not letting the buyer affect the producer – that means if Strobelight’s person area code can’t deal with the velocity at which the eBPF kernel code is producing samples (as a result of it’s spending time symbolizing or doing another processing) it ends in dropped samples.
All of that is made attainable with the inclusion of frame pointers in all of Meta’s person area binaries, in any other case we couldn’t stroll the stack to get all these addresses (or we’d need to do another sophisticated/costly factor which wouldn’t be as environment friendly).

Present me the information (and make it good)!
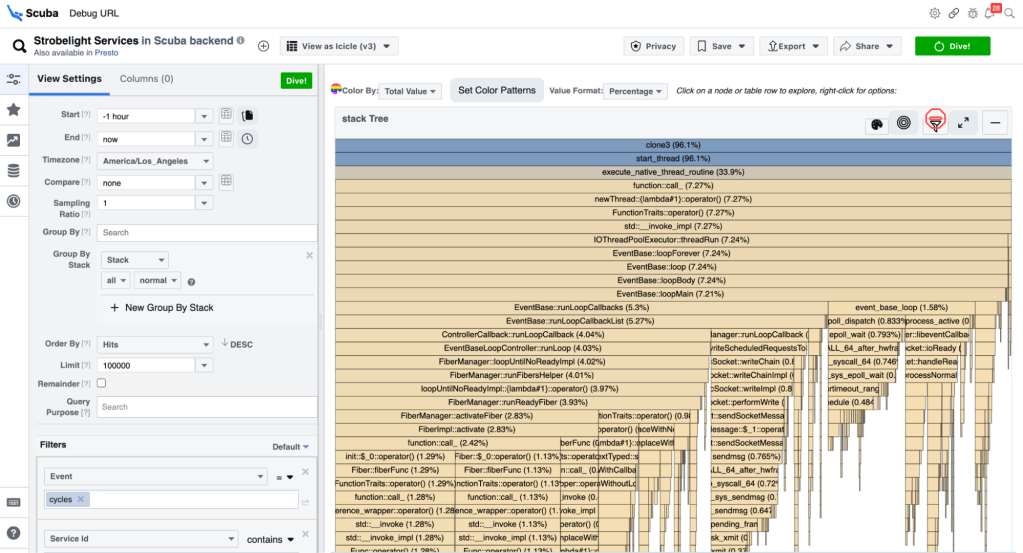
The first instrument Strobelight prospects use is Scuba – a question language (like SQL), database, and UI. The Scuba UI has a big suite of visualizations for the queries folks assemble (e.g., flame graphs, pie charts, time sequence graphs, distributions, and so on).
Strobelight, for essentially the most half, produces Scuba information and, usually, it’s a contented marriage. If somebody runs an on-demand profile, it’s only a few seconds earlier than they will visualize this information within the Scuba UI (and ship folks hyperlinks to it). Even instruments like Perfetto expose the flexibility to question the underlying information as a result of they comprehend it’s inconceivable to attempt to give you sufficient dropdowns and buttons that may specific every thing you need to do in a question language – although the Scuba UI comes shut.
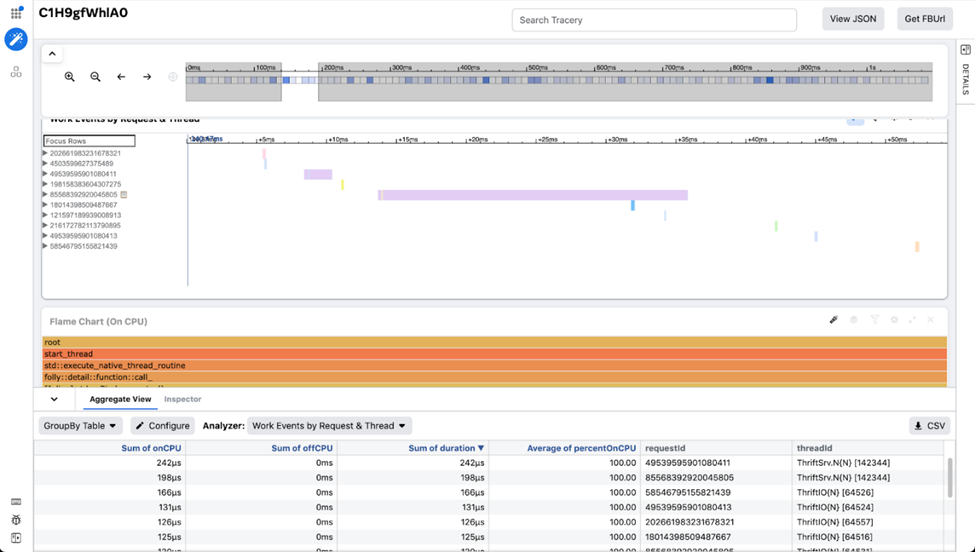
The opposite instrument is a hint visualization instrument used at Meta named Tracery. We use this instrument after we need to mix correlated however totally different streams of profile information on one display screen. This information can be a pure match for viewing on a timeline. Tracery permits customers to make customized visualizations and curated workspaces to share with different engineers to pinpoint the vital components of that information. It’s additionally powered by a client-side columnar database (written in JavaScript!), which makes it very quick with regards to zooming and filtering. Strobelight’s Crochet profiler combines service request spans, CPU-cycles stacks, and off-CPU information to present customers an in depth snapshot of their service.
The Largest Ampersand
Strobelight has helped engineers at Meta notice numerous effectivity and latency wins, starting from will increase within the variety of requests served, to massive reductions in heap allocations, to regressions caught in pre-prod evaluation instruments.
However one of the vital wins is one we name, “The Largest Ampersand.”
A seasoned efficiency engineer was trying via Strobelight information and found that by filtering on a specific std::vector perform name (utilizing the symbolized file and line quantity) he might determine computationally costly array copies that occur unintentionally with the ‘auto’ key phrase in C++.
The engineer turned a couple of knobs, adjusted his Scuba question, and occurred to note one among these copies in a very sizzling name path in one among Meta’s largest adverts companies. He then cracked open his code editor to research whether or not this explicit vector copy was intentional… it wasn’t.
It was a easy mistake that any engineer working in C++ has made 100 instances.
So, the engineer typed an “&” in entrance of the auto key phrase to point we would like a reference as a substitute of a replica. It was a one-character commit, which, after it was shipped to manufacturing, equated to an estimated 15,000 servers in capability financial savings per 12 months!
Return and re-read that sentence. One ampersand!
An open ending
This solely scratches the floor of every thing Strobelight can do. The Strobelight workforce works intently with Meta’s efficiency engineers on new options that may higher analyze code to assist pinpoint the place issues are sluggish, computationally costly, and why.
We’re at the moment engaged on open-sourcing Strobelight’s profilers and libraries, which is able to little doubt make them extra strong and helpful. A lot of the applied sciences Strobelight makes use of are already public or open supply, so please use and contribute to them!
Acknowledgements
Particular due to Wenlei He, Andrii Nakryiko, Giuseppe Ottaviano, Mark Santaniello, Nathan Slingerland, Anita Zhang, and the Profilers Crew at Meta.











{kind=link}