
Massive language fashions (LLMs) like Gemma are highly effective and versatile. They will translate languages, write totally different sorts of textual content content material, and reply your questions in an informative manner. Nonetheless, deploying these LLMs to manufacturing, particularly for streaming use instances, is usually a important problem.
This weblog submit will discover learn how to use two state-of-the-art instruments, vLLM and Dataflow, to effectively deploy LLMs at scale with minimal code. First, we are going to lay out how vLLM makes use of steady batching to serve LLMs extra effectively. Second, we are going to describe how Dataflow’s mannequin supervisor makes deploying vLLM and different giant mannequin frameworks easy.
What’s vLLM?
vLLM is an open-source library particularly designed for high-throughput and low-latency LLM inference. It optimizes the serving of LLMs by using a number of specialised strategies, together with steady batching.
To grasp how steady batching works, let’s first have a look at how fashions historically batch inputs. GPUs excel at parallel processing, the place a number of computations are carried out concurrently. Batching permits the GPU to make the most of all of its obtainable cores to work on a whole batch of information directly, relatively than processing every enter individually. This considerably quickens the inference course of; typically, performing inference on 8 enter data directly makes use of comparable assets as performing inference on a single file.
You possibly can consider batching as being much like a restaurant kitchen: as an alternative of getting ready every dish individually, the chef can group comparable orders and prepare dinner them collectively, saving time and assets. When you have 8 stovetops, it takes an identical quantity of effort and time to make both a single omelet or 8 omelets.
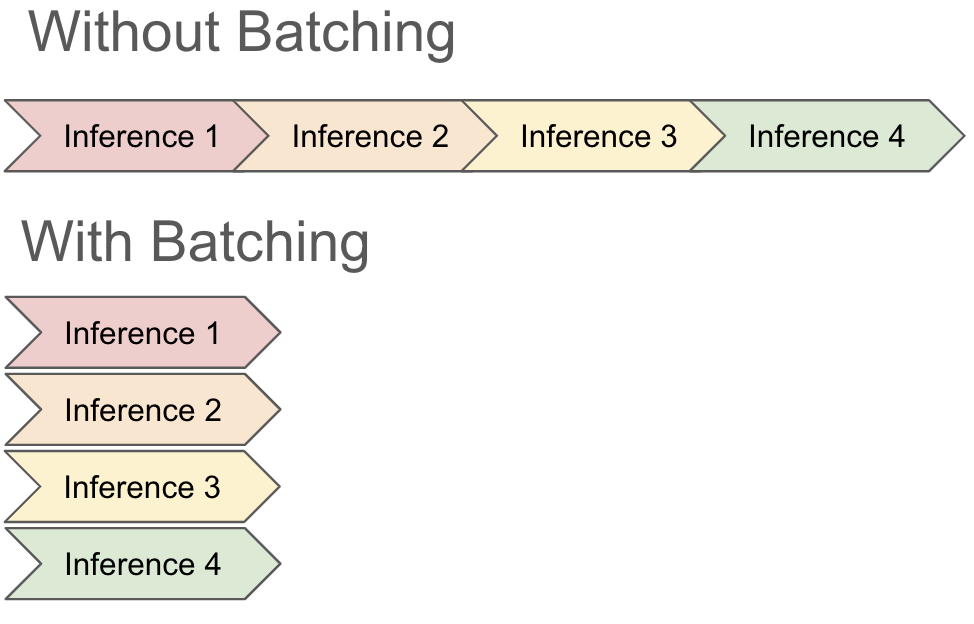
There are some downsides, nonetheless, to conventional batching. Most significantly on this context, batching doesn’t work as effectively when it takes totally different quantities of time to carry out inference. Since most frameworks do not have entry to or data concerning the underlying mechanisms for performing inference, they usually simply watch for all requests to finish earlier than taking up a brand new batch. Which means that a single sluggish file can eat all of a GPUs capability even when the opposite data within the batch have accomplished, resulting in slower and extra expensive jobs.

