- We’re introducing parameter vulnerability factor (PVF), a novel metric for understanding and measuring AI programs’ vulnerability towards silent information corruptions (SDCs) in mannequin parameters.
- PVF could be tailor-made to completely different AI fashions and duties, tailored to completely different {hardware} faults, and even prolonged to the coaching section of AI fashions.
- We’re sharing outcomes of our personal case research utilizing PVF to measure the affect of SDCs in mannequin parameters, in addition to potential strategies of figuring out SDCs in mannequin parameters.
Reliability is a vital facet of any profitable AI implementation. However the rising complexity and variety of AI {hardware} programs additionally brings an elevated danger of {hardware} faults equivalent to bit flips. Manufacturing defects, ageing elements, or environmental components can result in information corruptions – errors or alterations in information that may happen throughout storage, transmission, or processing and end in unintended adjustments in info.
Silent data corruptions (SDCs), the place an undetected {hardware} fault ends in misguided software conduct, have turn out to be more and more prevalent and troublesome to detect. Inside AI programs, an SDC can create what’s known as parameter corruption, the place AI mannequin parameters are corrupted and their authentic values are altered.
When this happens throughout AI inference/servicing it might probably result in incorrect or degraded mannequin output for customers, in the end affecting the standard and reliability of AI providers.
Determine 1 reveals an instance of this, the place a single bit flip can drastically alter the output of a ResNet mannequin.

With this escalating thread in thoughts, there are two essential questions: How susceptible are AI fashions to parameter corruptions? And the way do completely different elements (equivalent to modules and layers) of the fashions exhibit completely different vulnerability ranges to parameter corruptions?
Answering these questions is a vital a part of delivering dependable AI programs and providers and presents beneficial insights for guiding AI {hardware} system design, equivalent to when assigning AI mannequin parameters or software program variables to {hardware} blocks with differing fault safety capabilities. Moreover, it might present essential info for formulating methods to detect and mitigate SDCs in AI programs in an environment friendly and efficient method.
Parameter vulnerability factor (PVF) is a novel metric we’ve launched with the purpose to standardize the quantification of AI mannequin vulnerability towards parameter corruptions. PVF is a flexible metric that may be tailor-made to completely different AI fashions/duties and can be adaptable to completely different {hardware} fault fashions. Moreover, PVF could be prolonged to the coaching section to guage the results of parameter corruptions on the mannequin’s convergence functionality.
What’s PVF?
PVF is impressed by the architectural vulnerability issue (AVF) metric used throughout the laptop structure neighborhood. We outline a mannequin parameter’s PVF because the chance {that a} corruption in that particular mannequin parameter will result in an incorrect output. Just like AVF, this statistical idea could be derived from statistically in depth and significant fault injection (FI) experiments.
PVF has a number of options:
Parameter-level quantitative evaluation
As a quantitative metric, PVF concentrates on parameter-level vulnerability, calculating the chance {that a} corruption in a selected mannequin parameter will result in an incorrect mannequin output. This “parameter” could be outlined at completely different scales and granularities, equivalent to a person parameter or a gaggle of parameters.
Scalability throughout AI fashions/duties
PVF is scalable and relevant throughout a variety of AI fashions, duties, and {hardware} fault fashions.
Offers insights for guiding AI system design
PVF can present beneficial insights for AI system designers, guiding them in making knowledgeable choices about balancing fault safety with efficiency and effectivity. For instance, engineers may leverage PVF to assist map greater susceptible parameters to better-protected {hardware} blocks and discover tradeoffs on latency, energy, and reliability by enabling a surgical strategy to fault tolerance at selective areas as a substitute of a catch-all/none strategy.
Can be utilized as a typical metric for AI vulnerability/resilience analysis
PVF has the potential to unify and standardize such practices, making it simpler to match the reliability of various AI programs/parameters and fostering open collaboration and progress within the business and analysis neighborhood.
How PVF works
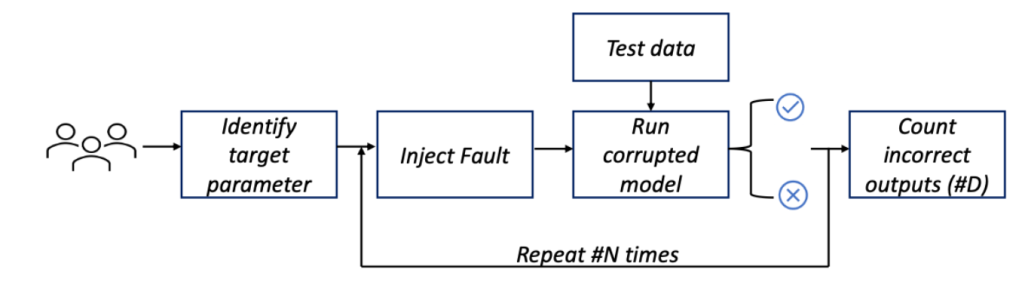
Just like AVF as a statistical idea, PVF must be derived by means of a lot of FI experiments which might be statistically significant. Determine 2 reveals an total movement to compute PVF by means of a FI course of. We’ve introduced a case research on the open-source DLRM inference with extra particulars and instance case research in our paper.