When working inference with a Massive Language Mannequin (LLM), ready for a complete batch to finish may be prohibitively sluggish and costly. It is because the period of time it takes to generate an inference for a file has a 1:1 correlation to the size of the file. For instance, think about that we batch the next 2 requests to an LLM:
- What’s the capital of Mexico?
2. What are among the cultural variations and similarities between Mexico and the USA?
We would anticipate a brief reply to query (1) and an extended reply to query (2). As a result of it takes for much longer to reply query (2), although, now we have to attend for that query to finish whereas it monopolizes our GPU earlier than we will return any of the outcomes from the batch.

Steady batching permits vLLM to replace batches whereas the request continues to be working. It achieves this by leveraging how LLMs carry out inference: a looping strategy of repeatedly producing the following token of their response. So actually, when producing the sentence “The capital of Mexico is Mexico Metropolis”, we’re working inference 7 occasions (as soon as per output phrase). Quite than batching inputs as soon as, vLLM’s steady batching approach permits it to recompute a batch each time the LLM runs generates a set of tokens for a batch. It will probably add requests to the batch on the fly and return early outcomes when one file from a batch is totally achieved.

vLLM’s dynamic batching and different optimizations have been proven to enhance inference throughput by 2-4x for widespread LLMs in some instances, making it a really great tool for mannequin serving. For extra details about vLLM, take a look at this white paper.
Utilizing vLLM in Dataflow
Deploying a vLLM occasion inside a streaming pipeline may be complicated. Historically, you would wish to:
- Spin up a single vLLM server in the midst of your pipeline. That is typically not trivial since most streaming programs spin up a number of employee processes, so that you must elect a frontrunner to spin up a devoted vLLM course of.
- Guarantee all employee processes can talk with that singleton server.
- Monitor and productionize the service in order that it’s tolerant to vLLM server failures.
This includes a whole lot of multiprocessing, which may be time-consuming, error-prone, and requires specialised experience. It additionally requires a deep understanding of the underlying topology. This topology can typically change if you wish to strive totally different machine configurations as effectively (for instance to check efficiency on an 8 core machine and a 16 core machine).
Luckily, Dataflow simplifies this course of with its model manager. This function abstracts away the complexities of managing and deploying fashions inside a pipeline. By default, Dataflow provisions one employee course of per obtainable core on its employee machines. These processes are answerable for dealing with I/O into and out of the employee in addition to any transformations that are carried out on the information, and so they function completely independently. For many pipelines, together with knowledge prep pipelines for ML use instances, that is the optimum topology.
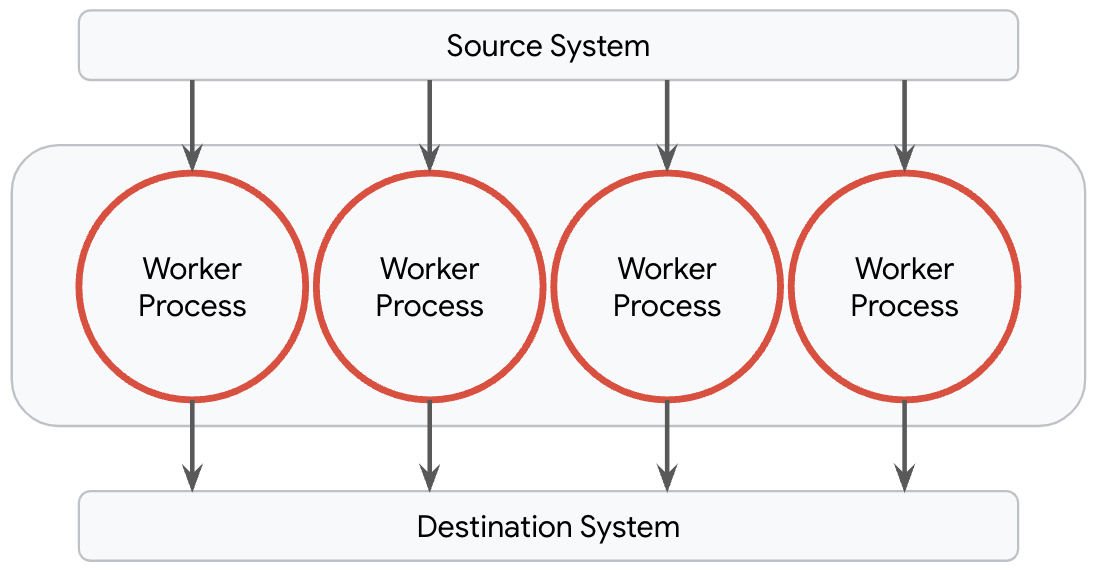
This breaks down, nonetheless, for pipelines which have to serve giant fashions like one of many Gemma fashions. It’s neither price environment friendly nor performant to load a duplicate of huge fashions into each course of as a result of pipelines will most certainly run into out of reminiscence points. The best topology for many such pipelines is to load solely a single copy of the massive mannequin.
Dataflow’s mannequin supervisor was constructed to permit customers to manage the exact number of copies of a mannequin that are deployed of their pipeline, no matter community topology. If you apply the RunInference rework, Dataflow is ready to perceive your intent in order that it could possibly create the best topology in your pipeline and deploy the optimum variety of fashions. All that you must do is provide some configuration parameters.
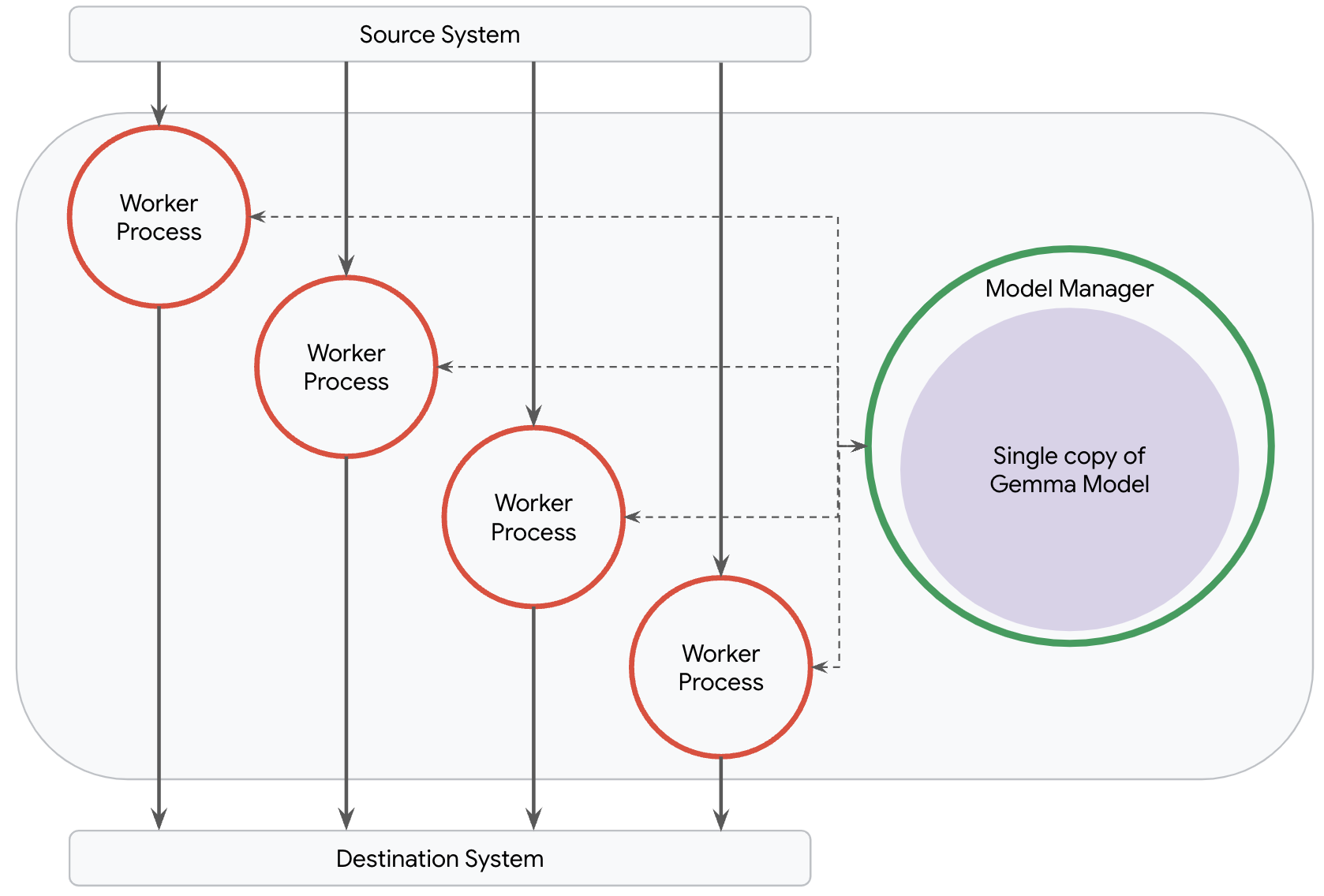
When utilizing vLLM, as an alternative of loading a mannequin, Dataflow’s mannequin supervisor spins up a single vLLM occasion in a devoted inference course of. Employee processes can then effectively ship data to this occasion for inference.
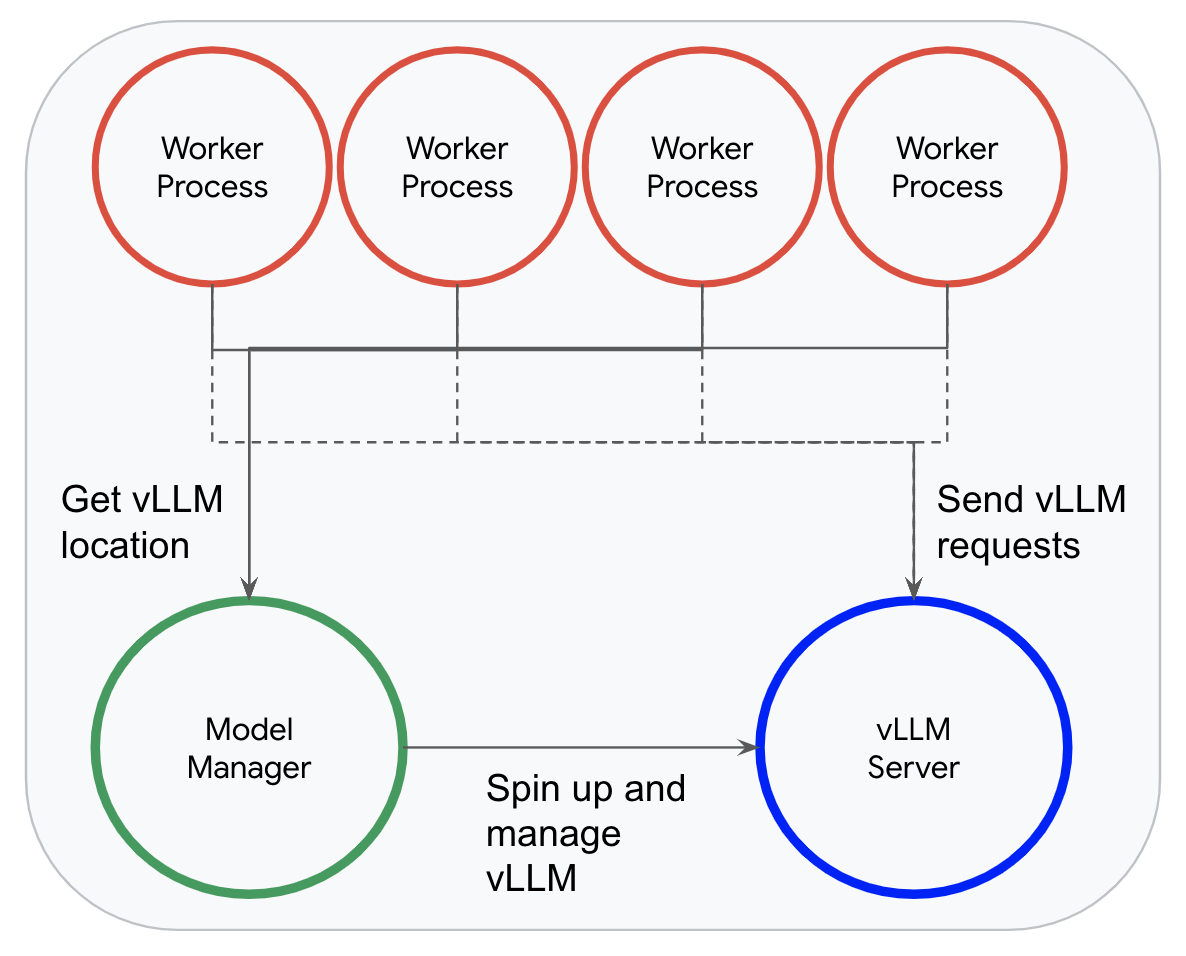
This mannequin supervisor permits Dataflow to totally benefit from vLLM’s steady batching; when a employee receives an incoming request, it asynchronously appends it to vLLMs queue of requests and waits for the response, permitting vLLM to dynamically batch as many requests because it is ready to.