Determine 3 illustrates the PVF of three DLRM parameter elements, embedding desk, bot-MLP, and top-MLP, beneath 1, 2, 4, 8, 16, 32, 64, and 128 bit flips throughout every inference. We observe completely different vulnerability ranges throughout completely different elements of DLRM. For instance, beneath a single bit flip, the embedding desk has comparatively low PVF; that is attributed to embedding tables being extremely sparse, and parameter corruptions are solely activated when the actual corrupted parameter is activated by the corresponding sparse characteristic. Nevertheless, top-MLP can have 0.4% beneath even a single bit flip. That is important – for each 1000 inferences, 4 inferences might be incorrect. This highlights the significance of defending particular susceptible parameters for a given mannequin based mostly on the PVF measurement.
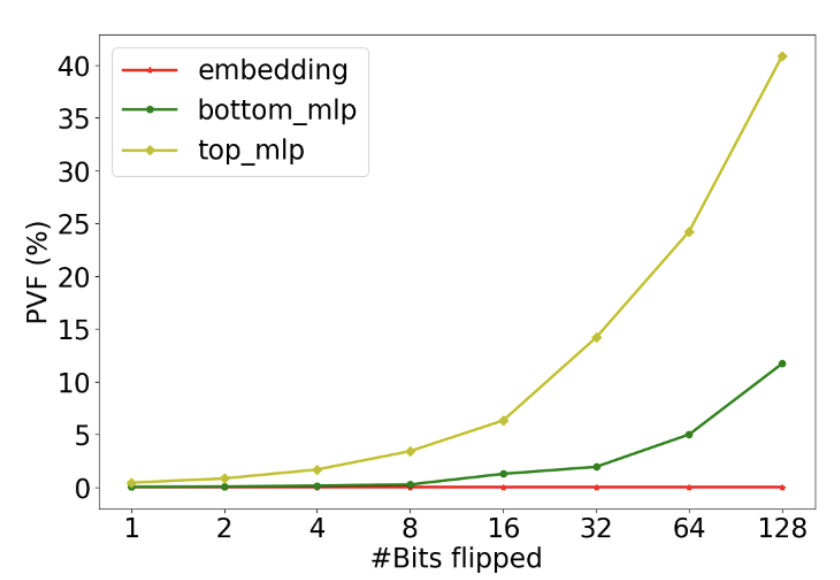
We observe that with 128 bit flips throughout every inference, for MLP elements, PVF has elevated to 40% and 10% for top-MLP and bot-MLP elements respectively, whereas observing a number of NaN values. High-MLP part has greater PVF than bot-MLP. That is attributed to the top-MLP being nearer to the ultimate mannequin, and therefore has much less of an opportunity to be mitigated by inherent error masking chance of neural layers.
The applicability of PVF
PVF is a flexible metric the place the definition of an “incorrect output” (which can fluctuate based mostly on the mannequin/process) could be tailored to go well with person necessities. To adapt PVF to varied {hardware} fault fashions the tactic to calculate PVF stays constant as depicted in Determine 2. The one modification required is the way during which the fault is injected, based mostly on the assumed fault fashions.
Moreover, PVF could be prolonged to the coaching section to guage the results of parameter corruptions on the mannequin’s convergence functionality. Throughout coaching, the mannequin’s parameters are iteratively up to date to reduce a loss perform. A corruption in a parameter may probably disrupt this studying course of, stopping the mannequin from converging to an optimum answer. By making use of the PVF idea throughout coaching, we may quantify the chance {that a} corruption in every parameter would end in such a convergence failure.
Dr. DNA and additional exploration avenues for PVF
The logical development after understanding AI vulnerability to SDCs is to determine and reduce their affect on AI programs. To provoke this, we’ve launched Dr. DNA, a technique designed to detect and mitigate SDCs that happen throughout deep studying mannequin inference. Particularly, we formulate and extract a set of distinctive SDC signatures from the distribution of neuron activations (DNA), based mostly on which we suggest early-stage detection and mitigation of SDCs throughout DNN inference.
We carry out an in depth analysis throughout 10 consultant DNN fashions utilized in three widespread duties (imaginative and prescient, GenAI, and segmentation) together with ResNet, Imaginative and prescient Transformer, EfficientNet, YOLO, and so on., beneath 4 completely different error fashions. Outcomes present that Dr. DNA achieves a 100% SDC detection price for many instances, a 95% detection price on common and a >90% detection price throughout all instances, representing 20-70% enchancment over baselines. Dr. DNA can even mitigate the affect of SDCs by successfully recovering DNN mannequin efficiency with <1% reminiscence overhead and <2.5% latency overhead.
Learn the analysis papers
Dr. DNA: Combating Silent Data Corruptions in Deep Learning using Distribution of Neuron Activations











{kind=link}