Dataflow’s mannequin supervisor and RunInference rework make it extremely simple to include vLLM into your pipeline. You solely have to specify some configuration particulars and some strains of code. As a result of Dataflow is ready to perceive your underlying intent, it configures the entire remainder of the pipeline topology for you. In 5 strains of code, you may write a full finish to finish pipeline to learn your knowledge, run it by vLLM, and output it to a sink.
model_handler = VLLMCompletionsModelHandler('google/gemma-2b')
with beam.Pipeline() as p:
_ = (p | beam.ReadFromSource(<config>)
| RunInference(model_handler) # Ship the prompts to vLLM and get responses.
| beam.WriteToSink(<config>))
Yow will discover a whole pipeline and run it your self right here: https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm
Efficiency
vLLM considerably boosts the efficiency of LLM inference in Dataflow pipelines. To match vLLM’s efficiency towards a naive pipeline utilizing fastened measurement batches, we ran 2 pipelines with a single employee with T4 GPUs. Every pipeline learn in prompts from the P3 dataset, ran them towards the google/gemma-2b mannequin, and logged the end result.
When utilizing a naive (default) batching technique, it took 59.137 vCPU hours to course of 10,000 prompts. When utilizing vLLM with steady batching, it took solely 2.481 vCPU hours to course of the identical 10,000 prompts. That’s an over 23x enchancment!
There are some caveats right here: particularly, no tuning was achieved on both pipeline, and the naive pipeline doubtless would’ve carried out considerably higher if tuned to make use of bigger or extra uniform batches. With that mentioned, that’s a part of the magic of vLLM; with lower than 20 strains of code and no tuning work, we’re in a position to produce a extremely performant LLM serving pipeline! If we needed to check one other mannequin, we may accomplish that in a performant method by altering a single string in our mannequin handler!
Subsequent Steps
By combining the ability of vLLM and Dataflow, you may effectively deploy and scale LLMs in your streaming purposes with ease. To be taught extra about how you are able to do this, strive working by this instance pocket book: https://cloud.google.com/dataflow/docs/notebooks/run_inference_vllm.
To be taught extra about Gemma fashions and among the issues you are able to do with them, take a look at the Gemma docs: https://ai.google.dev/gemma/docs
To be taught extra about vLLM and among the different mechanisms it makes use of to optimize serving, go to the vLLM docs: https://docs.vllm.ai/en/latest/











{kind=link}